
测试驿栈-由浅入深学性能 学会用 Jmeter 爬虫获取修仙秘籍!
「All right reserved, any unauthorized reproduction or transfer is prohibitted」
概述
Jmeter 可以实现网络文章的爬虫。将所有文章分类保存到本地文件中,并以文章标题命名
它原理就是对网页提交一个请求,然后把返回的所有值提取出来,利用 for 循环去实现遍历读取。下面来介绍一下如何操作
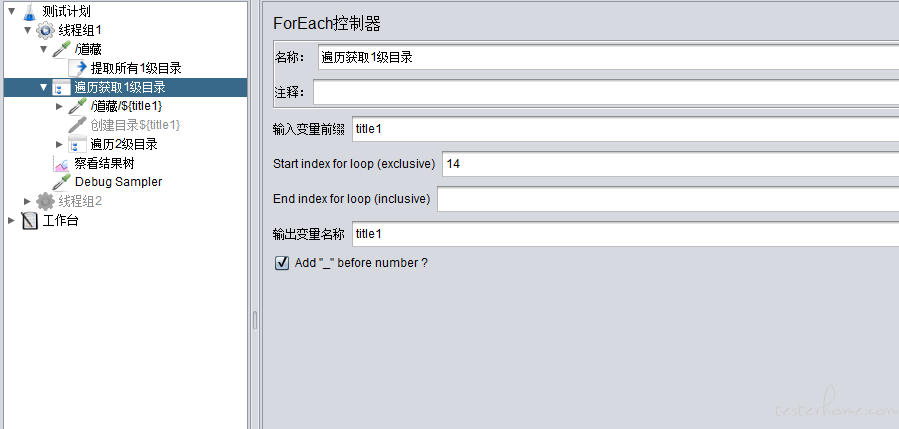
一级目录获取
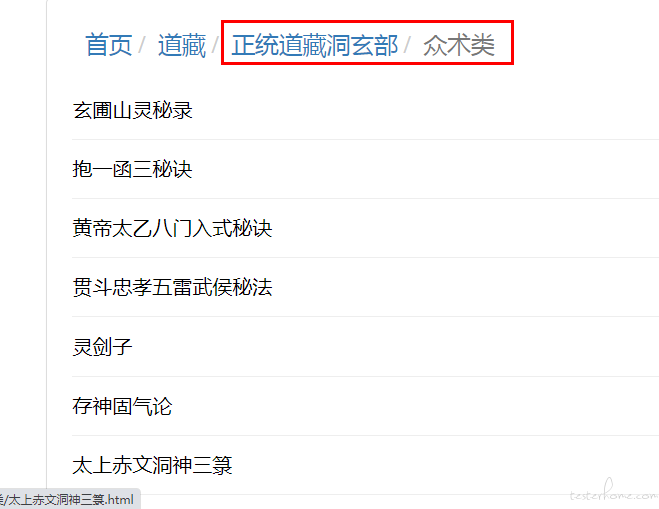
首先我们对一个站点发起请求,观察一下返回值可以发现中间有很多大标题,这些大标题都是 href 标签,他们作为超链接可以跳转到下一级子目录

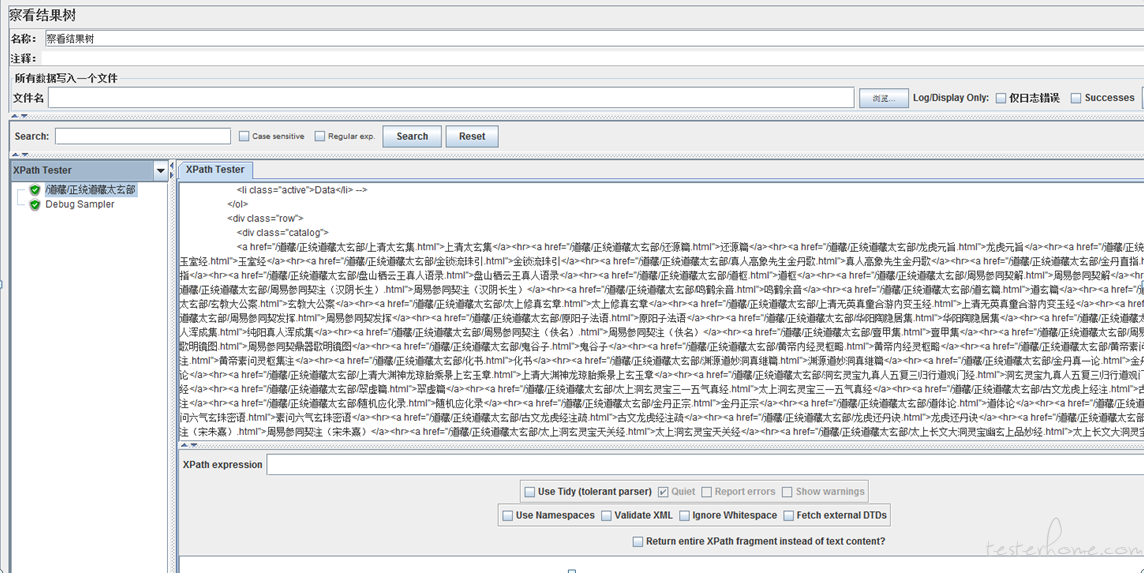
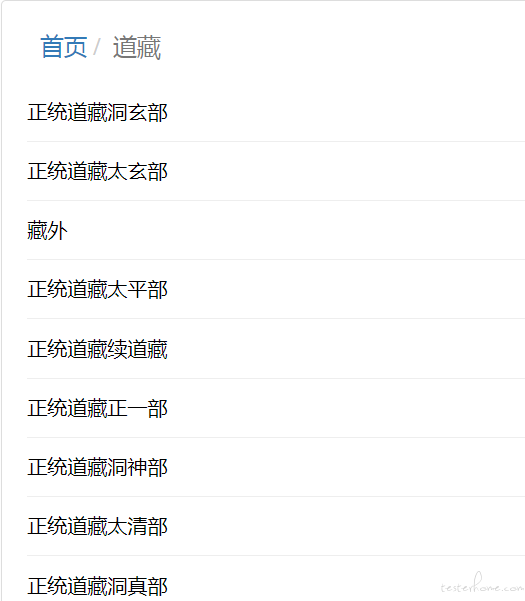
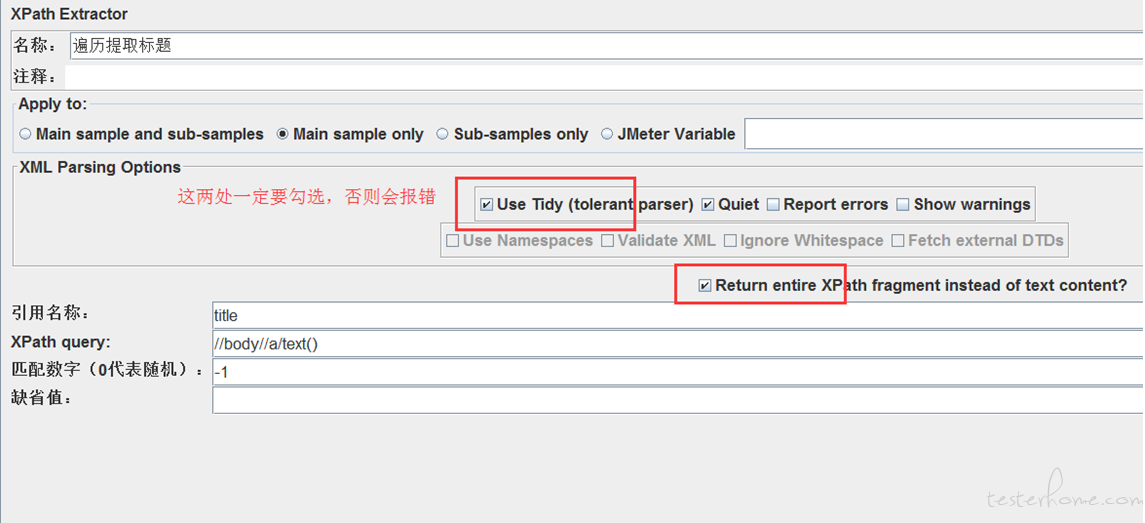
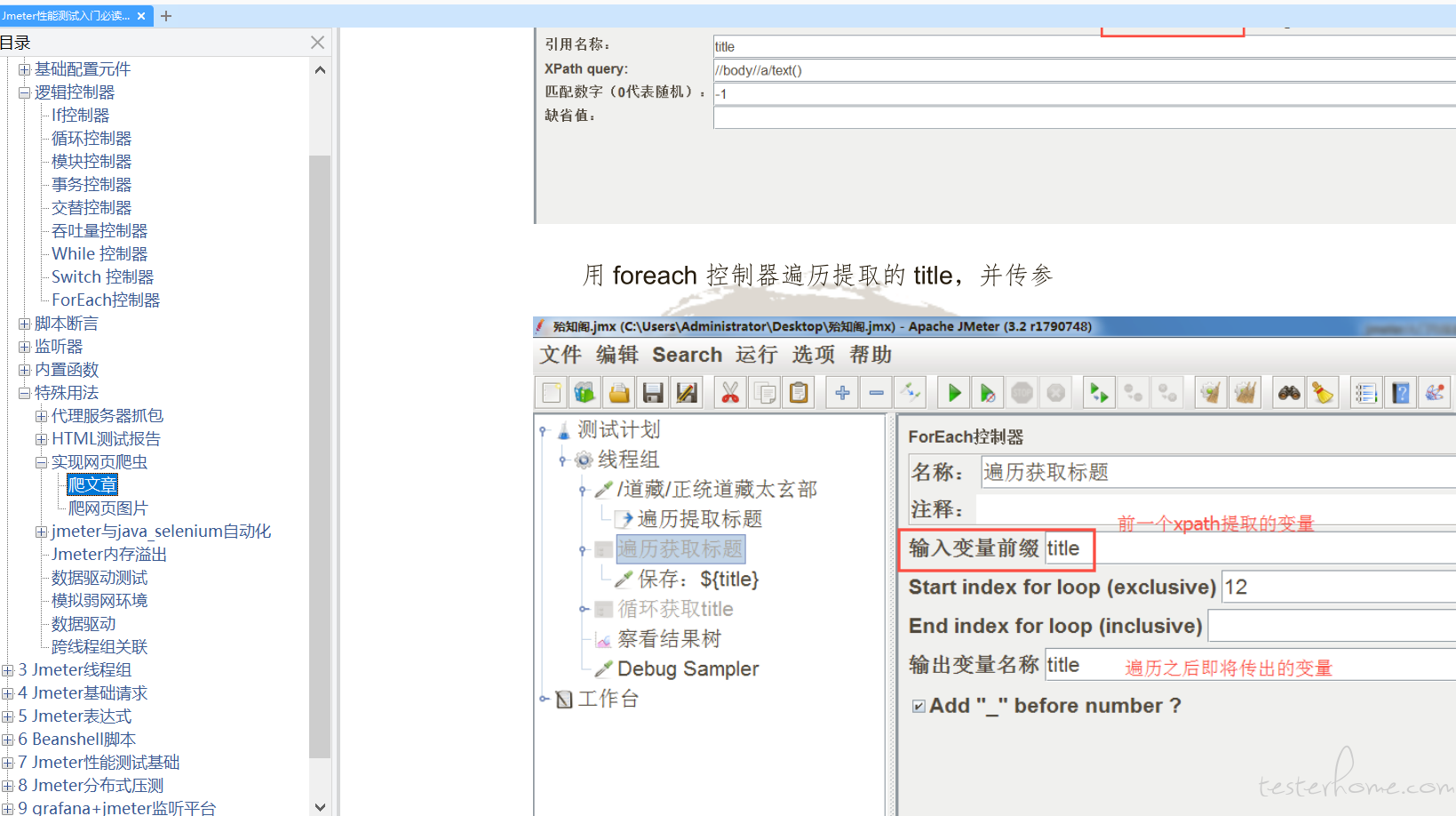
我们用 Xpath 提取器获取全部 href 标签,通过 Foreach 控制器遍历提取到的 href 标签内中文标题,并传给下一个请求,相当于对 1 级目录做了一次点击操作。
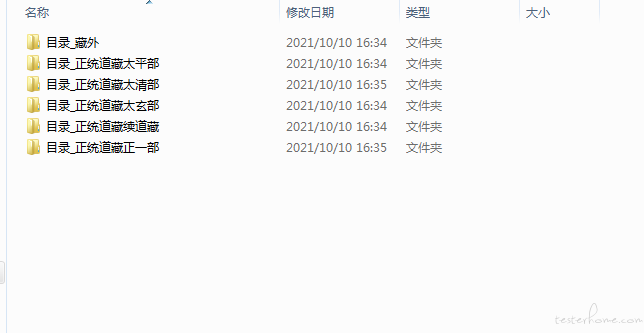
紧接着我们就进入了 2 级目录。
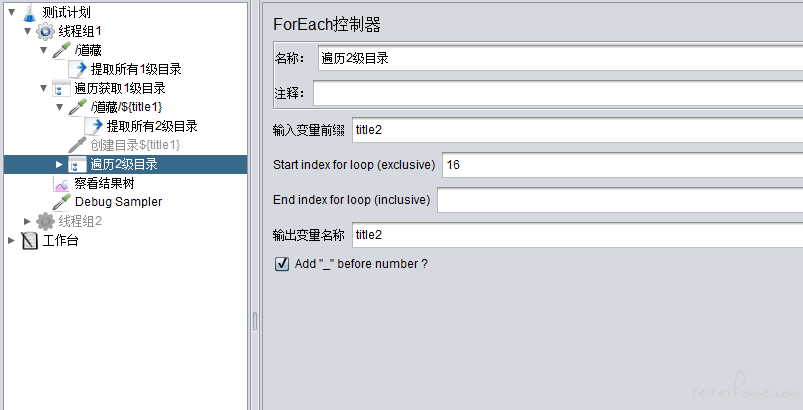
二级目录获取
在上一个 for 循环下面再套一个 for 循环,作为 2 级目录遍历。循环触发 url,相当于对所有 2 级目录做了一次点击操作
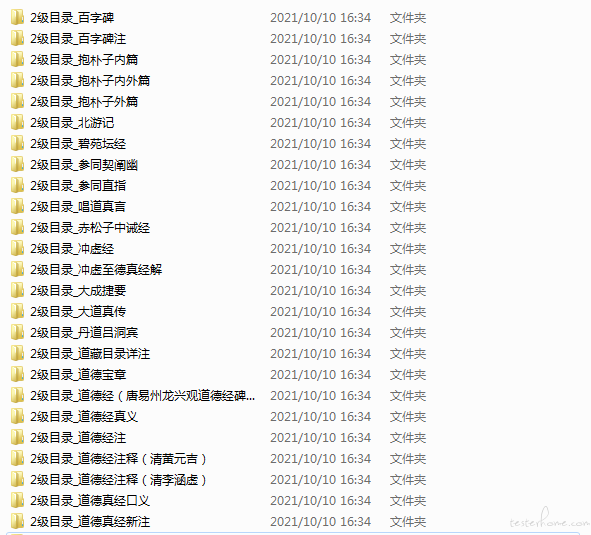
进入 2 级目录之后,就是所有文章的标题了。
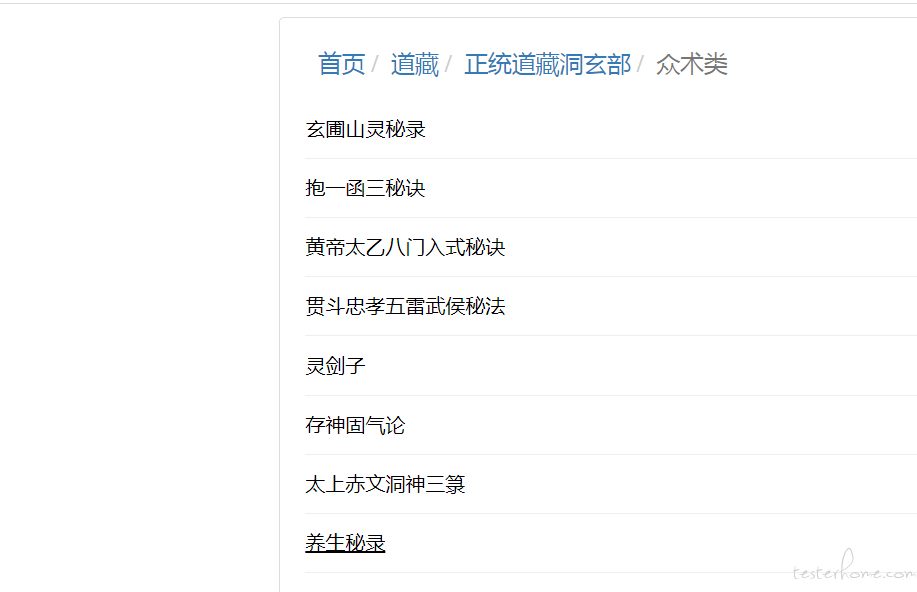
最终文本提取
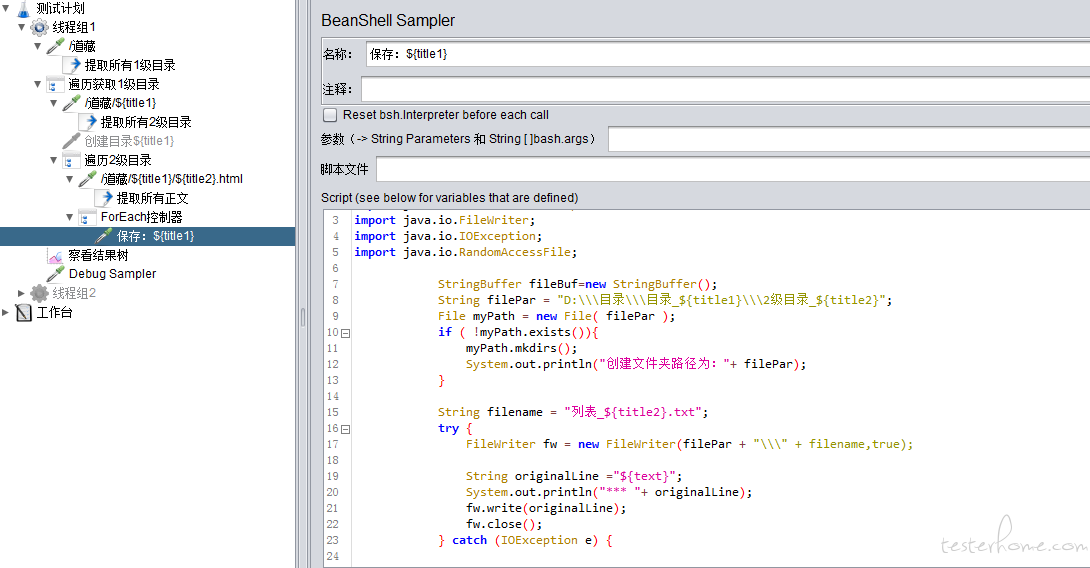
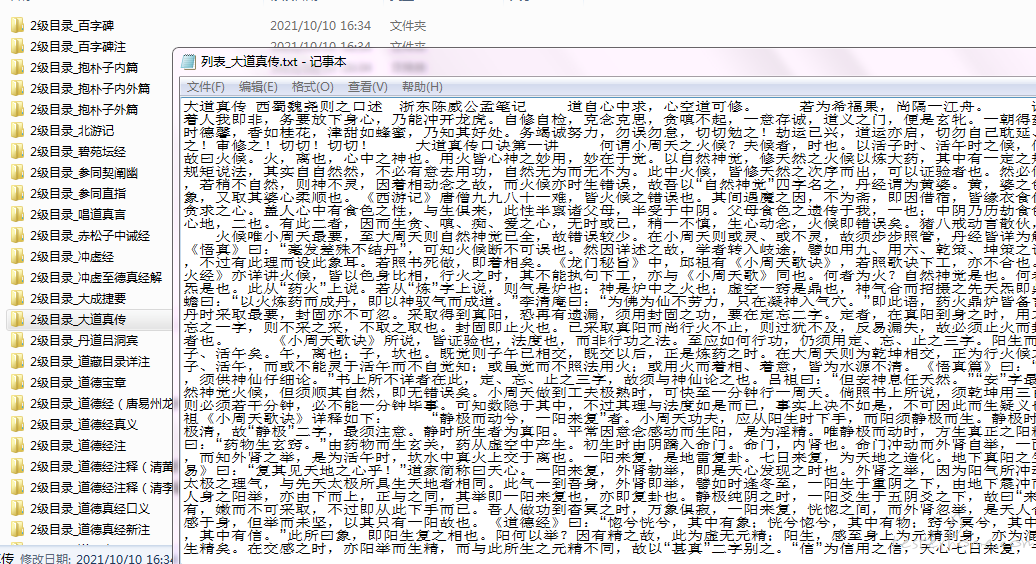
我们在 2 级 for 循环下面套入最后一层循环,用来遍历获取所有正文并保存到本地
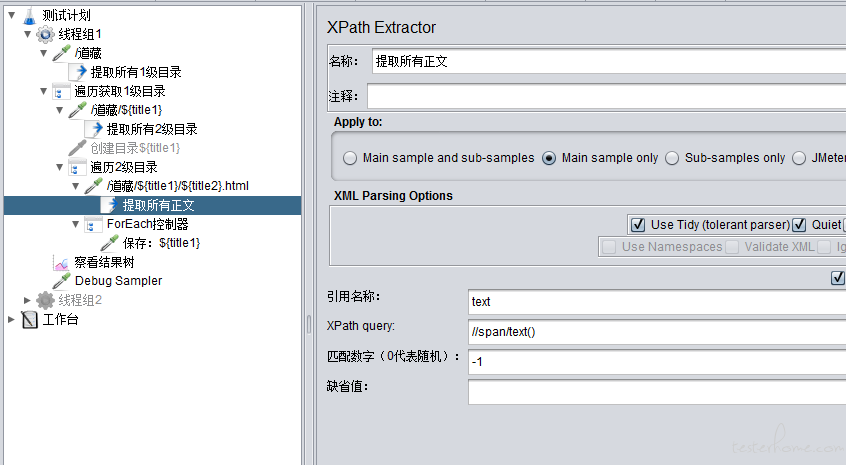
难点在于,需要按照标题的层级关系来创建文件目录,并把超链接之后的文本正确保存到对应的文件目录之中
整体结构
TesterHome 为用户提供「保留所有权利,禁止转载」的选项。
除非获得原作者的单独授权,任何第三方不得转载标注了「All right reserved, any unauthorized reproduction or transfer is prohibitted」的内容,否则均视为侵权。
具体请参见TesterHome 知识产权保护协议。
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!
