
移动测试开发 微服务架构中注册中心 Zookeeper 和 Eureka 我们应该怎么选?
背景
因为注册中心是微服务架构中最核心的基础服务之一,在选择注册中心方案之前,我们先了解以下什么是微服务架构。
在 Monolithic 架构中我们经常会面临以下问题:
1、系统间以 api 的形式互相访问,导致系统之间紧密的耦合在一起难以维护
2、不同的业务需要相同的技术栈,无法快速应用新技术
3、系统任何修改都必须整个系统一起部署,维护成本高
4、系统负载增加时候,难以水平拓展
5、一个问题影响全局
为了解决这些问题,微服务架构就产生了,微服务是一种架构风格,也就说将复杂的应用拆分成多个独立的服务,服务之间通过松耦合的方式调用。在松耦合方式中注册中心扮演了重要的角色。注册中心可以说是微服务架构中的” 通讯录 “,它记录了服务和服务地址的映射关系。在分布式架构中,服务会注册到这里,当服务需要调用其它服务时,就这里找到服务的地址,进行调用。
目前经常被用到作为注册中心的有 Zookeeper 和 Eureka,那么此时我们就会纠结如何去选择这两个注册中心,下面我们来系统的学习这两种注册中心的原理和优劣势,这样才能在架构搭建中合理的选择注册中心。
注册中心概念
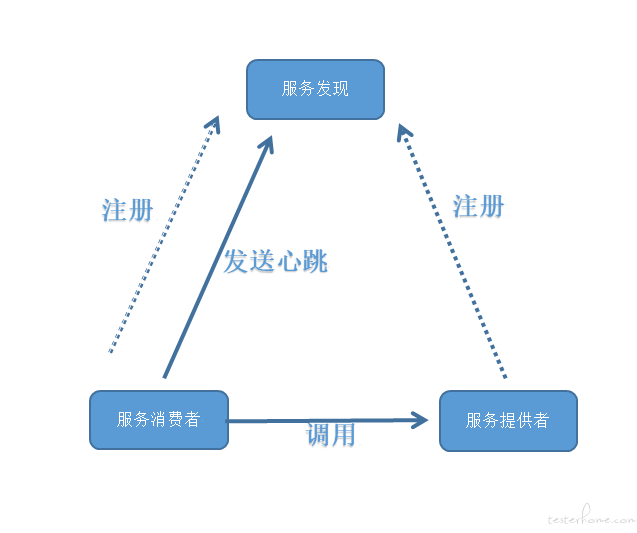
注册中心涉及三大角色
1、服务提供者
2、服务消费者
3、注册中心
他们之间的关系主要是
1、各个服务启动的时候,将自己网络地址等信息记录到注册中心
2、服务消费者从注册中心查询服务提供者提供的服务,并通过对应的地址调用服务提供者的 api
3、微服务与注册中心使用心跳机制通信,如果注册中心与微服务长时间无法通信,就会注销该服务实例
注册中心架构图:
注册中心的主要作用
在微服务架构中,注册中心主要起到了协调者的作用,主要有以下功能
1、服务发现
服务注册/反注册:保存服务提供者和服务调用者的信息
服务订阅/取消订阅:服务调用者订阅服务提供者的信息,最好有实时推送的功能
服务路由(可选):具有筛选整合服务提供者的能力。
2、服务配置
配置订阅:服务提供者和服务调用者订阅微服务相关的配置
配置下发:主动将配置推送给服务提供者和服务调用者
3、服务健康检测
检测服务提供者的健康情况
注册中心 Zookeeper 和 Eureka 如何选择
在分布式架构中往往伴随 CAP 的理论。因为分布式的架构,不再使用传统的单机架构,多机为了提供可靠服务所以需要冗余数据因而会存在分区容忍性P。
冗余数据的同时会在复制数据的同时伴随着可用性 A 和强一致性 C 的问题。是选择停止可用性达到强一致性还是保留可用性选择最终一致性。通常选择后者。其中 Zookeeper 和 Eureka 分别是注册中心 CP AP 的两种的实践。
Zookeeper
Zookeeper 概述
ZooKeeper 主要为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。曾经是 Hadoop 项目中的一个子项目,用来控制集群中的数据,目前已升级为独立的顶级项目。很多场景下也用它作为 Service 发现服务解决方案。
ZooKeeper 是基于 CP 来设计的,即任何时刻对 ZooKeeper 的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,但是它不能保证每次服务请求的可用性。从实际情况来分析,在使用 ZooKeeper 获取服务列表时,如果 zookeeper 正在选主,或者 ZooKeeper 集群中半数以上机器不可用,那么将无法获得数据。所以说,ZooKeeper 不能保证服务可用性。
Zookeeper(数据一致性)数据同步分析
我们知道 Zookeeper 集群在选举结束之后,leader 节点将进入 LEADING 状态,follower 节点将进入 FOLLOWING 状态;此时集群中节点将进行数据同步操作,以保证数据一致。 只有数据同步完成之后 Zookeeper 集群才具备对外提供服务的能力。
当节点在选举后角色确认为 leader 后将会进入 LEADING 状态,代码如下:
public void run() {
try {
/*
* Main loop
*/
while (running) {
switch (getPeerState()) {
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
}
}
} finally {
}
}
QuorumPeer 在节点状态变更为 LEADING 之后会创建 leader 实例,并触发 lead 过程。
void lead() throws IOException, InterruptedException {
try {
// 省略
/**
* 开启线程用于接收 follower 的连接请求
*/
cnxAcceptor = new LearnerCnxAcceptor();
cnxAcceptor.start();
readyToStart = true;
/**
* 阻塞等待计算新的 epoch 值,并设置 zxid
*/
long epoch = getEpochToPropose(self.getId(), self.getAcceptedEpoch());
zk.setZxid(ZxidUtils.makeZxid(epoch, 0));
/**
* 阻塞等待接收过半的 follower 节点发送的 ACKEPOCH 信息; 此时说明已经确定了本轮选举后 epoch 值
*/
waitForEpochAck(self.getId(), leaderStateSummary);
self.setCurrentEpoch(epoch);
try {
/**
* 阻塞等待 超过半数的节点 follower 发送了 NEWLEADER ACK 信息;此时说明过半的 follower 节点已经完成数据同步
*/
waitForNewLeaderAck(self.getId(), zk.getZxid(), LearnerType.PARTICIPANT);
} catch (InterruptedException e) {
// 省略
}
/**
* 启动 zk server,此时集群可以对外正式提供服务
*/
startZkServer();
// 省略
}
从 lead 方法的实现可得知,leader 与 follower 在数据同步过程中会执行如下过程:
● 接收 follower 连接
● 计算新的 epoch 值
● 通知统一 epoch 值
● 数据同步
● 启动 zk server 对外提供服务
下面在看下 follower 节点进入 FOLLOWING 状态后的操作:
public void run() {
try {
/*
* Main loop
*/
while (running) {
switch (getPeerState()) {
case LOOKING:
// 省略
case OBSERVING:
// 省略
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
}
}
} finally {
}
}
从 followLeader 方法的实现可得知,follower 与 leader 在数据同步过程中会执行如下过程:
● 请求连接 leader
● 提交节点信息计算新的 epoch 值
● 数据同步
● 以上就是 zookeeper 的同步逻辑
Eureka
Eureka 概述
Eureka 本身是 Netflix 开源的一款提供服务注册和发现的产品,并且提供了相应的 Java 封装。在它的实现中,节点之间相互平等,部分注册中心的节点挂掉也不会对集群造成影响,即使集群只剩一个节点存活,也可以正常提供发现服务。哪怕是所有的服务注册节点都挂了,Eureka Clients(客户端)上也会缓存服务调用的信息。这就保证了我们微服务之间的互相调用足够健壮。
而 Spring Cloud Netflix 在设计 Eureka 时遵守的就是 AP 原则。Eureka Server 也可以运行多个实例来构建集群,解决单点问题,但不同于 ZooKeeper 的选举 leader 的过程,Eureka Server 采用的是 Peer to Peer 对等通信。这是一种去中心化的架构,无 master/slave 区分,每一个 Peer 都是对等的。在这种架构中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。每个节点都可被视为其他节点的副本。
如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点,当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会进行 replicateToPeer(节点间复制)操作,将请求复制到其他 Eureka Server 当前所知的所有节点中。
一个新的 Eureka Server 节点启动后,会首先尝试从邻近节点获取所有实例注册表信息,完成初始化。Eureka Server 通过 getEurekaServiceUrls() 方法获取所有的节点,并且会通过心跳续约的方式定期更新。默认配置下,如果 Eureka Server 在一定时间内没有接收到某个服务实例的心跳,Eureka Server 将会注销该实例(默认为 90 秒,通过 eureka.instance.lease-expiration-duration-in-seconds 配置)。当 Eureka Server 节点在短时间内丢失过多的心跳时(比如发生了网络分区故障),那么这个节点就会进入自我保护模式。
Eureka 高可用原理
架构图:
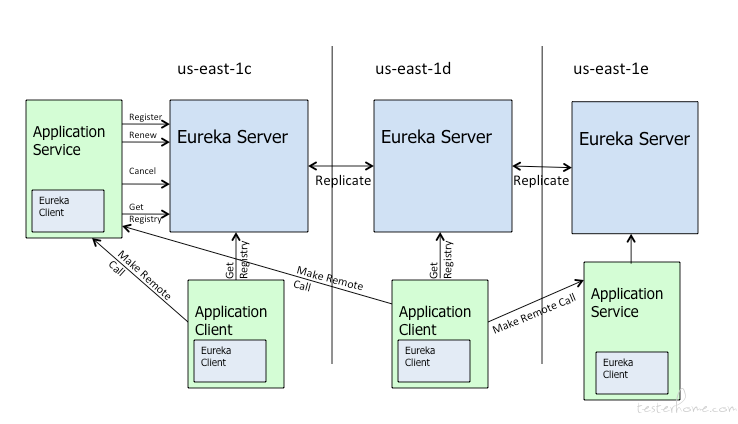
Eureka Client 向 Eureka Serve 注册,并将自己的一些客户端信息发送 Eureka Serve。然后,Eureka Client 通过向 Eureka Serve 发送心跳(每 30 秒)来续约服务的。 如果客户端持续不能续约,那么,它将在大约 90 秒内从服务器注册表中删除。 注册信息和续订被复制到集群中的 Eureka Serve 所有节点。 来自任何区域的 Eureka Client 都可以查找注册表信息(每 30 秒发生一次)。根据这些注册表信息,Application Client 可以远程调用 Applicaton Service 来消费服务。
Eureka 高可用实际上将自己作为服务向其他服务注册中心注册自己,这样就可以形成一组相互注册的服务注册中心,从而实现服务清单的互相同步,达到高可用效果。
Eureka 集群环境搭建
Eureka01 配置
###服务端口号
server:
port: 8000
###serviceId
spring:
application:
name: eureka-server
###eureka 基本信息配置
eureka:
instance:
###注册到eurekaip地址
hostname: 127.0.0.1
client:
serviceUrl:
defaultZone: http://127.0.0.1:8100/eureka/
### 3台就需要让3台服务相互注册,用逗号分隔。defaultZone: http://127.0.0.1:8100/eureka/,http://127.0.0.1:xxxx/eureka/
###因为自己是为注册中心,不需要自己注册自己
register-with-eureka: true
###因为自己是为注册中心,不需要检索服务
fetch-registry: true
server:
# 测试时关闭自我保护机制,保证不可用服务及时踢出
enable-self-preservation: false
eviction-interval-timer-in-ms: 2000
Eureka02 配置
###服务端口号
server:
port: 8100
###serviceId
spring:
application:
name: eureka-server
###eureka 基本信息配置
eureka:
instance:
###注册到eurekaip地址
hostname: 127.0.0.1
client:
serviceUrl:
defaultZone: http://127.0.0.1:8000/eureka/
###因为自己是为注册中心,不需要自己注册自己
register-with-eureka: true
###因为自己是为注册中心,不需要检索服务
fetch-registry: true
server:
# 测试时关闭自我保护机制,保证不可用服务及时踢出
enable-self-preservation: false
eviction-interval-timer-in-ms: 2000
客户端集成 Eureka 集群
###服务启动端口号
server:
port: 8002
###服务名称(服务注册到eureka名称)
spring:
application:
name: app-itmayiedu-order
###服务注册到eureka地址
eureka:
client:
service-url:
defaultZone: http://localhost:8000/eureka,http://localhost:8100/eureka
###因为该应用为注册中心,不会注册自己
register-with-eureka: true
###是否需要从eureka上获取注册信息
fetch-registry: true
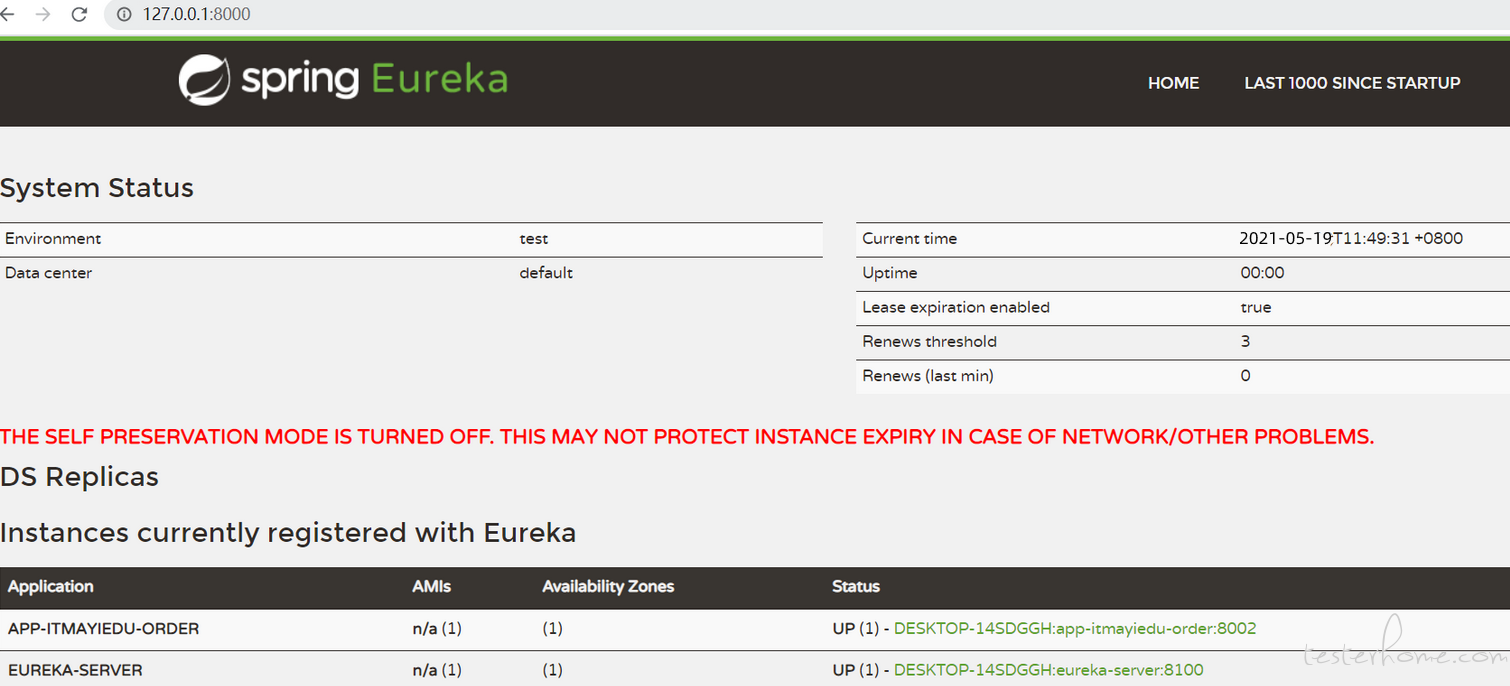
启动集群
总结
ZooKeeper 基于 CP,不保证高可用,如果 zookeeper 正在选主,或者 ZooKeeper 集群中半数以上机器不可用,那么将无法获得数据。Eureka 基于 AP,能保证高可用,即使所有机器都挂了,也能拿到本地缓存的数据。作为注册中心,其实配置是不经常变动的,只有发版和机器出故障时会变。对于不经常变动的配置来说,CP 是不合适的,而 AP 在遇到问题时可以用牺牲一致性来保证可用性,既返回旧数据,缓存数据。
所以理论上 Eureka 是更适合做注册中心。而现实环境中大部分项目可能会使用 ZooKeeper,那是因为集群不够大,并且基本不会遇到用做注册中心的机器一半以上都挂了的情况。所以实际上也没什么大问题。