
前言
新开一门课,UCB CS267,需要有计算机体系结构和编译原理的基础。
不知道到底水有多深,既然是目标,那就继续吧。
因为开始工作,尽量在周末和节假日做更新了。
内存结构
注意点:
- 寄存器是编译器申请的,cache 是硬件申请的。寄存器申请可以用图着色算法(编译原理的内容)
编译器做的优化:

制约性能的要素主要在内存的延时,这里可以看一下 little's law 的定义:
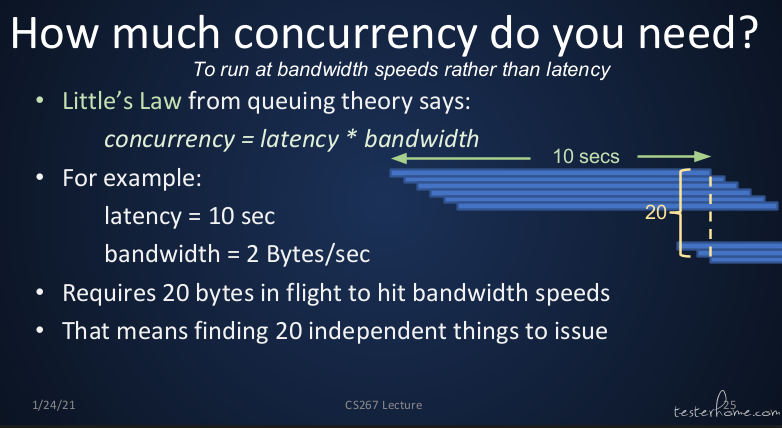
关于 cache 设计的相关问题,请自行理解计算机组成原理。
单 CPU 并行
主要实现方法:

关于并行的概念请学习计算机组成原理,其中有 CPU 五级流水线的设计思想。
关于 SIMD,主要的并行指令集有:AVX512、NEON 等。(思想是单条指令对连续内存进行相同操作,从而提升性能。)
指令执行顺序的问题:

WAR 是需要等待的。(如果自己写指令,这里需要仔细考量。)

如上图所示,在特定条件下,矢量化可以减少依赖。、
内存偏移对性能的影响:

FMA 的介绍:

相对复杂一点的指令集都提供了 FMA 指令。
这里引入了 tiling 的概念:

如 TVM 就是搜索 tiling 策略的开源解决方案。
矩阵乘法
性能公式:
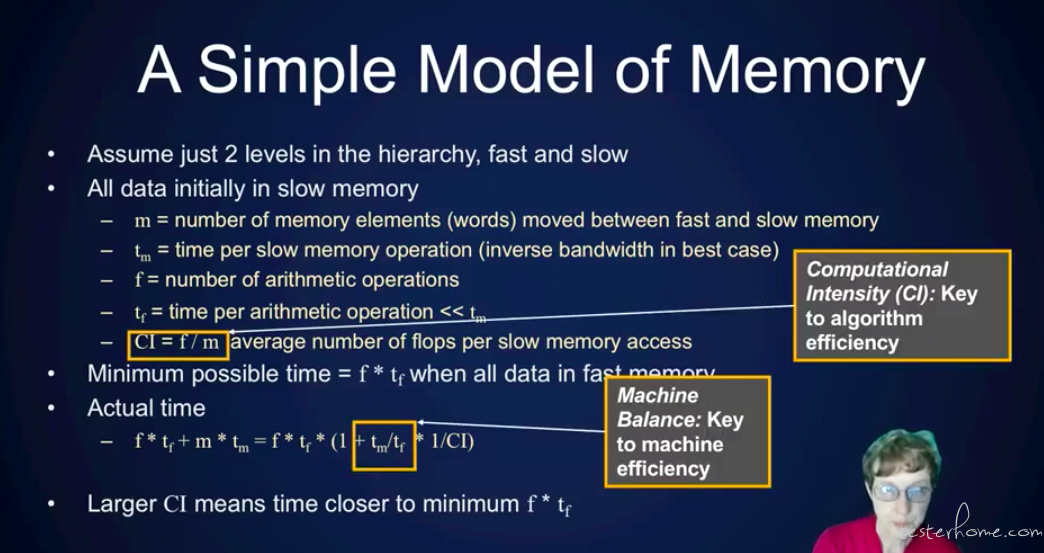
需要从机器性能和算法性能两个角度去思考问题。
tm/tf 通过设计多级缓存的方式,降低 cache 命中率。
CI=f/m,通过设计程序的访问存储的方式,降低 m,从算法的角度提升性能。
y=y+Ax:

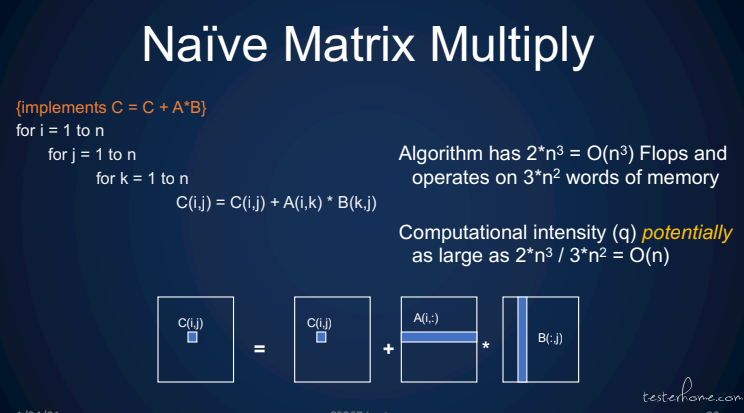
原始矩阵乘法:

tiled 矩阵乘法:

内存读取方式:
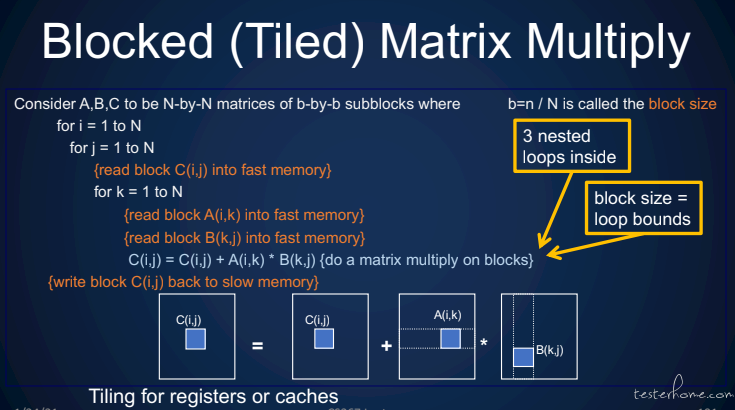
CI 计算:

最后在乘加操作时,可以通过结合律和并行再去加速:

PS:很多硬件乘加操作一个指令就可以了,这里的并行可能实际上没用。
优化实践方法:

内存排布优化:

方法 1 是 CUDA 常用的方法,规避 bank conflict.
方法 2,3 在华为昇腾芯片中有实现,内存有大 Z 小 Z 的排布。
还有 Unloop 的优化方法。
可以分离的计算使用不同的寄存器可以并行:

多用指针偏移,少对指针直接操作:

总结:

这节课理论和实践的说明都非常充足,tiling 为什么能快,为什么会快,一些内存编译的常识,非常棒的一个课程。