
这讲开始介绍如何优化 GPU 编程。这讲都可以看看,有一些软件工程通用的思想。
GPU 编程的原则:

GPU 的优化层次:

GPU 不同于 CPU 的并行,提升效率有限。
CPU 的并行指令集是可以提升数倍的性能的。当然 CPU 的并行过度使用,也可能导致 CPU 长期高负荷,导致整体系统性能下降。
在 GPU 的示例:

比如排序算法会使用合并排序而不会使用堆排序,gpu 的体系结构对算法选择也会有影响。
APOD 原则:
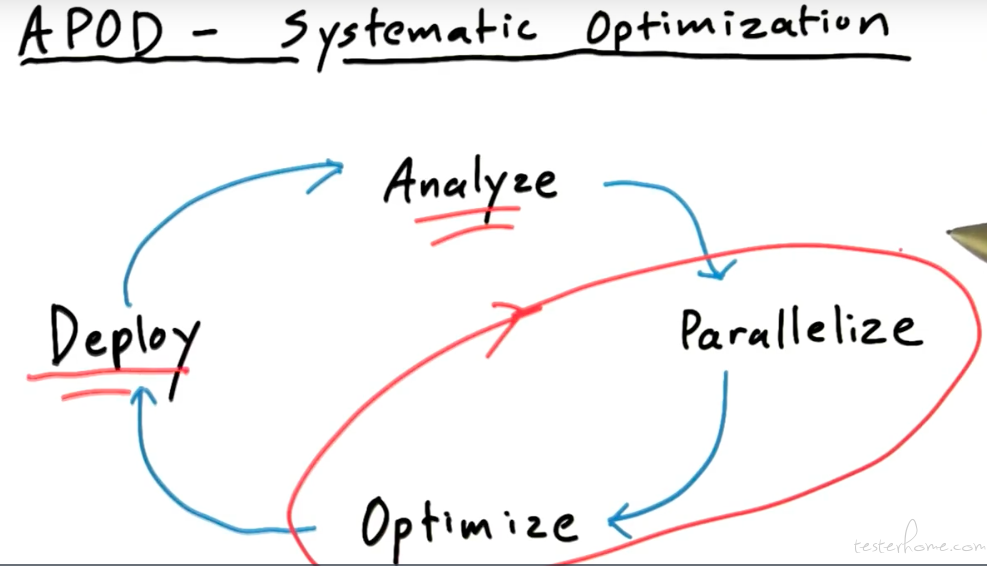
结合 gpu 具体如何实现呢?


这里有个点,性能优化并不需要到极致再提给用户,而是可以用就应该和用户一起去改善。
ps:国内的各种夸大的技术宣传,然后真正用起来真是一言难尽。。。
纯理论的内容就不说了,有兴趣的可以去看 Gatech 的 cs6220.
transpose 举例:
二维切片举例:
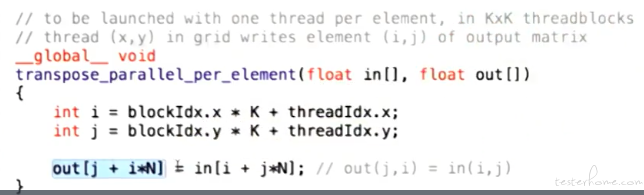

如果懂一些 cuda 的会知道 cuda 也会有指令集,cuda 的指令集也是有尺寸输入输出限制的,在某些尺寸下性能会最优化。
由于 transpose 只有访存操作,不涉及计算,那么该操作的理论带宽上限就是内存的吞吐量,具体计算过程如下:

这里可以看到例子中的访存利用率 30% 出头,什么原因造成的呢?
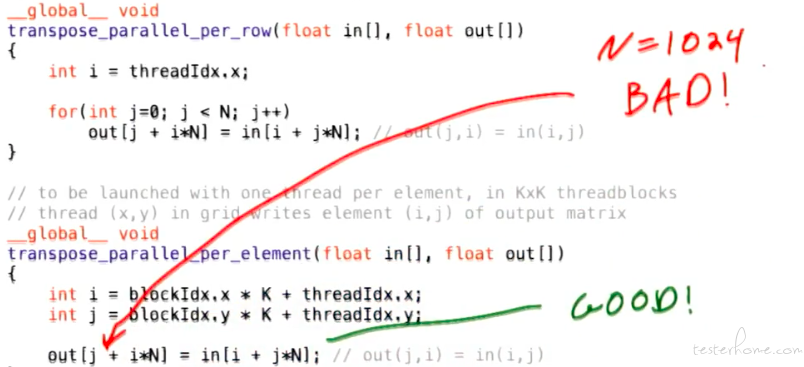
因为 out 的访存是不连续的。
nvvp
nvidia 的可视化性能工具 nvvp.

从上图可以看 store 的利用率较低,因此针对 store 进行优化。
TIling

通过此写法可以减少 write 的访存访问时间。
Dram 依然很慢。
真正等待延时的是 thread 同步。
可以通过如下的方式尝试解决:

占用
限制主要在 sm:

如果线程启用多了,实际并不能启动那么多的 block.

参数可以通过 deviceQuery 查询得出。
提升 GPU 占用率的方法:

可以对比一下优化的步骤和效果:

最后一行是 16*17,解决 bank conflict 的问题。
并行计算优化:

几个主要的概念:

在 cpu 中会有 cpu 的流水线分支预测惩罚,在 gpu 中对应的是 thread 的指令惩罚。
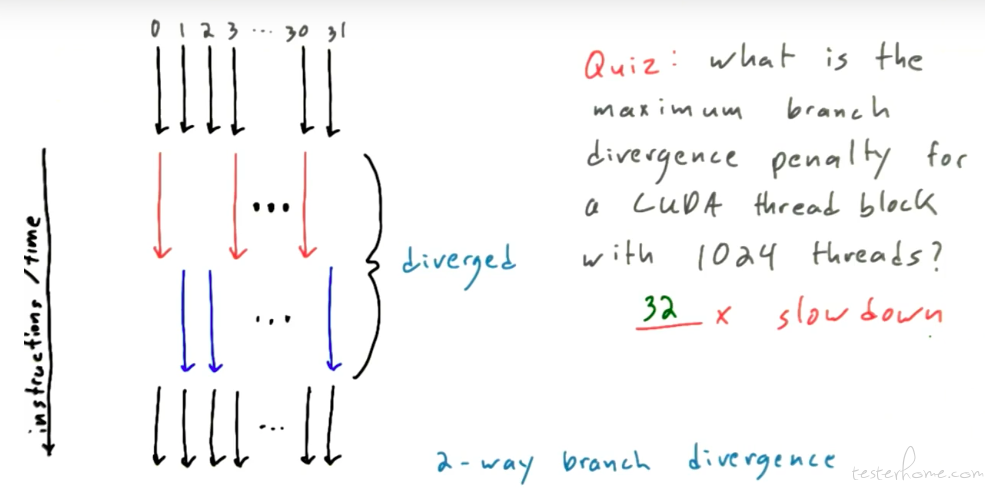
这里有个问题需要结合 warp 的概念来看:

warp 是 cuda 体系结构的概念,其包含 32 个 thread。
其排布顺序:
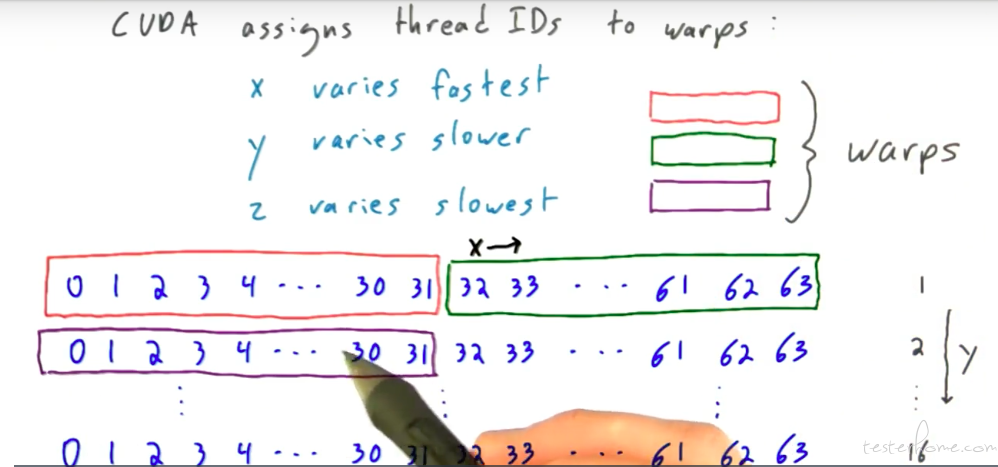
结合排布顺序,理解前面一张图的解答。
如何减少多分支造成的性能降低呢?

我个人理解 gpu 并没有像 cpu 那样实现一个强的指令预测器件。
这就要求在编写并行程序的时候关注可能存在分支的代码。
同时也可以通过一定的循环优化,减少分支预测的情况。
不谈算法层面,还有一个可以简单实现的优化:

host-gpu 交互
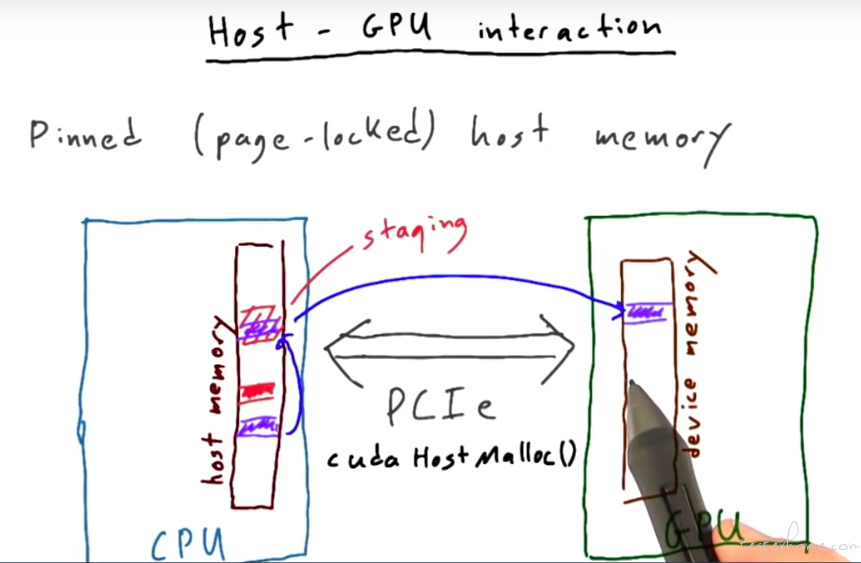
host-gpu 通常会通过 pcie 总线进行连接。
我个人会理解作为外设,也会有自己的驱动控制并可以在 cpu 的内存中申请内存用于数据传输。
CUDA 作为一个 c/c++ 扩展库,提供函数进行数据搬移。
流
CUDA 流表示一个 GPU 操作队列,该队列中的操作将以添加到流中的先后顺序而依次执行。可以将一个流看做是 GPU 上的一个任务,不同任务可以并行执行。

总结:




这一讲的内容很多,估计过段时间我也会还一部分回去,这个是我看到的比较简单的内容,而且贴合实际代码,如果对性能优化有兴趣的话,可以尝试一读。