
这讲介绍一些运算算法。
从 step,work 的概念开始:
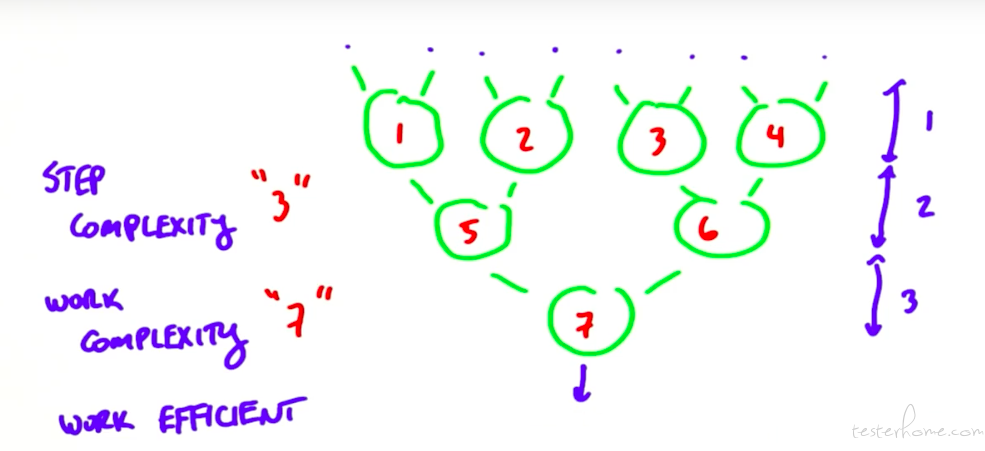
reduce
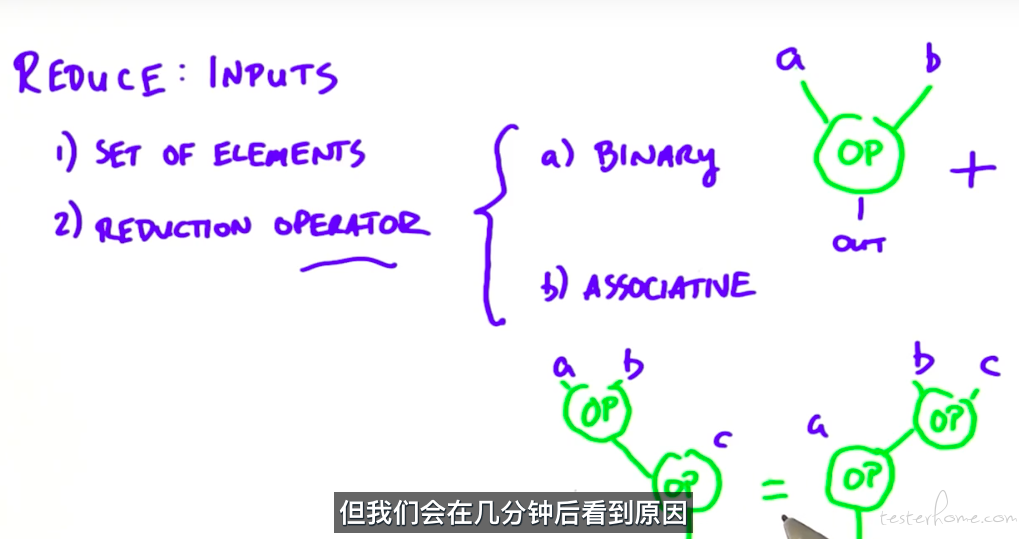
reduce 是两个元素的操作,同时需要满足结合律。
使用 block shared memory 的代码实现:
https://github.com/udacity/cs344/blob/master/Lesson%20Code%20Snippets/Lesson%203%20Code%20Snippets/reduce.cu
使用 global 的内存访问时间会变长。
scan
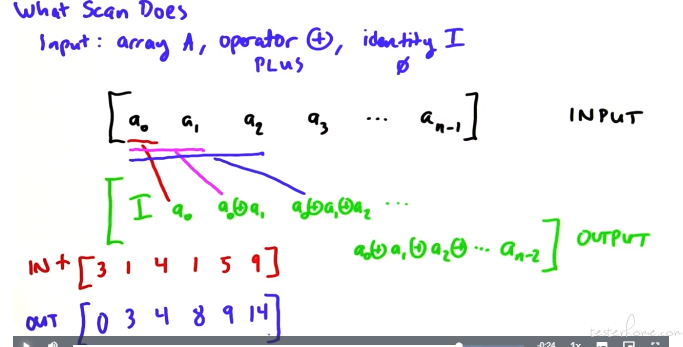
注意 scan 最后的一个元素是不会使用的。
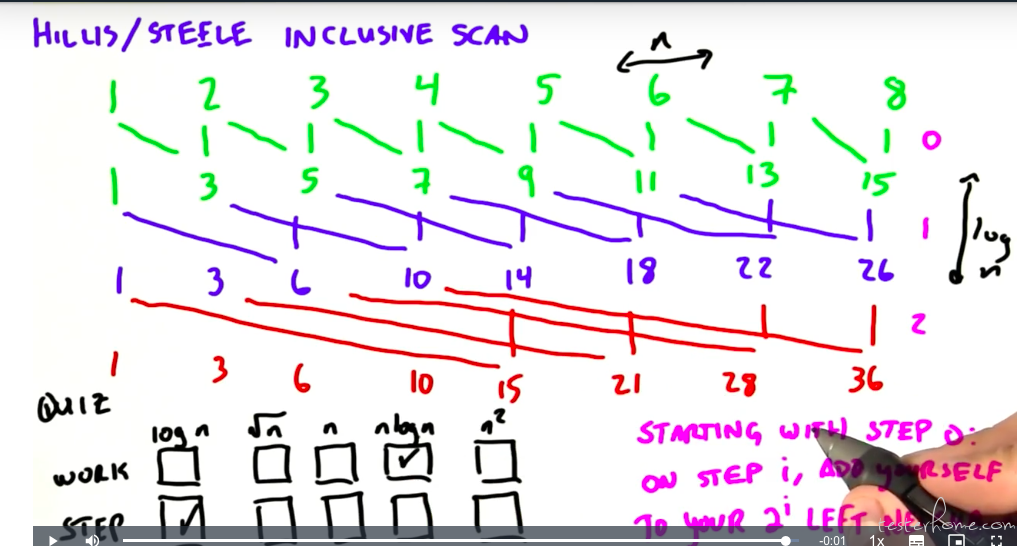
下面这张图解释了为什么最后一个元素不用,因为有两种 scan:
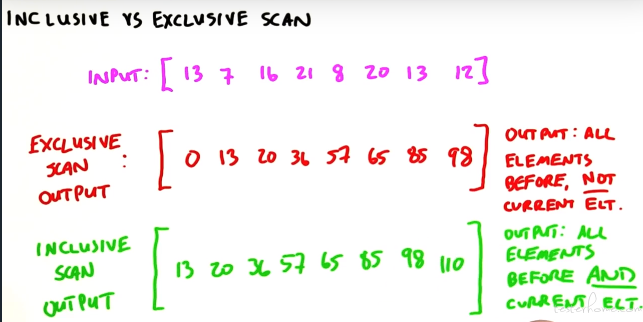
Hillis Steele Scan:
Blelloch Scan:
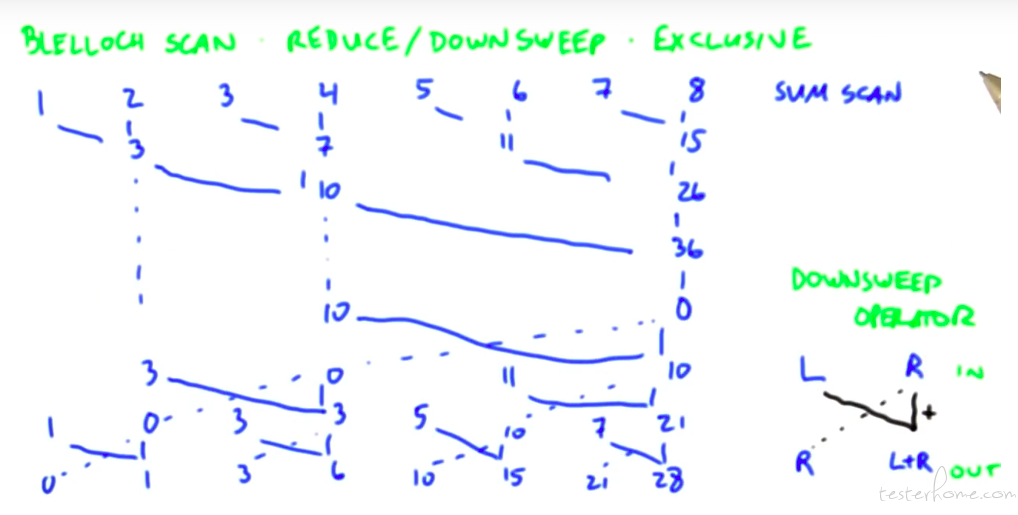
GPU 的计算用的是这个算法。
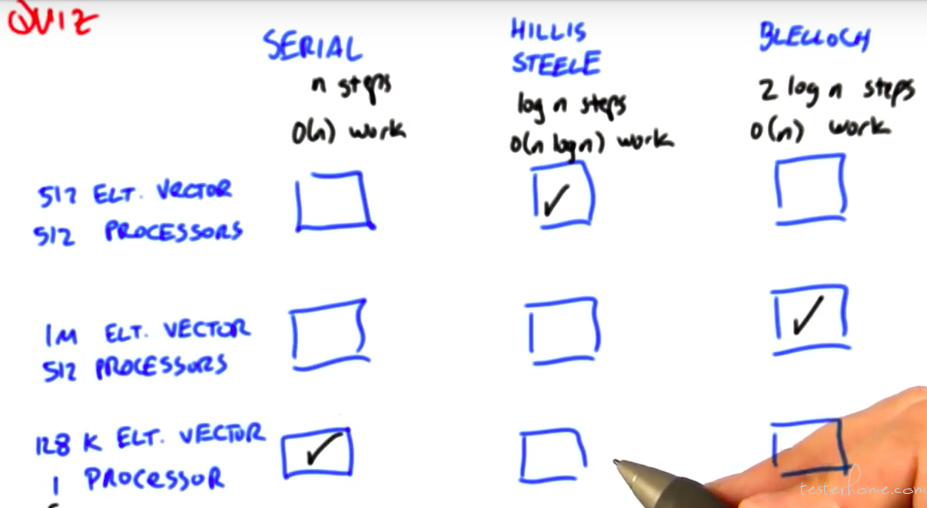
scan 算法对比:
Histogram
直方图的定义:
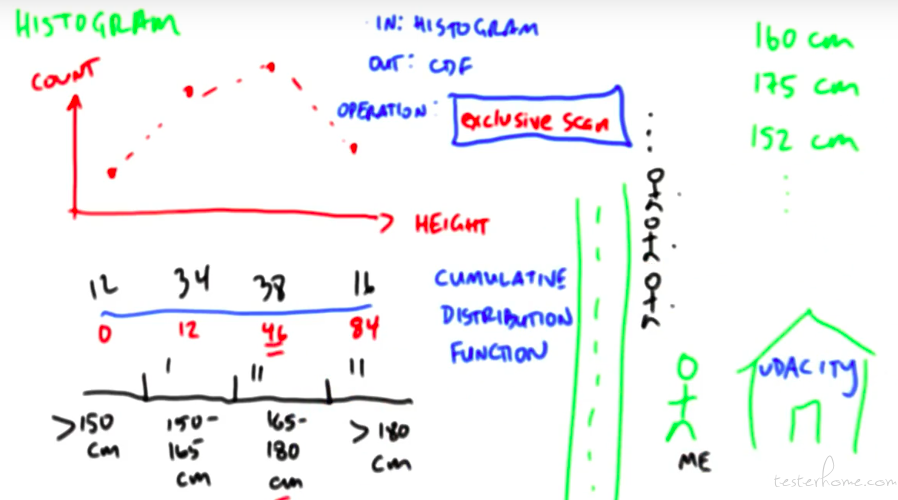
可以通过 scan 解决直方图的问题。
直方图用简单的串行化思想写的代码用多线程是没有太大意义的。
因为判断放在哪个区间是需要条件判断的,每个线程访问的空间会随着输入变化。
当 bin 小的时候,可以通过分别处理每个 bin 并行来实现:
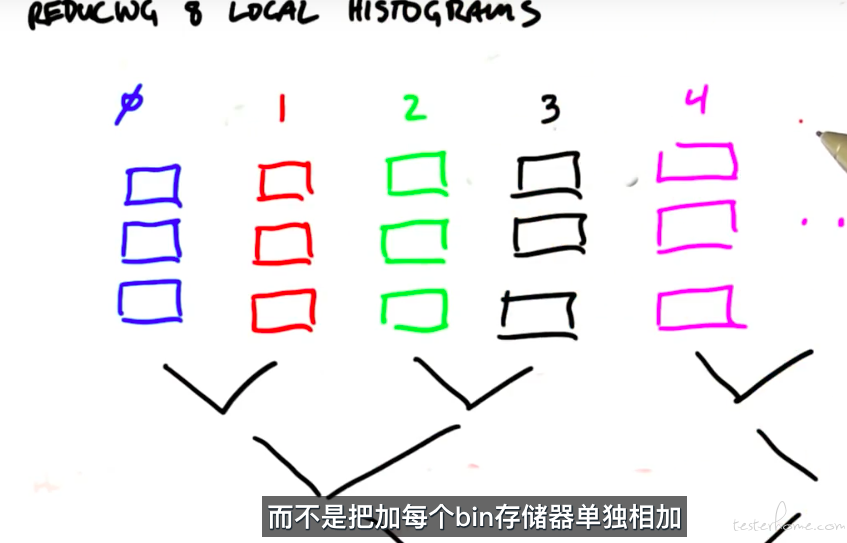
关于直方图的算法总结:

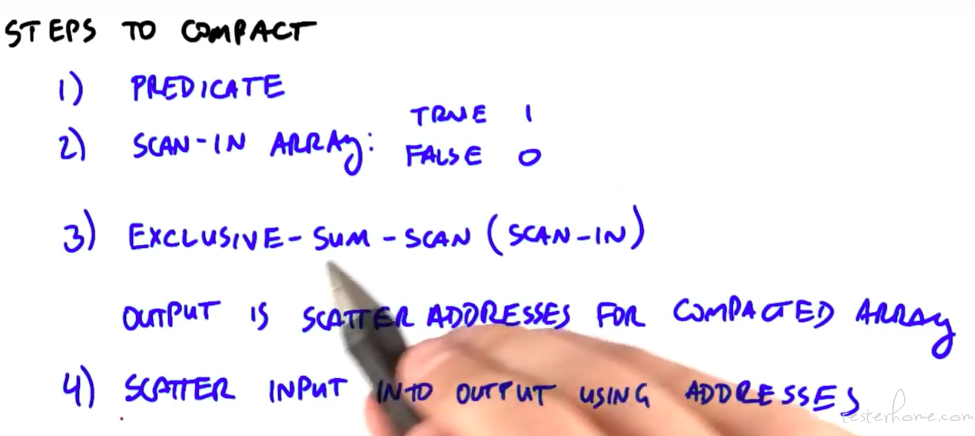
compat
神经网络里面应该没有什么需要 compat 的点吧。
如果硬要说的话,Int8 算是一种优化。CUDA 11 和新的安培架构有针对稀疏化的优化。
但是不妨碍了解一下实现步骤:
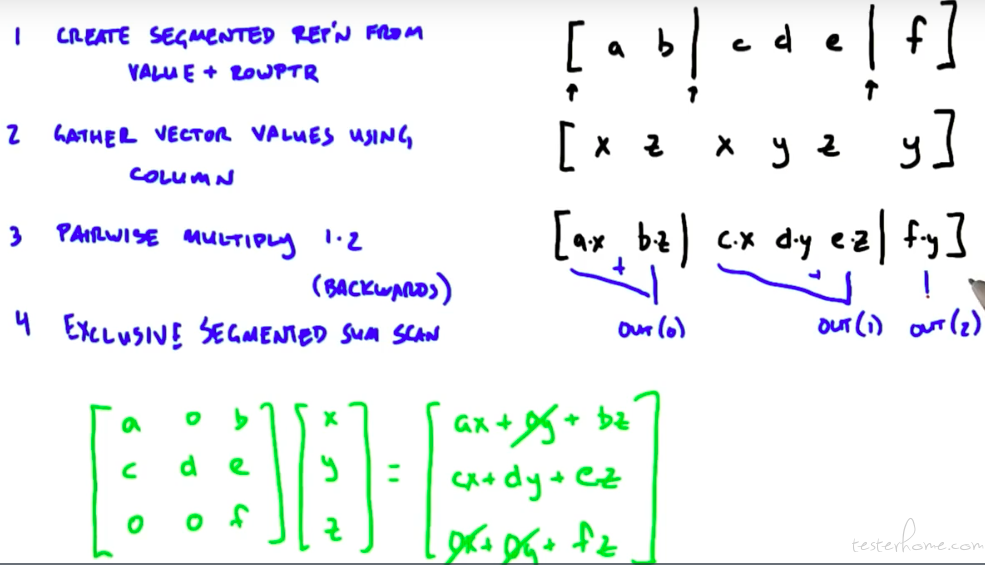
稀疏矩阵的表达:

最后一行表示行对应的 column 起始地址。
稀疏矩阵乘法:
排序:

并行计算通常使用的排序是归并排序:
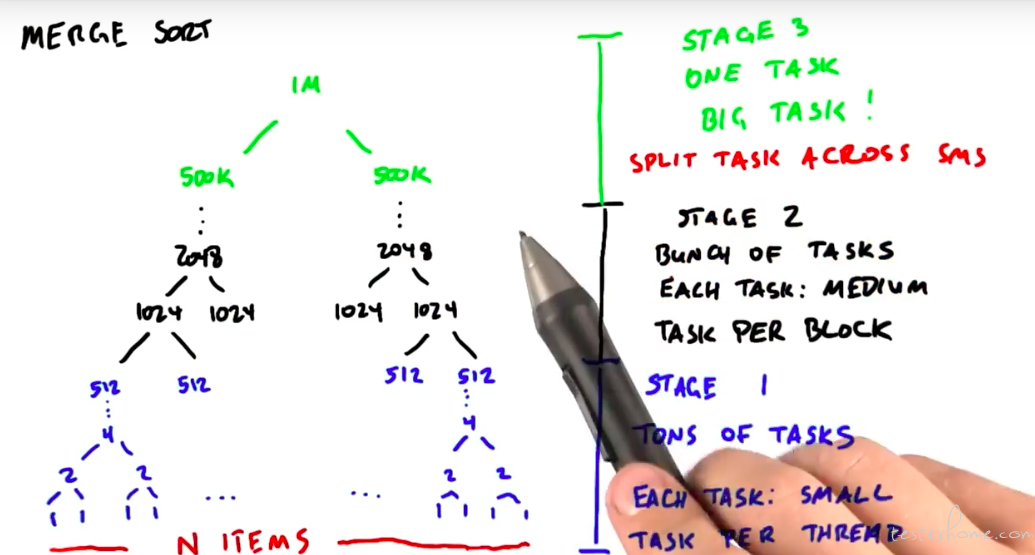
顶层需要跨 SM,提升性能。
https://blog.csdn.net/abcjennifer/article/details/47110991
这篇文章讲的很棒,第三步的算法描述很清晰。

双调排序:
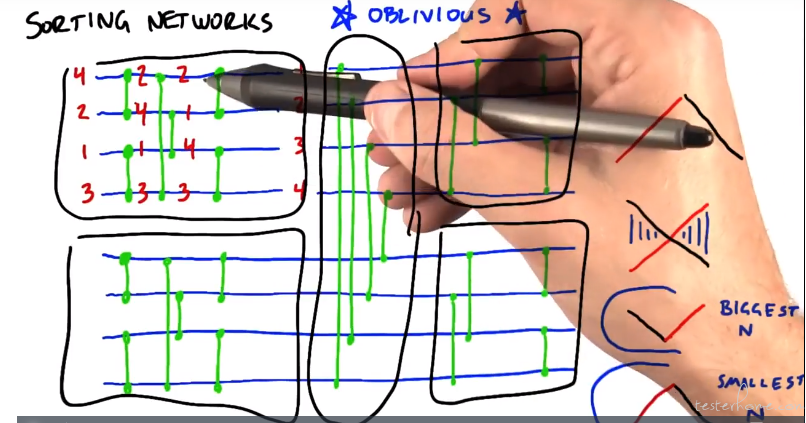
radix sort(基数排序)
https://blog.csdn.net/Mrhiuser/article/details/51997640
参考这篇文章吧。
快排

百度搜到这篇,CUDA 5.5 支持快排:
https://blog.csdn.net/niexiao2008/article/details/9622461
具体好不好用,需要用的时候再说。
排序总结:
