
下面开始讲中后端了。
按照主流的说法,优化中部分如图优化是中端的事情,只有和硬件汇编指令交互的才称为后端,如:codegen。

在中端需要实现如下内容:

程序运行需要的资源:

Compiler 需要分析程序需要哪些 CODE,哪些数据。
Code 和数据之间如何组合。

activation
程序的目标:

在正确的前提下提升速度。
activation 的定义:

这里理解一下 lifetime 和 scope 的区别:

一个是 runtime 的动态概念,一个是编译的静态概念。
这里关注一下 activation tree 的概念

一个例子:

activation tree 的特性:

如果熟悉计算机组成原理,call function 会利用 stack 保存状态。(大量的递归调用会导致 stack overflow)
activation record

AR layout 和 code generator 需要同时设计

全局变量和堆
全局变量:

全局变量在编译时,需要确定相对位置。熟悉汇编的可以看到全局变量用的是数据块的相对地址。
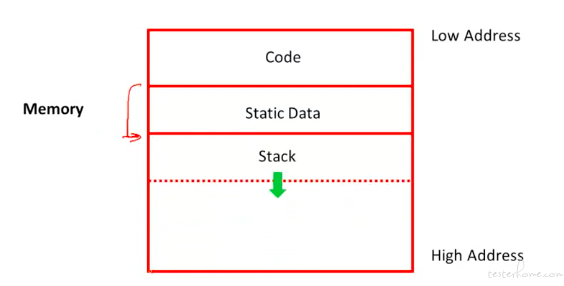
heap 的引入:

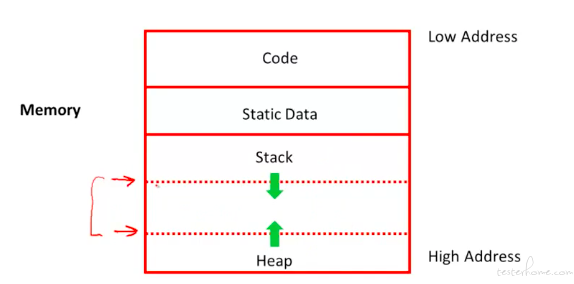
关于程序段的总结:

alignment

对齐对性能会有很大影响,不过有不对齐的编译器么?

stack machine
这一节和 code generator 相关。
说明:

例子:

转载文章时务必注明原作者及原始链接,并注明「发表于 TesterHome 」,并不得对作品进行修改。
暂无回复。