
文件系统
前期回顾:
回顾一下文件系统的位置:
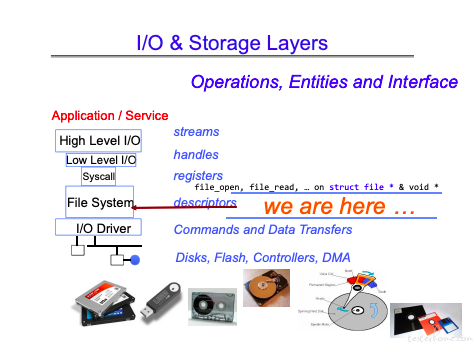
在 I/O 之上,在 system call 之下。文件状态由文件描述符管理。

文件的主要操作,这里注意一下写操作,写操作返回时,不代表写操作结束。
文件系统功能

从用户到系统内部看文件

从用户角度看,文件是数据结构。从 system call 看,文件是一串字节。从系统内部看文件是 blocks.
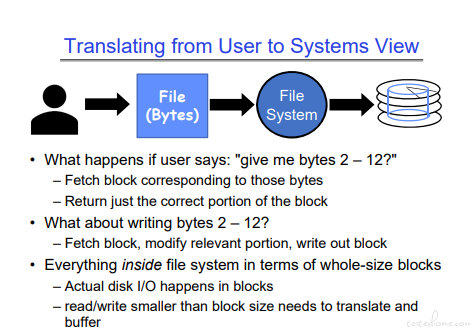
这图更容易理解一些。
文件管理方式

1.文件系统里一切都是文件,目录也是文件。
2.现代操作系统内部用的是逻辑 sector。
Disk 数据结构

- 文件的数据结构不同于内存的数据结构。
- 再次强调不管写多少,要写只能按 block 的大小来。
如何设计一个文件系统导言:

文件系统概念
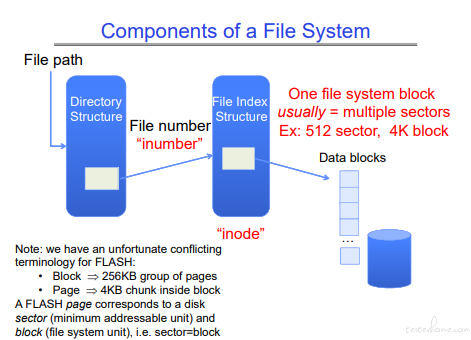
理解文件系统的 block。
注意和 FLASH,SSD 里 BLOCK 的区别,闪存一次擦写只能操作 256KB 的数据,也会被称为 block.

文件的基础操作都是在句柄上完成的。
目录

这里我自己有两个疑问:
1. 为什么是硬链接是 DAG,而不仅仅是 Tree?
2. 软链接的实现方式和优势

历史文件也有缓存,可以加速定位
pwd 命令相信基本都用过。
文件

来看两个基本操作:
打开文件操作:
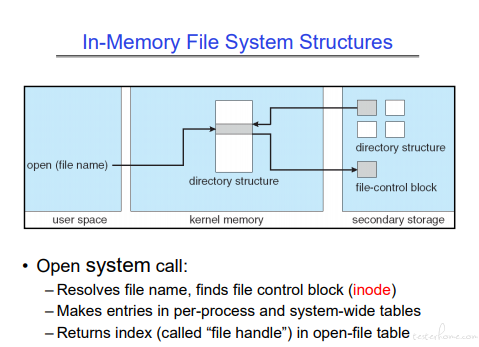
读取文件操作:
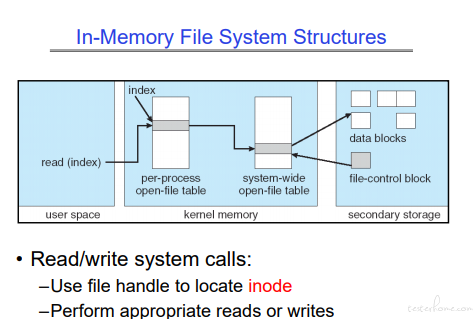
读文件,会根据句柄,查找打开文件生成的数据,最后指向真实文件对应的区块。
文件系统
FAT
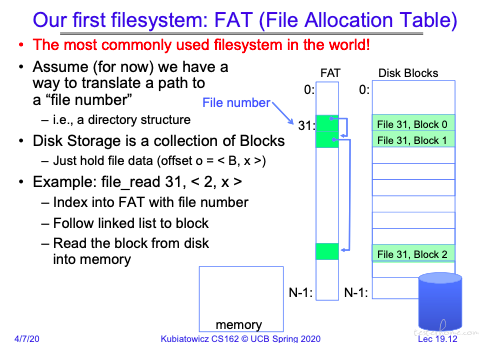
FAT 实现的是一个 block 的链表结构。将相同文件的 block 对应的 FAT 拼接起来。
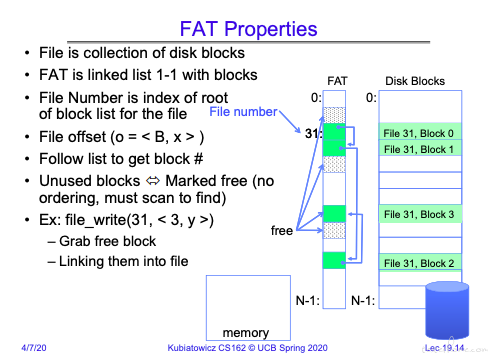
FAT 和磁盘 block 是一一对应的。
可以看到写文件时,会申请一个 block,然后将该 block 对应的 FAT 表项链接到原先文件对应 FAT 的最后一个表项后面。
(问题来了,如果在文件中间擦除 1,2 个字节重新保存,那么难道会有大量的页面需要重新保存么?)
再来看一下创建新文件的例子:
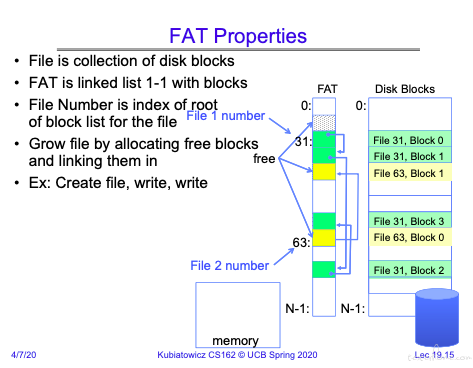
磁盘格式化的操作:
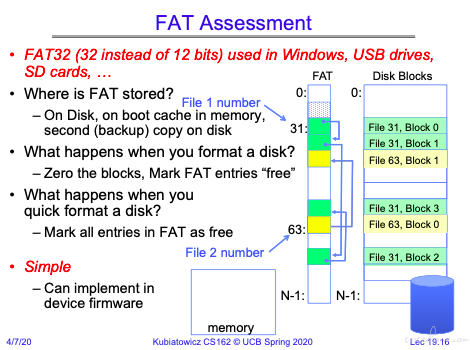
将 FAT 清空,然后有选择的将 disk block 清 0。磁盘固件可以完成,不需要硬件参与。
关于 FAT 的疑问,这真是提问的艺术啊
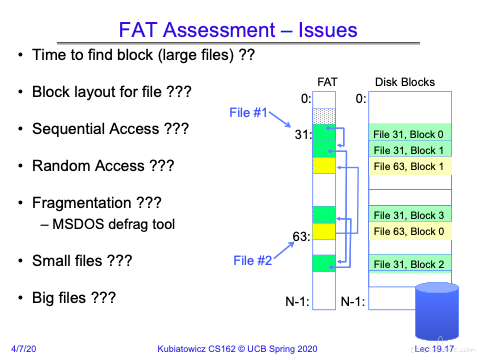

FAT 有严重的安全问题,在于没有访问控制限制。(没有访问控制相关的字段)
从统计学来看文件大小的分布:
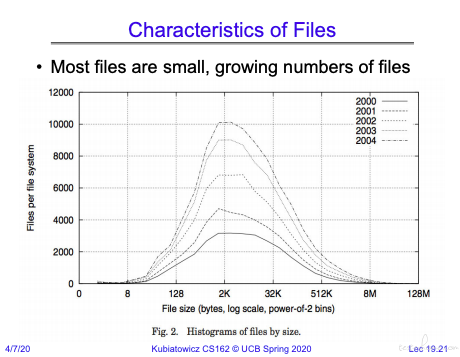
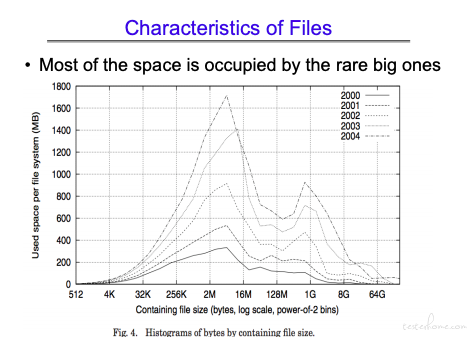
从文件大小来看,2k 左右的文件数量最多。
从占用磁盘的空间来看,2m-16m 占用的磁盘空间更多。
Unix


UCB 么,肯定是主说 Unix 了😄
Inode
首先来看文件节点的多级结构:
INode Array->INode
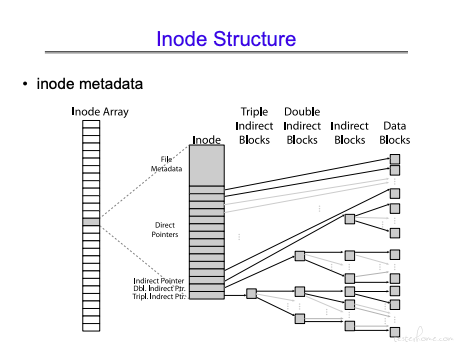
小文件用 direct point.(小文件数量最多,也更快)
大文件用多级 block 连接。(大文件连接非串行,也更容易找到对应的 block).
INode 固定 128 字节。可以存放多个 points.
(这里提到了文件系统的设计用到了 Asymmetric tree,暂时还不清楚多级的具体设计算法)
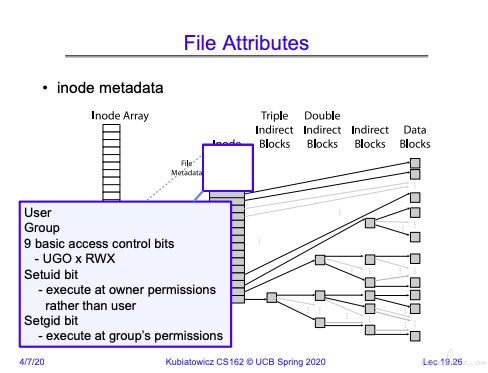
在 Inode 的 Metadata 中放入权限管理。关于 Unix 的权限管理,不多说了。
可以看到文件 block 存储方式。
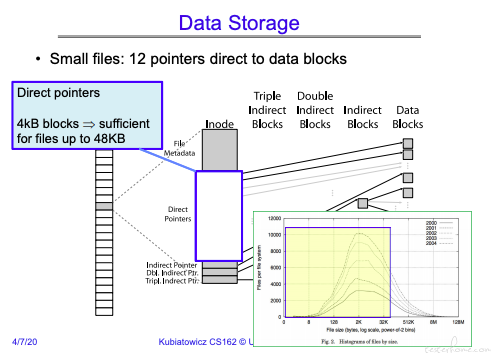
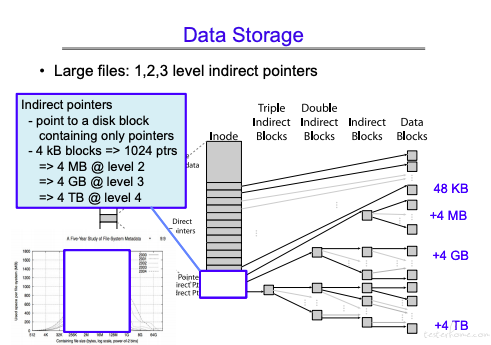
需要解决的问题:
- 存储文件大小变更的情况(添加等操作),在 cs262 中介绍 FFS,解决这个问题。
- 磁头是在一直转的,如果错过了一个 Sector,等转回来需要比较长的时间。这是需要解决的。
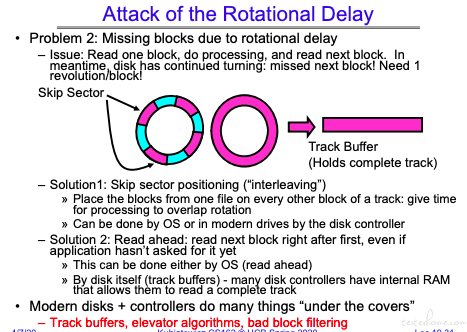 我喜欢缓存的方案。delay 不可控,有波动。
这里还提到:现代的设备,控制器已经做了很多事情,有时候问题会出现在 os 做了多余的优化。
我喜欢缓存的方案。delay 不可控,有波动。
这里还提到:现代的设备,控制器已经做了很多事情,有时候问题会出现在 os 做了多余的优化。
和硬件相关的 os 结构:
开始的时候 Inode 放在磁盘的最外面。后来和上级目录放在同一个柱面中,这样可以加速访问。

一个柱面,由多个 Block Group 组成。可以看到这里每个 block groups 都有自己的 inode 和真实数据文件。

还是为了实现目标 inode 和真实地址要更加接近,减少开销。

磁盘有 10% 的资源会被保护起来。超级用户可以继续用,但是会极大的降低性能。
FFS
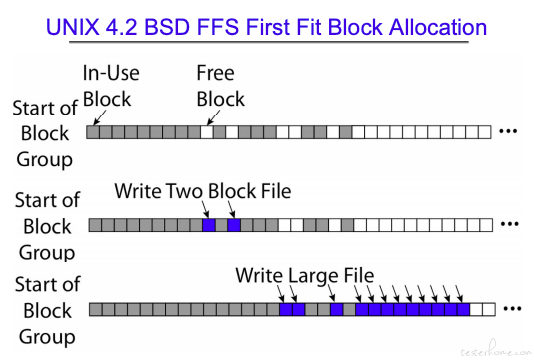

可以有效减少碎片。
不足:
- 小文件也需要一个 Inode.
- 对于连续的文件,记录的 block 状态会比较复杂。
- 需要保留 10%-20% 的空间用于处理碎片化。
Linux ext
Ext2/Ext3 结构:
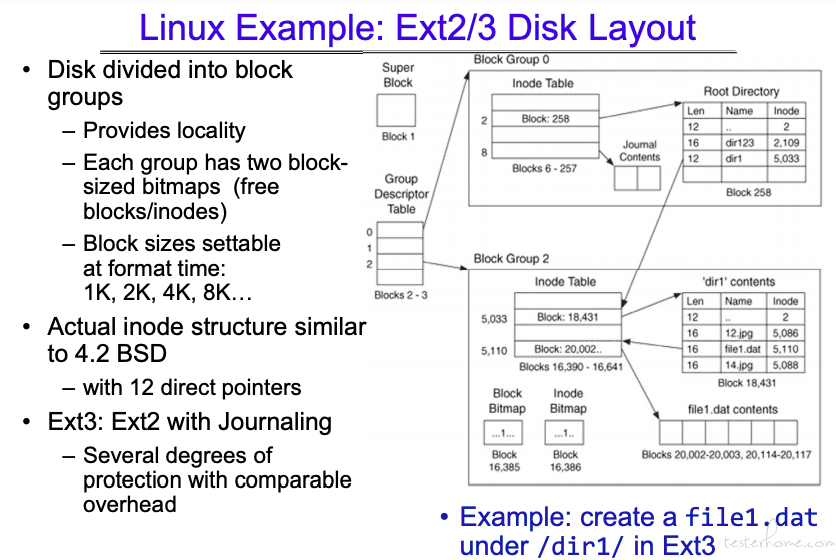
这里 Inode 结构和 Unix 的基本一致。(我看是一样啊,0 级也没区别,都是 12 个。)
主要区别在于:Unix 用全局的 Inode Array 记录信息。(os 层面)
Linux 则是按照硬件的层面去划分 divice group。
那么问题来了,如果超大文件跨 divice group,怎么保证文件连续性呢?(只管理文件起始地址?)
软链接:

因为软链接的缘故,所以 Linux 的目录是一个 DAG(有向无环图)

目录结构:
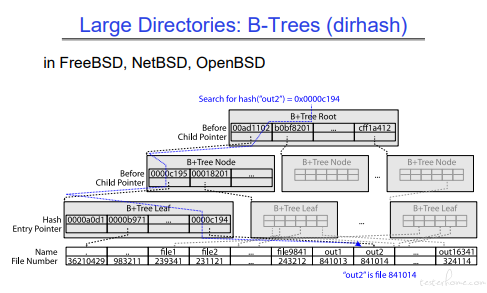
如果目录下文件数量过多,可能会稍慢。
NTFS

Windows 主推的文件格式。我台式机的磁盘一般就用这种格式。
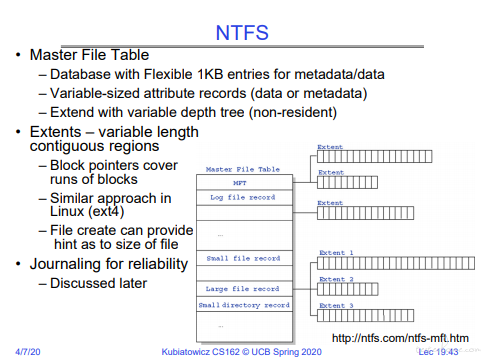
有日志可以保证安全。
能看到文件的大小。
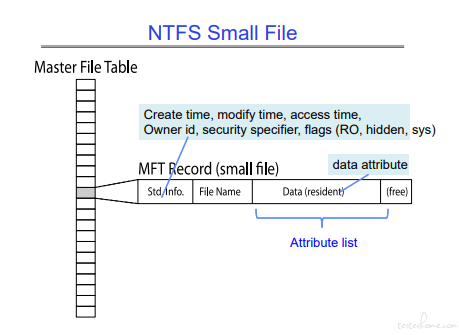
小文件可以放到目录文件的数据中去。(实测有效,1 字节文件,占用 0 字节)
中等文件格式:
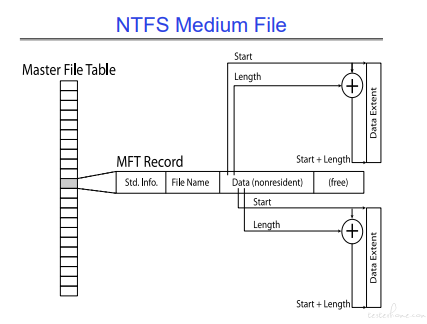
start+length
大文件格式:
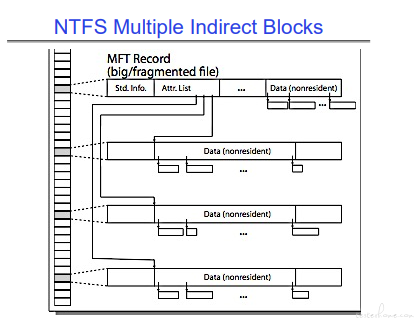
NTFS 是有碎片化的问题。
内存映射

把文件映射到内存,可以加速。
可执行文件就是这么做的。
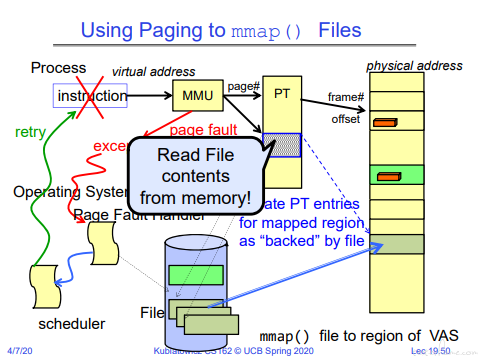
当 mmap() 需要把文件映射到内存时,首先在 page table 创建对应的页表,对应文件。
当访问这个页表时,会发生 page fault,后续流程和内存的 page fault 一致。
内存共享映射:
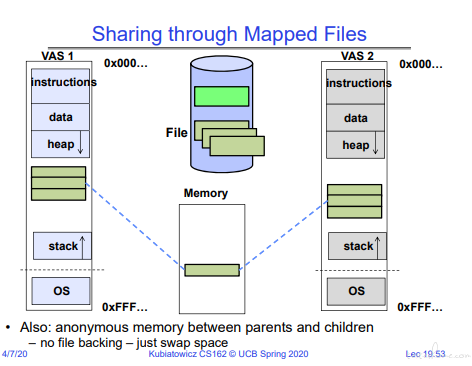
注意写锁~~~
buffer cache 结构:
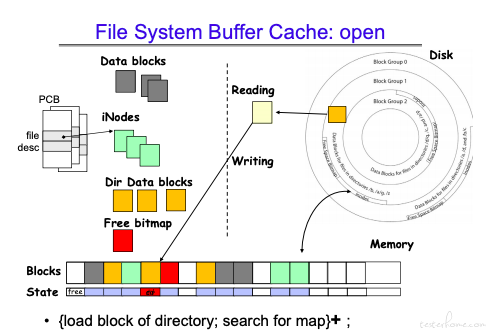
Buffer Cache 有四种类型的数据可以入队,长度都是 4k,策略用的是 LRU。
如:读取数据,先拿到目录 cache,然后获取文件对应的 inode,最后获取数据缓存。
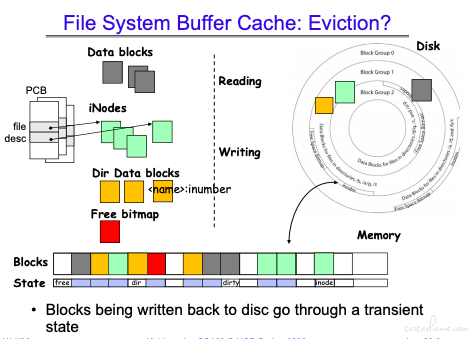
如果在对应的缓冲区里有写操作,那么对应的 cache 状态位会被置为 dirty.
什么时候写回磁盘,前面提过和操作系统相关,UNIX 是 30s.
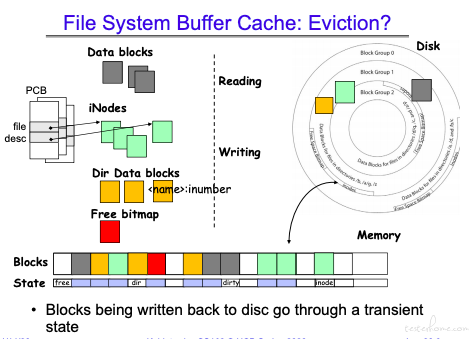
文件系统缓存:

在文件系统中命名转化和磁盘 block 转化都可以用到 cache.
命令转化使用 cache 的效果更好。内存足够大的话,磁盘映射做的也不错。
不过在全局搜索文件时,可能会有些问题。(就没有重复的)

文件缓存和虚存缓存都需要占用内存空间,如何平衡?
预读取和内存一样,读太多浪费,读少了要读多次的问题。

磁盘写回的操作,优势明显,缺点主要在系统崩溃定位上。
ilities

Durability 不等于 Availability。
一个特例:数据一直没有丢失,但是已无人可以解读
持久化

了解以下 NVRAM。
持久化的很多策略也是我们现在真实应用到的策略。
RAID
这部分 CS61C 说的更加细节一些,有兴趣的可以去翻一下。
文件系统稳定性

RAID 对于暂态的数据并没有保护能力。因此需要最小系统保证在数据错误的情况下,也可以恢复运行状态。
哪些操作会对可靠性造成影响:

中断操作加断电。。。
解决问题稳定性的办法:
方法 1:

尽量让操作有序化。
文件系统有保护机制,部分应用有恢复机制(Emacs、Word)。
这里拿文件创建举例说明了在每一步可以进行的恢复策略:

方法 2:

在未完成操作的时候,新申请未使用的空间做处理。
相对来说是更耗资源的。在网络文件服务中有近似的实现方法。
举例说明:
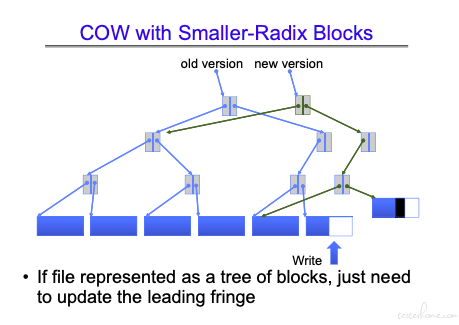
从图中看到新的空间申请新的块实现,然后修改链接完成拼接。
分布式操作系统 ZFS/OPENZFS 用了类似的机制:

更通用的优化方法:

Transactions

Transactions 是原子操作的拓展。(原子操作是体系结构里的东西,和硬件相关。这里 Transactions 更多的是纯软件概念。)
前面 FFS 顺序回退的流程也可以认为是一种手工的 Transactions 实现方式。
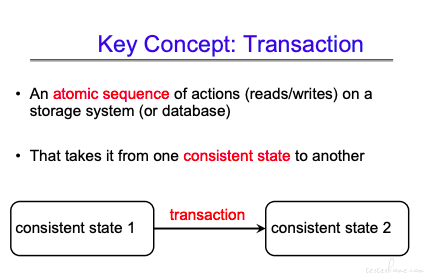
其核心思想是从稳态 1 到稳态 2,要么所有操作都操作成功,切换到稳态 2.要么就维持稳态 1,不允许出现中间态。

可以看到回滚是很重要的。
PS:如果有过后端的经验,应该知道在业务逻辑中会有各种回滚
log
ext2 和 ext3 的区别在哪?log!
这里将多个 Transactions 认为是一个原子操作,当这个大的原子操作成功后,一次提交
这里以文件创建为例,说明实现的方式:
没有 log 的文件创建方式:
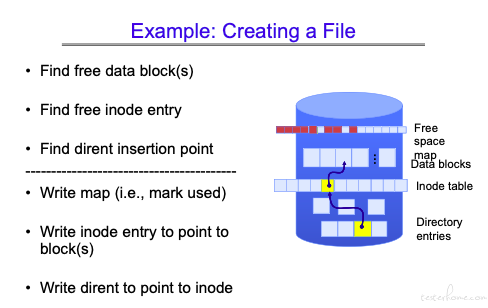
有 log 的文件创建方式:
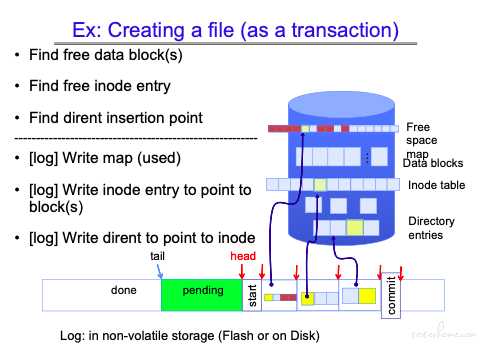
这里需要关注两个指针:tail 和 head,tail 指向以完成全部操作(包括存盘)的日志,head 指向的是当前未提交操作的队头。
可以看到 tail 和 head 之间有一块 pending 区域
对于 Pending 区域的数据,当 crash 发生,重启后,会重新执行 pending 里的操作。
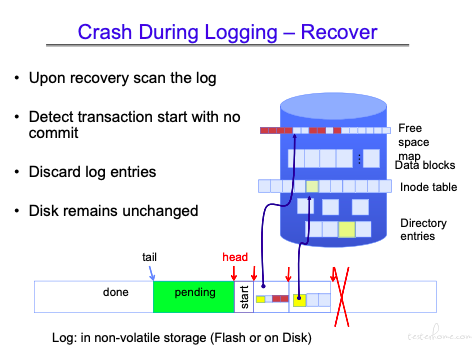
如果在 commit 之前就发生了异常,那么会将 head 之后的日志清除。
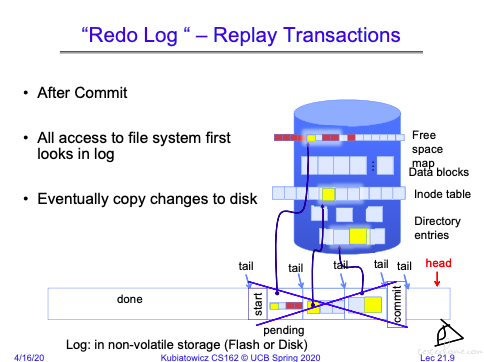
Journaling

日志是全局保存的,存储数据块的成本相对来说并不低。因此还提供了只保存文件 metadata 修改的选项。

文件日志服务应该算是系统中生命周期很长的任务,需要对磁盘文件进行实时的维护。
除了系统本身,并没有太多存储用日志文件系统。如数据库只有事务管理用日志,数据存储本身并不使用。
Flash 由于其本身的一些特质,需要独立设计文件系统(不仅仅是下面的这种文件系统)

具体论文不看了,晕。。。
关于 Journaling 可以参考:
https://blog.csdn.net/dongkun152/article/details/80794903
总结

理解磁盘的基本结构,理解目前主流的文件系统概述。
理解文件的基本结构(目录结构,文件属性等),理解从名字到系统资源的转化,理解 inode 数据结构,理解大文件多级 block 的设计。

了解添加文件等基本操作对应的文件系统操作。理解内存可以对 block 进行缓存加速执行效率。知道存在定时写回机制。

理解事务和日志的基本实现方式。理解日志文件系统存在的意义和实际操作方式。
ps:三讲下来也仅仅是个概述,要真正理解还得读论文,读代码 。
。