
地址转化
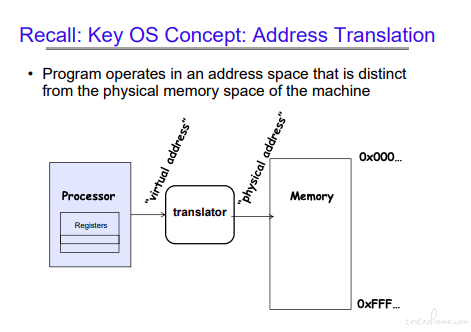
关于内存需要注意如下的几个方面:

地址是需要翻译的,这里用的是 mips 指令举的例子:
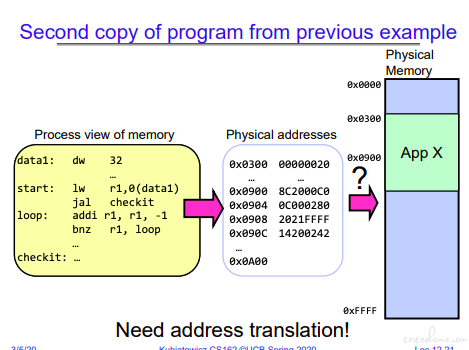

程序执行流程:

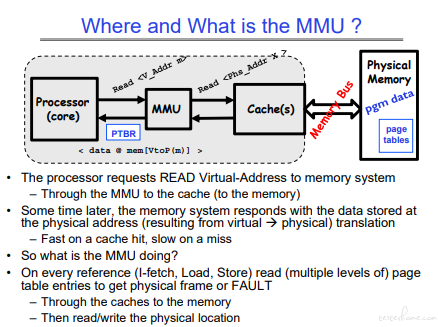
MMU(Memory Management Unit)
地址转化可以对程序间进行保护。

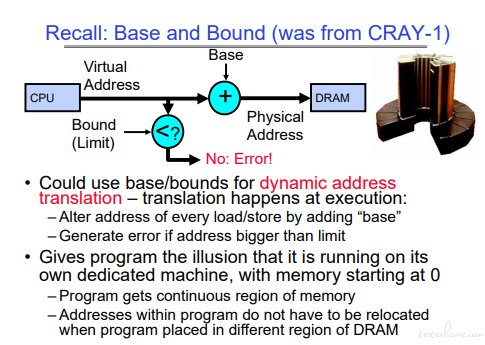
简单的 Base & Bound 存在问题,这也是引入分段,引入虚拟内存的原因之一。
内存分段
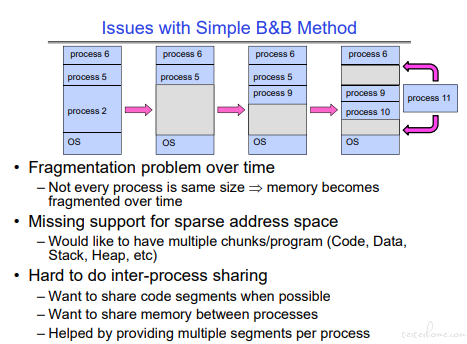
内存分割示例:
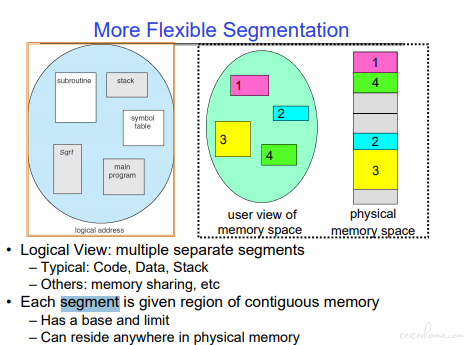
当超出申请空间的情况,就会出现 segment fault。如果熟悉 C/C++,应该对段错误不陌生。
从虚拟内存到实存:
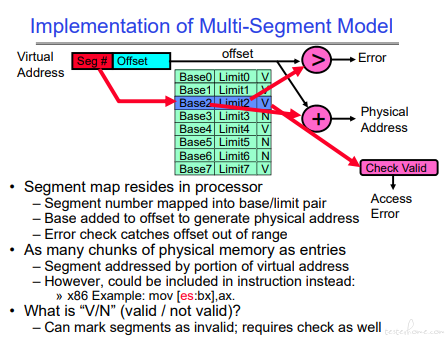
转化需要判断:1.是否越界 2.内存是否有效
MMU 是处理器的单元,虚存到实存的转化也是在处理器中实现。所以绿色的这张表也存放在处理器中。
一个 16bit 分段内存的示例:
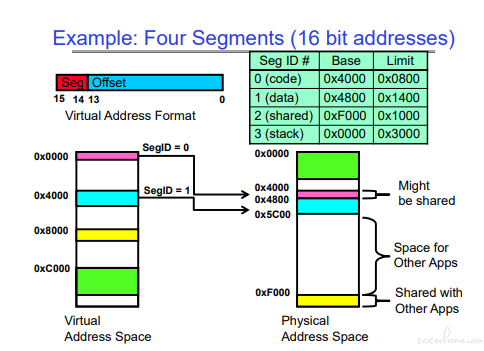

在处理器中,只有读写内存的操作需要处理实存数据(实际上处理寄存器,虚存地址转实存地址放寄存器)。
其他跳转等都是虚拟内存空间。(处理器,做虚存到实存的地址转化。缺页由操作系统生成页表,然后由页表对应实存。)
分端总结:

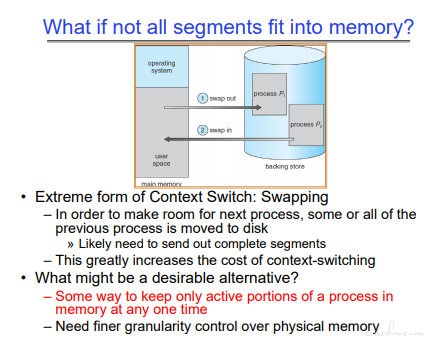
PS:如果 Linux 装的多的朋友,应该知道装机的时候需要分配一部分硬盘空间做 swapping.
分段在资源利用和碎片化上存在一定的问题。

内存分页

为了减少移动开销和碎片化的问题,使用固定大小的页来存储内存。但这样将同时管理多个分页,而不是管理少量的段。

注意,段表是放在处理器中的。页表每个进程是独立的,页表存放在物理内存中。
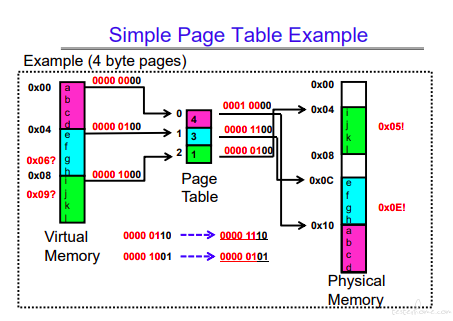
一个简单的通过页表将虚存转化成实存的例子:
内存共享
当有了分页以后,分页的页表由每个进程独立维护,那么意味着多个进程的虚拟内存可以对应相同的物理实存。
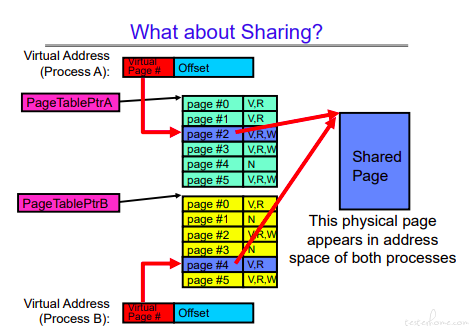
这里分 4 种情况分别论述:

1.内核态可以访问所有用户态的页面,做好用户态到内核态切换即可。
2.如果两个进程运行相同的库,只做执行,代码空间不会进行复制。
3.共享库,共享库完成数据共享、交互。
4.使用共同的物理内存。1 个进程里的多个线程共享用的就是这种方式。多进程的情况下,有文件、socket、system call 等多种方式申请共享内存。
基于安全的内存分配考量:
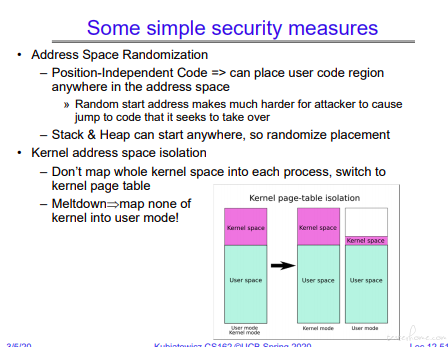
个人只简单了解了一下。
示例:
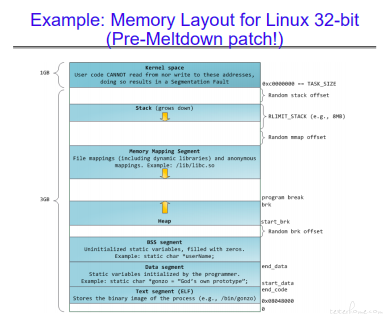
stack 内存申请实例:
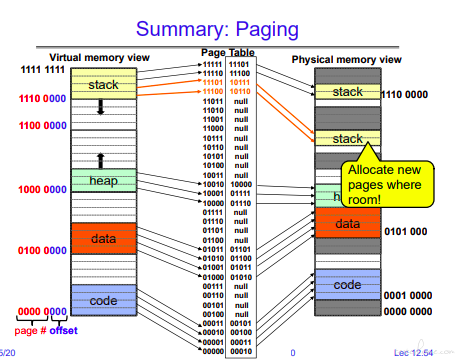
page table 的大小:

64 位就会非常大,大部分页表都是无效的,因此 64 位需要使用页表分级。
简单分页讨论:

页表在上下文切换的时候需要保留且不能修改。上下文切换的时候页表指针会根据进程的不同和用户态/内核态的不同指向不同的地址空间。
分级页表
32 位的 10+10+12 的两级页表。
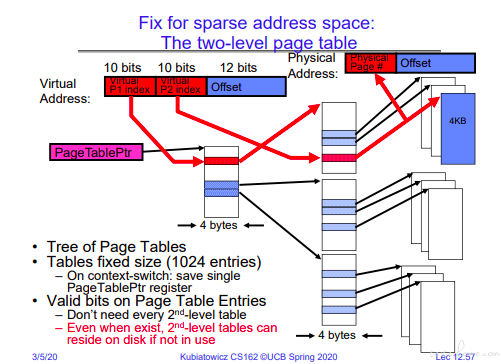
对于分级页表的核心思考在于,不使用的二级页表不会生成对应的存储空间,可以解决单级页表稀疏化的问题。
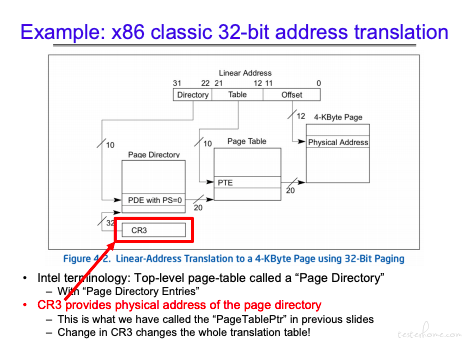
关注一下 CR3,在进行上下文切换时,这个寄存器会产生作用。
PTE
多级页表的每个条目是一条 PTE。

PTE 的使用:

多级分页共享
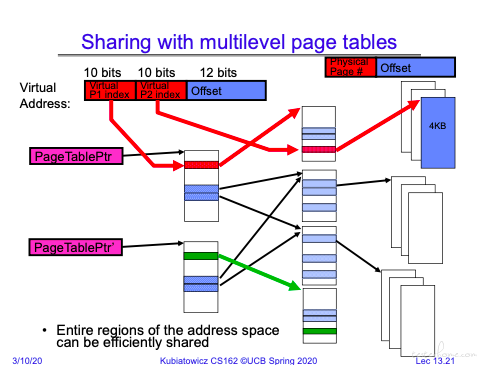
相对于单级分页,可以在每一级进行共享。
如上图所示,两个进程的 1 级页表指向了同一个二级页表,那么这个二级页表内的所有内存资源都是可以共同访问的。
多级页表示例:
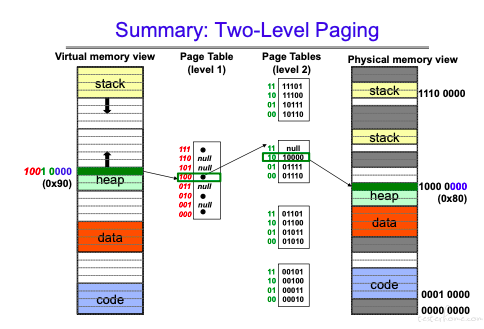
多级页表分析:

整体看分段、分页
回来看多模切换

整体流程表:
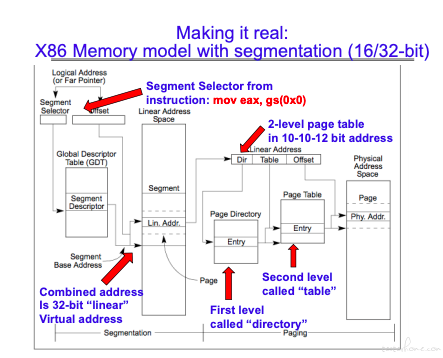
逻辑地址通过 GDT(global descriptor tables)转化成虚存地址,然后再通过页表转化成实存地址。

关于 GDT/LDT 的理解可以参考https://www.techbulo.com/708.html,也是利用分级的思想。
64 位 X86 的页表
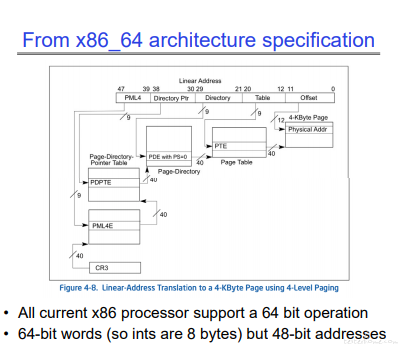
4 级页表,每级 9bits,共 48bits。
反向页表
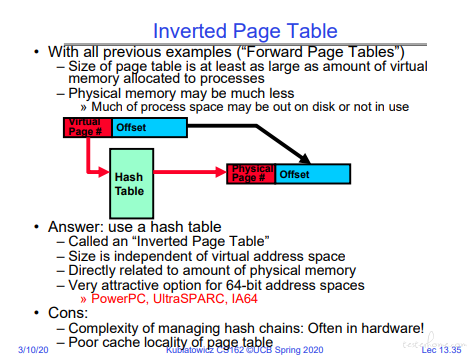
不常用,可扩展性偏弱。
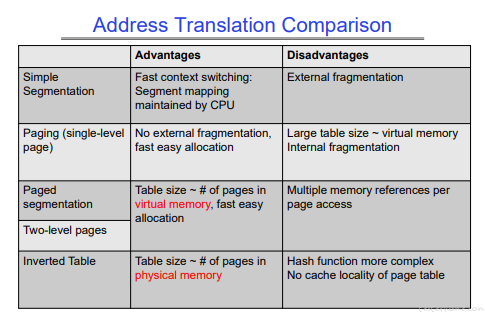
地址转化方法比较
整理来看 MMU

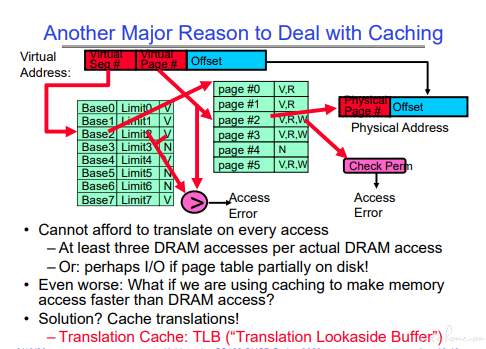
页表的 Cache

地址转换的 cache->TLB(Translation lookaside buffer)
页表总结:

缓存
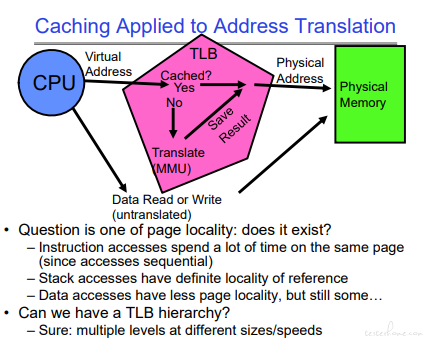
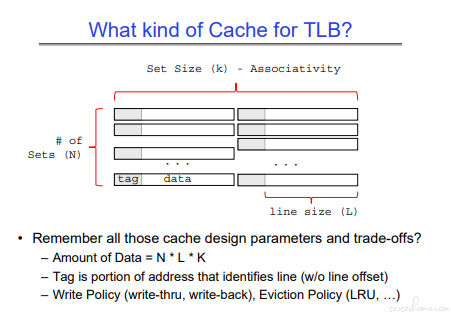
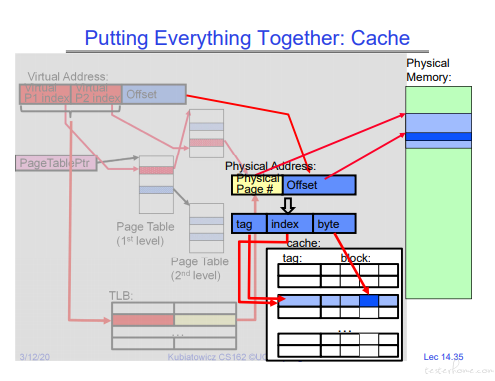
可以看到 TLB 的 CACHE 和内存的 CACHE 结构是一致的。
内存的 cache 基础( Direct Mapped Cache、 Set Associative Cache、Fully Associative Cache)请移步 CS61C。
从操作系统的角度来看 cache:

这里视频提到了false sharing,false sharing 涉及 cache 一致性,涉及 emsi 协议,基础的内容请移步 CS61C。
可以参考:
https://www.zhihu.com/question/307351068/answer/576670796
这个回答。
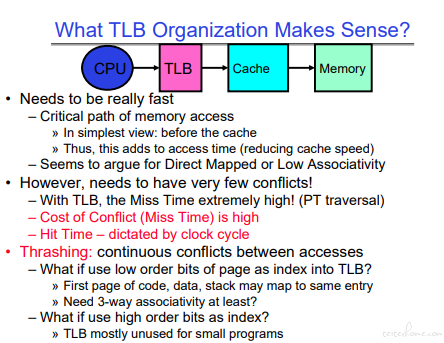
TLB 的索引是高字节,对于小程序来说不会使用 TLB。
TLB 使用的是 Fully Associative Cache,结构如下:

TLB 的执行过程在指令执行中进行。

TLB 和 cache 的地址示例:
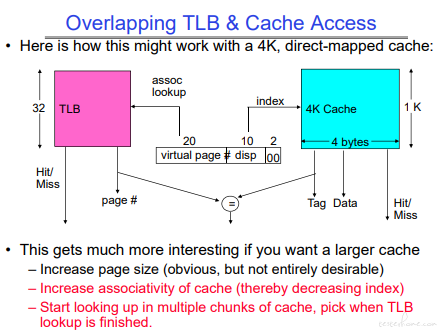
TLB 实例:


现代 CPU 的 cache 和 TLB:

上下文切换需要实现的内容:

# 总结:
页表:
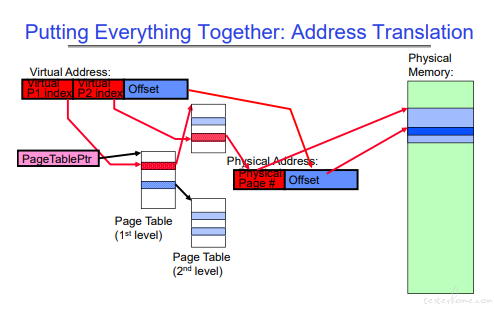
TLB:

Cache:
我个人觉得 L12-L14 的这四讲,从分段->分页->多级分页->地址转化整体(逻辑地址->虚拟地址->物理地址)->TLB->Cache->TLB 实现
通过一个一个问题,把设计思想抽象了出来。
计算机组成原理如果没有一定的认知,这章会很难理解。