
L2.1 Intro to Dist. Memory Model
近似的消息交互时间:
latency, units of time, it is a fixed cost no matter how α = large the message.
β = inverse bandwidth, units of time/word .
n = number of words
Tmsg(n) = α + βn
Kway congestion reduces bandwidth
k= the number of messages competing for the same link
Tmsg(n) = α + βn k
通常情况下 α是 10 的-6. β是 10 的-9
树形结构处理的伪代码:
let s = local value
bitmask ← 1
while bitmask < P do
PARTNER ← RANK ^ bitmask
if RANK & bitmask then
sendAsync (s → PARTNER)
wait()
break //one sent, the process can drop out
else if (PARTNER < P)
recvAsync(t ← PARTNER)
wait()
S ← S + t
bitmask ← (bitmask << 1)
if RANK = 0 then print(s)
树形结构的传递时间:(α + β * n) log P
流水线的传递时间:αP + βn
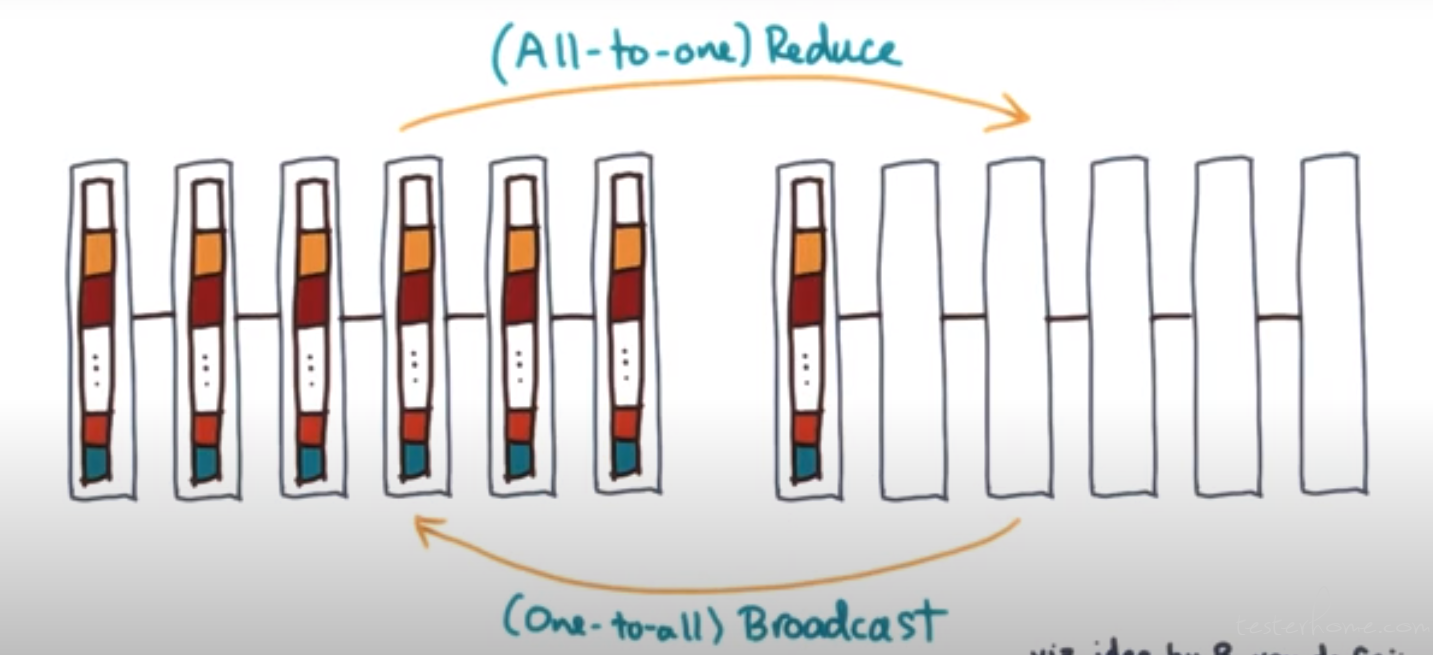
提供的 Collective Operations:
Reduce<->Broadcast
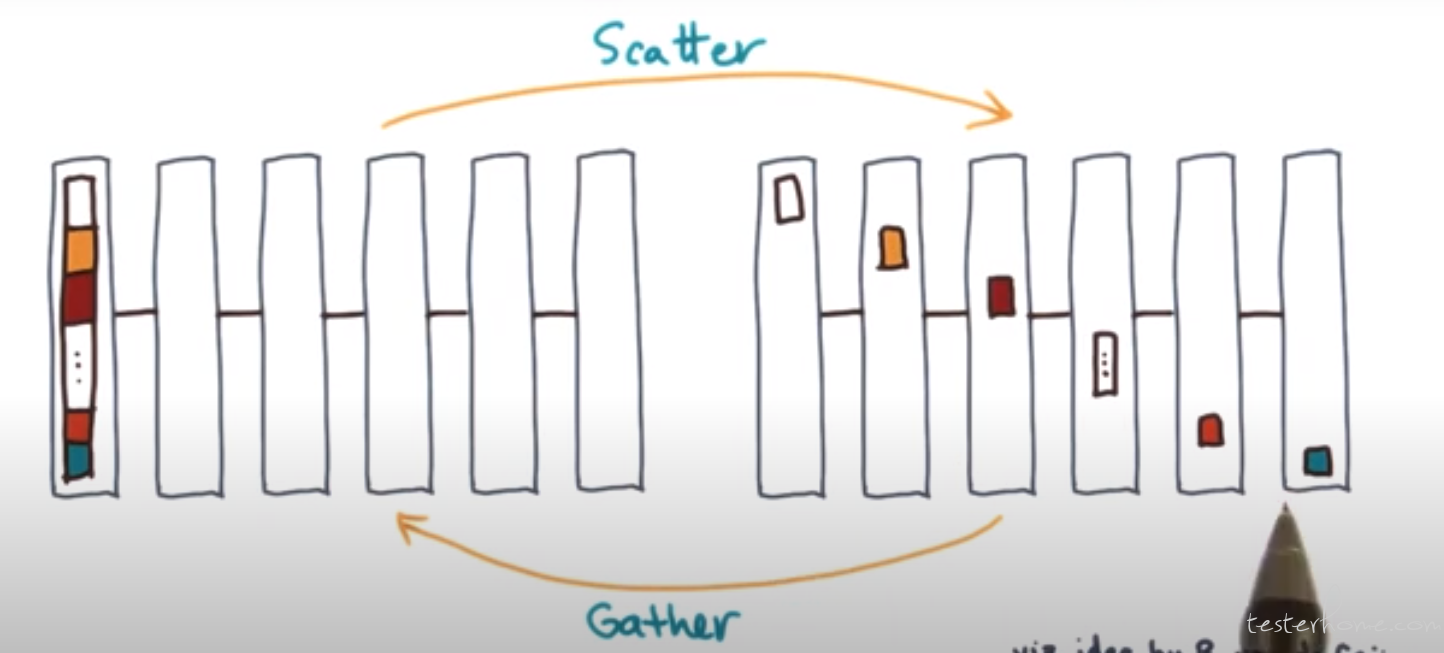
Scatter<->gather
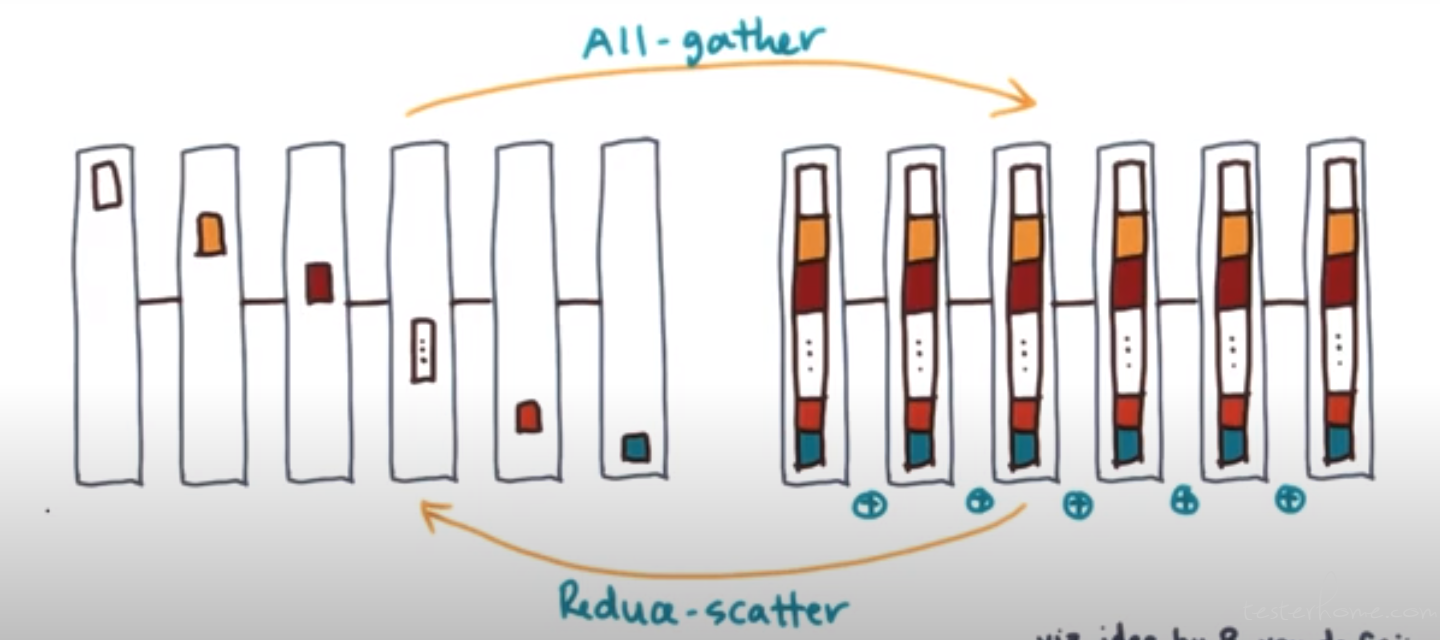
Allgather<->Reduce-scatter
具体解释如下:
One-to-All Broadcast:onenode has information and all other nodes get a copy of it.
Scatter → one process starts with the data, then sends a piece of it to all other processes.
The dual of a scatter is gather.
Allgather → each process has a piece of the data. The data is gathered and every process
gets a copy of all the data.
The dual of allgather is reducescatter.
Reducescatter: the processes contain data that is reduced to one vector. This vector has
pieces that are then scattered to all other processes.
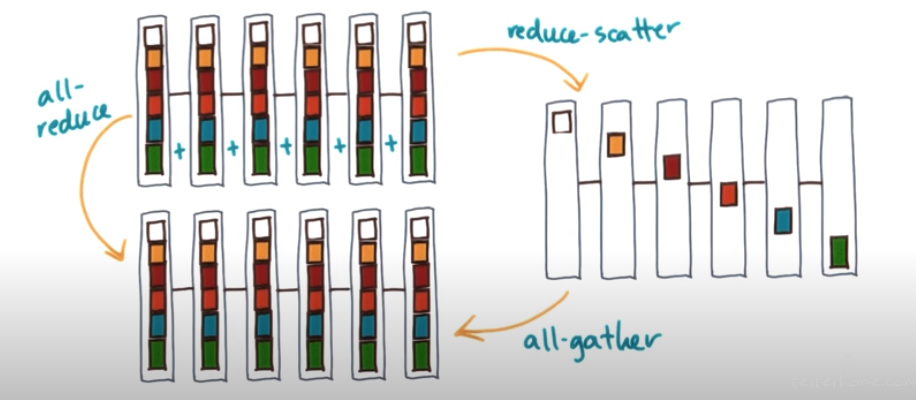
AllReduce
Use reducescatter and allgather
L2.2 MPI
MapReduce 的时代,暂时不知道 MPI 具体在哪用。
文档:
https://computing.llnl.gov/tutorials/mpi/
关于集合算子,可以参考:
https://www.cnblogs.com/cuancuancuanhao/p/8438608.html