
从 Demo 中学习

为了方便讲述,我临时糊了个较为简单的 pipeline,效果如上图 (需安装 blue ocean 这个插件)。 准备工作也很简单,安装个 jenkins 2.x,在插件管理中下载 pipeline 相关插件即可。 创建一个 pipeline job 然后贴入如下代码:
library 'qa-pipeline-library'
pipeline{
agent{
label 'devops'
}
}
stages{
stage('环境部署'){
steps{
echo 'deploy'
}
}
stage('拉取测试代码'){
steps{
checkout([$class: 'GitSCM', branches: [[name: '*/release/3.8.2']], doGenerateSubmoduleConfigurations: false, extensions: [[$class: 'LocalBranch', localBranch: 'sage-sdk-test']], submoduleCfg: [], userRemoteConfigs: [[credentialsId: 'gaofeigitlab', url: 'https://gitlab.4pd.io/qa/sage-sdk-test.git']]])
}
}
stage('sage sdk 测试'){
steps{
sh """
pip3 install -i http://pypi.4paradigm.com/4paradigm/dev/ --trusted-host pypi.4paradigm.com 'sage-sdk[builtin-operators]'
pip3 install -r requirement.txt
cd test
python3 -m pytest -n 5
"""
}
}
stage('生成测试报告'){
steps{
allure commandline: 'allure2.13.1', includeProperties: false, jdk: '', results: [[path: 'test/allure-results']]
}
}
}
post{
always{
sendEmail('sungaofei@4paradigm.com')
}
}
}
pipeline 语法分别指令式和脚本式。 上面是指令式的 demo, 是入门 jenkins pipeline 的首选。 指令式有点想咱们测试领域的关键字驱动一样, 它事先实现了很多有用的指令。所以对新手十分友好,学习成本很低。缺点是跟没有办法在脚本中灵活的应用 groovy 语言,换言之就是在脚本中使用 groovy 是有限制的。 而脚本式相反, 优点是可以在脚本中肆意插入 groovy 代码,怎么都行。 但毕竟学习 groovy 语言有成本,而且不能只用声明式的那些好用的指令。 所以声明式是大部分人的首选。
流程解释
我没打算像官方一样一个指令一个指令的讲起,那样需要太多的篇幅我实在没精力。 所以我打算用另外一种方式来讲解。 指令式 pipeline 很好入门,因为在它的每一个指令几乎都可以 UI 上找到对应的地方,可以说它在流程框架上大致上是保持跟 UI 是一样的。 比如在上面的 demo 中, 在 pipeline{}的基本估计下。我们来屡一下。
最开始的 agent 'devops' 设置任务运行在哪个节点上。对应在 UI 上如下:

而最后的 post{} 其实就对应着 UI 上的构建后操作, 负责在任务结束后处理善后工作,比如发邮件,生成报告等等。 post{}下面 也对应着 UI 上的操作有 always, success, failed 等等其他指令, 意思分别是是一直触发这些善后工作。还是只有在成功或者失败的时候触发。 中间的 stages 指令负责执行真正的任务。 stages 下面又有很多个小 stage,负责一个一个阶段的运行。 所以一个指令式的 pipeline 的简述流程是:
pipline{
agent{}
stages{
stage{}
}
post{}
}
这样在 stages 中我们就可以通过一个一个的指令开始执行我们的任务, 比如在上面的 demo 中。 通过在 stage 下的 steps 里执行 checkout 指令。如下:

这就是在用 checkout 指令来从 gitlab 上拉取代码。 又比如下面在执行的 allure 指令, 是为了生成 allure 的测试报告。如下:

所以这样一看,我们实现一个 jenkins pipeline 其实就比较简单了, 在这样的流程框架下去使用一个又一个指令就可以完成我们的 pipeline 了, 当然这其中还有一些控制流程分歧和其他参数的指令,他们也很重要, 但我再这里就不在一一描述了。 可以移步官方文档:https://jenkins.io/doc/book/pipeline/shared-libraries/
当然 jenkins 上有那么多功能,那么多插件, 每一个插件对应一个指令,这么多指令学习起来太麻烦了。 所以 jenkins 也给我们开发了一个自动生成指令的工具。 如下:
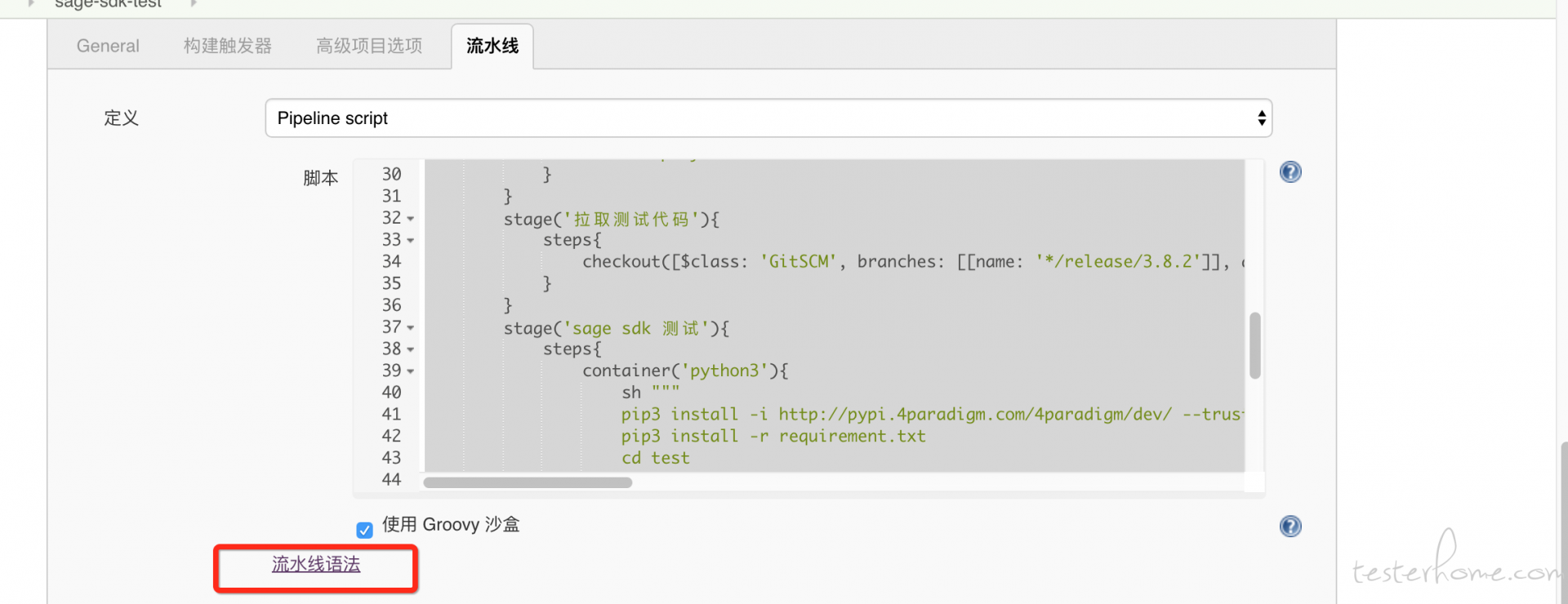
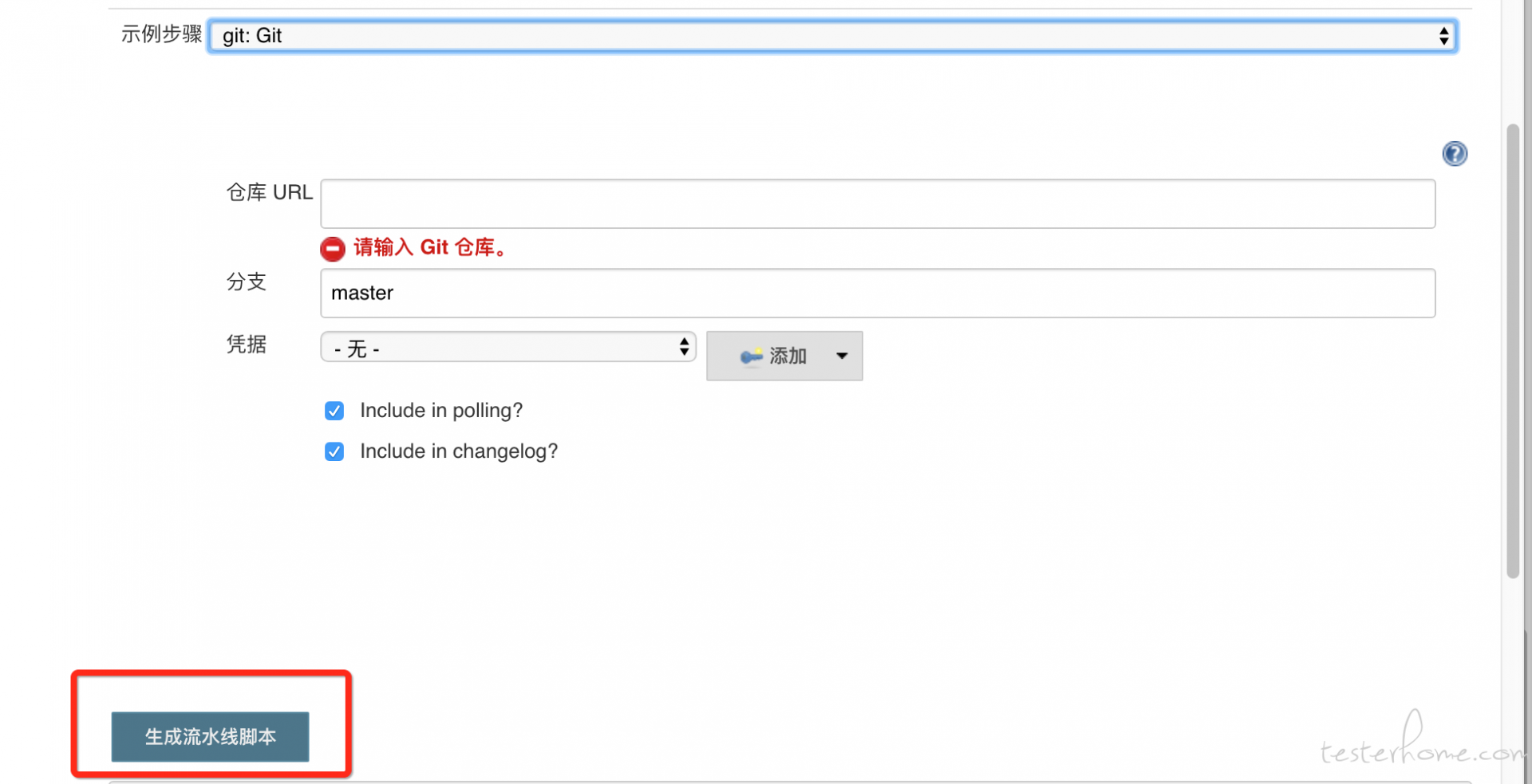
如上, jenkins 会帮我们生成对应的指令代码。
shared library
基本部分我就不多讲了, 精力实在不够。 接下来就讲如何编写一个共享库。随着 pipeline 流水线技术的成熟,使用 pipeline 脚本的 job 也迅速增加。虽然我们可以做一个尽可能通用的 pipeline 脚本样例,让搭建者只需要修改几个赋值参数就可以在自己的项目中应用,初衷是希望所有人能理解 pipeline 中的过程,但也发现一些比较麻烦的问题,比如有些人不熟悉具体的脚本拿来随意删改导致各种错误,还有就是我们在 pipeline 脚本中增加一些新功能时又需要通知所有的 pipeline 维护人员去修改,过程非常纠结。这时候就意味着我们需要用到 pipline 的共享库功能(Shared Libraries)了,在各种项目之间共享 pipeline 核心实现,以减少冗余并保证所有 job 在构建的时候会调用最新的共享库代码 。
目录结构
Shared Library 通过库名称、代码检索方法(如 SCM)、代码版本三个要素进行定义,库名称尽量简洁,因为它会在脚本中被调用,在编写 Shared Library 的时候,我们需要遵循固定的代码目录结构。
Shared Library 代码目录结构如下:
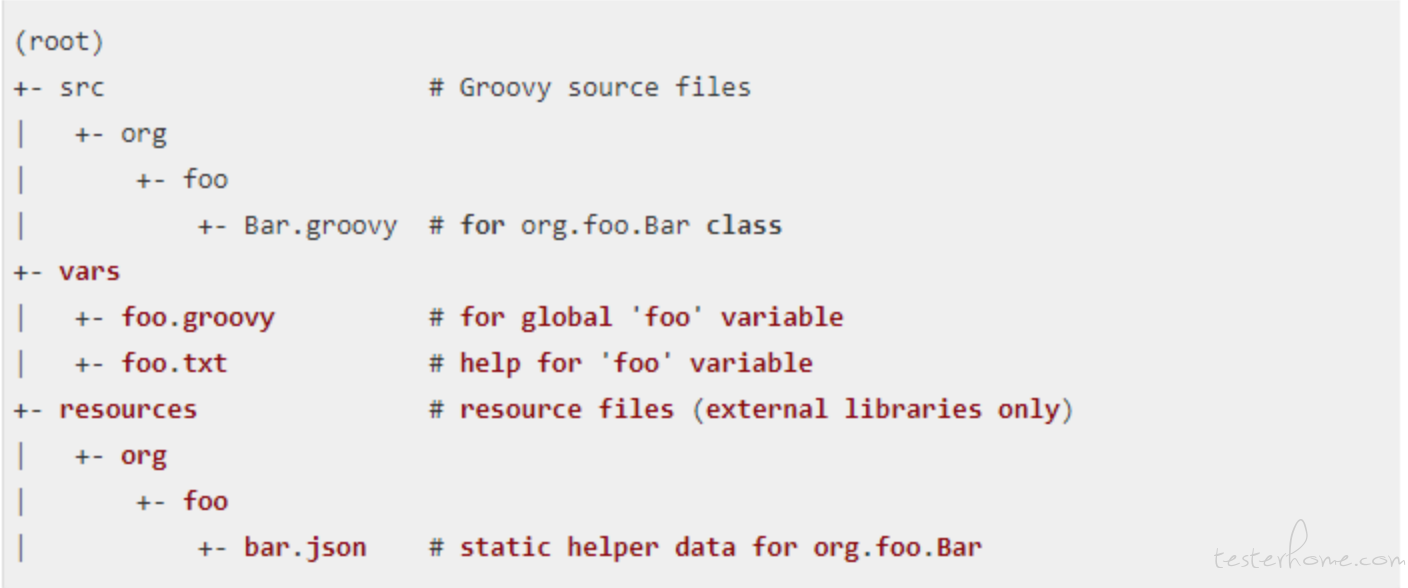
src 目录就是标准的 Java 源目录结构。执行 Pipeline 时,该目录将添加到 classpath 中。
vars 目录托管定义可从 Pipeline 访问的全局脚本 (一般我们可以在这里编写标准化脚本)。 我们在 pipeline 中调用的指令就是在这里定义的, 这是我们最重要的目录。
resources 目录允许 libraryResource 从外部库中使用步骤来加载相关联的非 Groovy 文件。也就是我们的 pipeline 脚本是可以通过一个代码来加载 resource 目录下的文件
定义全局库
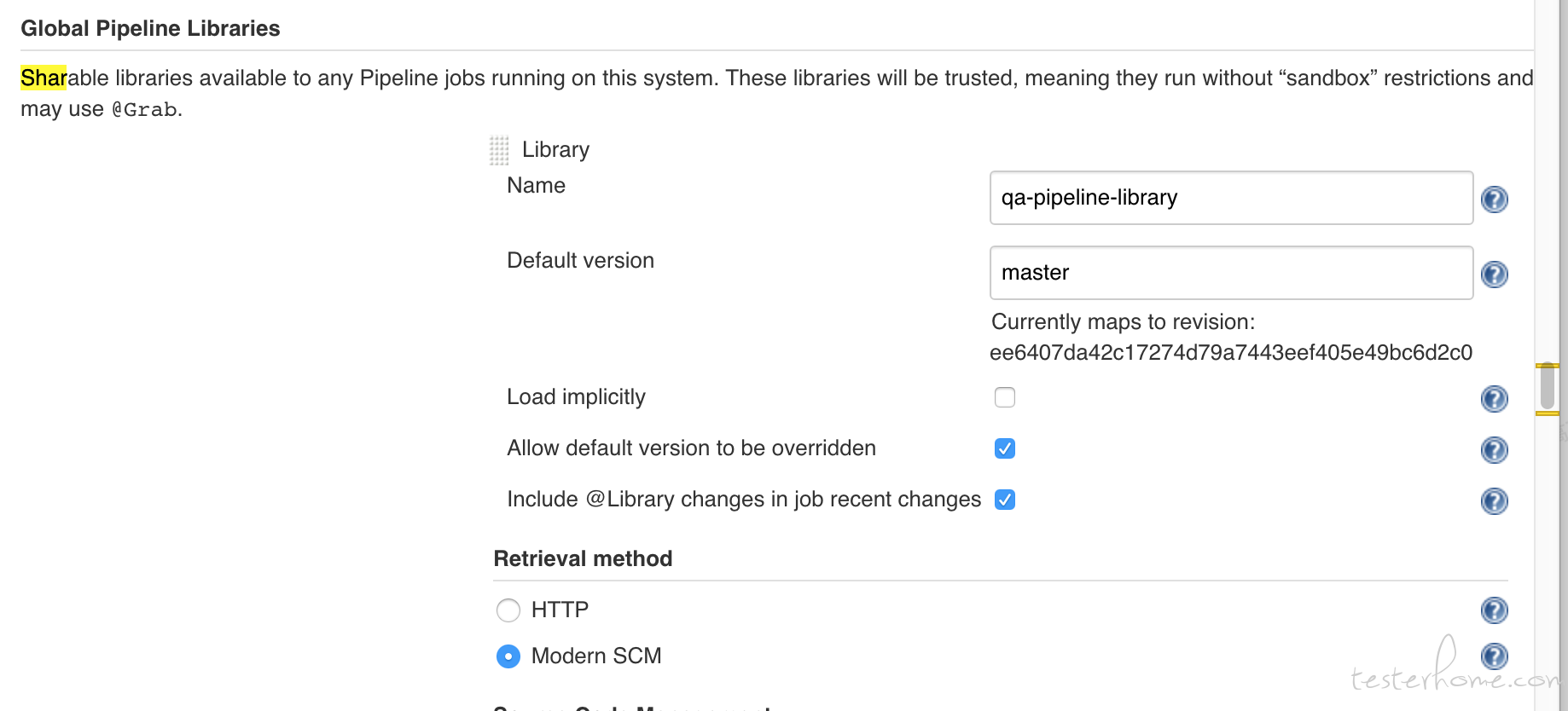
这里只介绍全局 Shared Library 的方式,通过 Manage Jenkins » Configure System » Global Pipeline Libraries 的方式可以添加一个或多个共享库。
这些库将全局可用,系统中的任何 Pipeline 都可以利用这些库中实现的功能。并且通过配置 SCM 的方式,可以保证在每次构建时获取到指定 Shared Library 的最新代码。
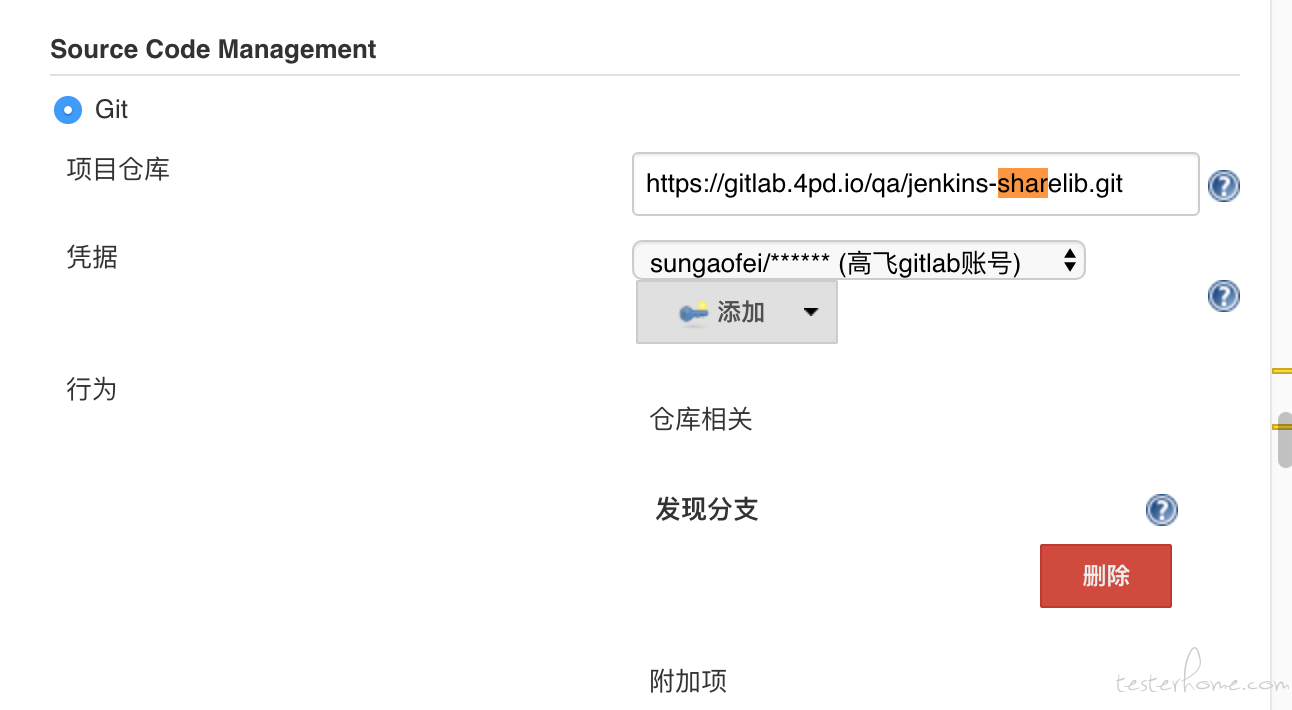
动态加载库
从 2.7 版本起,Pipeline: Shared Groovy Libraries plugin 插件提供了一个新的参数 “library”,用于在脚本中加载(non-implicit)库
如果只需要加载全局变量/函数(从 vars/目录中),语法非常简单:
此后脚本中可以访问该库中的任何全局变量。
library 'qa-pipeline-library'
Shared Libraries Demo
我们还是通过一个 demo 开始吧。 注意这里方法名字必须是 call。 这里涉及到了 groovy 语言的委托机制, 所以名字必须是 call。
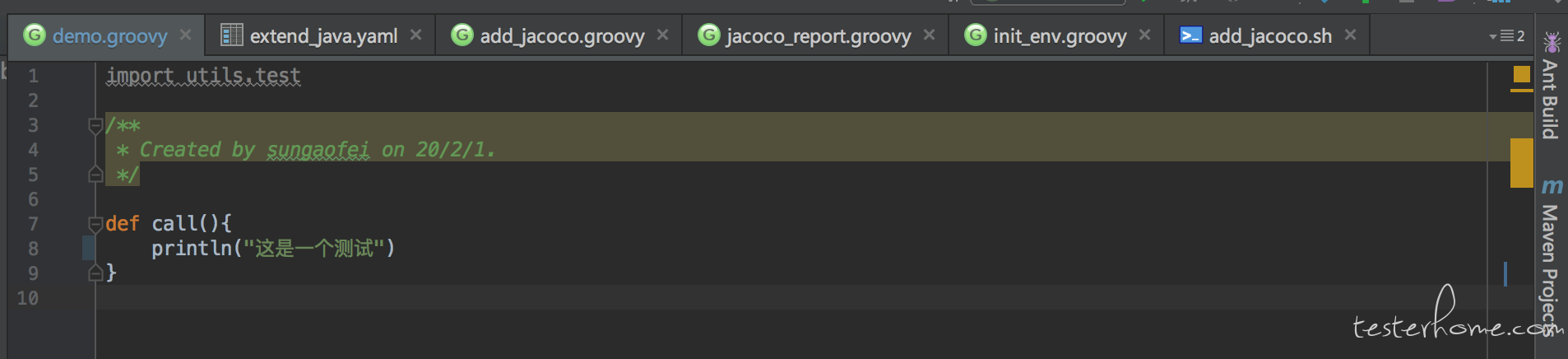
然后在我们的 pipeline 中我们可以向下面这样调用。
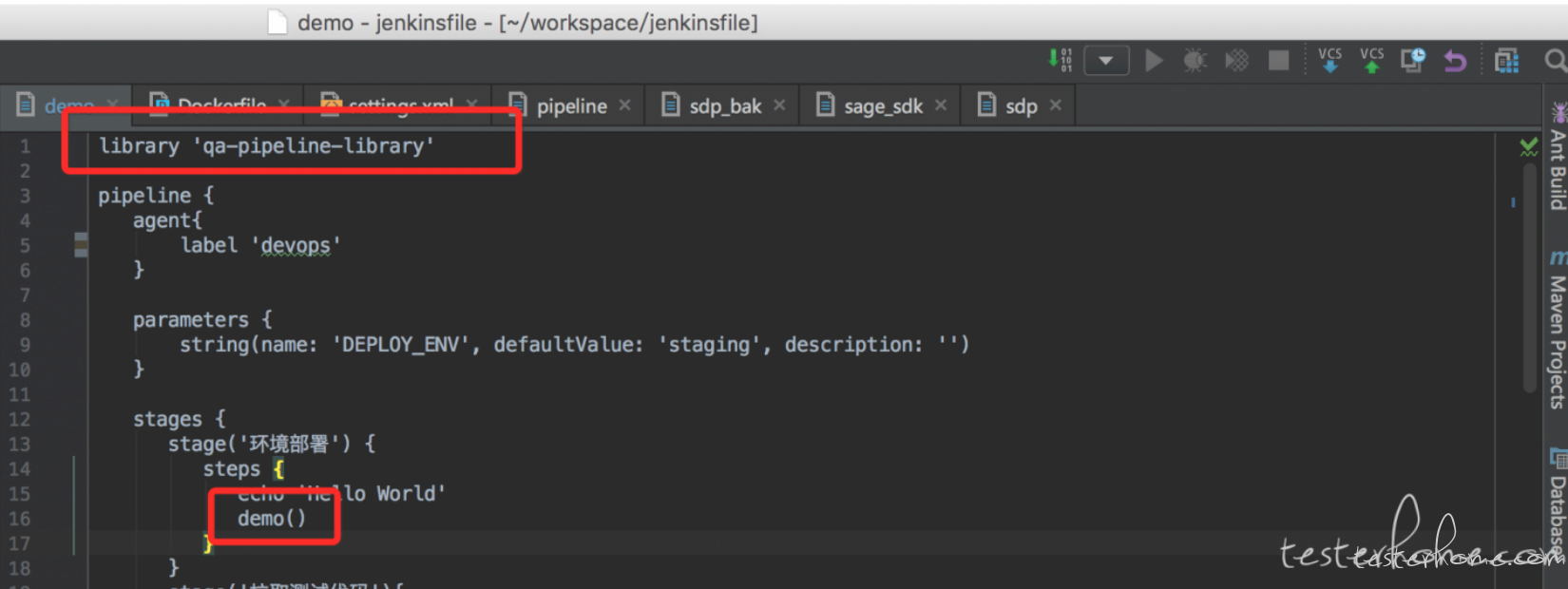
我们只要在 pipeline 上面使用 library 'qa-pipeline-library' 就可以在下面的 steps 里直接调用 demo 方法了。
如果想要 load 一个文件, 则可以使用
libraryResource 'k8s/template/java.yaml'
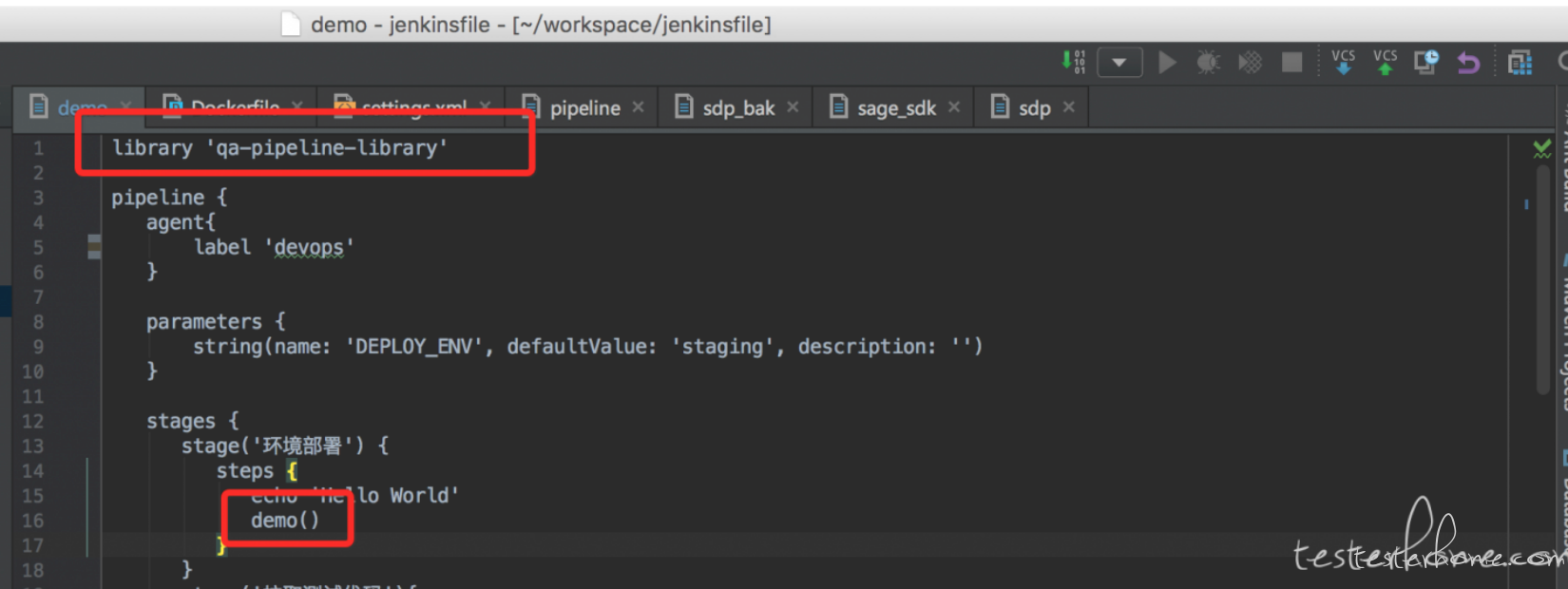
上面的例子是从共享库中的 resource 目录下加载一个 k8s 的 yaml 文件然后给下面的 agent 使用,用来动态创建 slave pod 来执行 pipeline 任务。 具体 jenkins 与 k8s 集成的内容我会放到下一篇教程讲。这里只是演示一下怎么去加载共享库中的文件.
Shared Libraries 实战
下面让我们看一下我之前开发的发送邮件用的共享库。 它会自己判断 job 的执行状态来发送不同的邮件内容。 并且会自动的获取 allure report 中的测试结果信息。 如下:
/**
* Created by sungaofei on 19/2/8.
*/
@Grab(group = 'org.codehaus.groovy.modules.http-builder', module = 'http-builder', version = '0.7')
import groovyx.net.http.HTTPBuilder
import static groovyx.net.http.ContentType.*
import static groovyx.net.http.Method.*
import groovy.transform.Field
//global variable
@Field jenkinsURL = "http://auto.4paradigm.com"
@Field failed = "FAILED"
@Field success = "SUCCESS"
@Field inProgress = "IN_PROGRESS"
@Field abort = "ABORTED"
@NonCPS
def String checkJobStatus() {
def url = "/view/API/job/${JOB_NAME}/${BUILD_NUMBER}/wfapi/describe"
HTTPBuilder http = new HTTPBuilder(jenkinsURL)
String status = success
http.get(path: url) { resp, json ->
if (resp.status != 200) {
throw new RuntimeException("请求 ${url} 返回 ${resp.status} ")
}
List stages = json.stages
for (int i = 0; i < stages.size(); i++) {
def stageStatus = json.stages[i].status
if (stageStatus == failed) {
status = failed
break
}
if (stageStatus == abort) {
status = abort
break
}
}
}
return status;
}
@NonCPS
def call(String to) {
println("邮件列表:${to}")
def sendSuccess = {
def reportURL = "${jenkinsURL}/view/API/job/${JOB_NAME}/${BUILD_NUMBER}/allure/"
def blueOCeanURL = "${jenkinsURL}/blue/organizations/jenkins/${JOB_NAME}/detail/${JOB_NAME}/${BUILD_NUMBER}/pipeline"
def fileContents = ""
def passed = ""
def failed = ""
def skipped = ""
def broken = ""
def unknown = ""
def total = ""
HTTPBuilder http = new HTTPBuilder('http://auto.4paradigm.com')
//根据responsedata中的Content-Type header,调用json解析器处理responsedata
http.get(path: "/view/API/job/${JOB_NAME}/${BUILD_NUMBER}/allure/widgets/summary.json") { resp, json ->
println resp.status
passed = json.statistic.passed
failed = json.statistic.failed
skipped = json.statistic.skipped
broken = json.statistic.broken
unknown = json.statistic.unknown
total = json.statistic.total
}
println(passed)
emailext body: """
<html>
<style type="text/css">
<!--
${fileContents}
-->
</style>
<body>
<div id="content">
<h1>Summary</h1>
<div id="sum2">
<h2>Jenkins Build</h2>
<ul>
<li>Job 地址 : <a href='${BUILD_URL}'>${BUILD_URL}</a></li>
<li>测试报告地址 : <a href='${reportURL}'>${reportURL}</a></li>
<li>Pipeline 流程地址 : <a href='${blueOCeanURL}'>${blueOCeanURL}</a></li>
</ul>
<h2>测试结果汇总</h2>
<ul>
<li>用例总数 : ${total}</li>
<li>pass数量 : ${passed}</li>
<li>failed数量 :${failed} </li>
<li>skip数量 : ${skipped}</li>
<li>broken数量 : ${broken}</li>
</ul>
</div>
</div></body></html>
""", mimeType: 'text/html', subject: "${JOB_NAME} 测试结束", to: to
}
def send = { String subject ->
emailext body: """
<html>
<style type="text/css">
<!--
-->
</style>
<body>
<div id="sum2">
<h2>Jenkins Build</h2>
<ul>
<li>Job 地址 : <a href='${BUILD_URL}'>${BUILD_URL}</a></li>
</ul>
</div>
</div></body></html>
""", mimeType: 'text/html', subject: subject, to: to
}
String status = checkJobStatus()
println("当前job 的运行状态为: ${status}")
switch (status) {
case ["SUCCESS", "UNSTABLE"]:
sendSuccess()
break
case "FAILED":
send("Job运行失败")
break
case "ABORTED":
send("Job在运行中被取消")
break
default:
send("Job运行结束")
}
}
上面是使用 groovy 语言编写的一个发送邮件的共享库。 我简单测试一下, 效果如下:
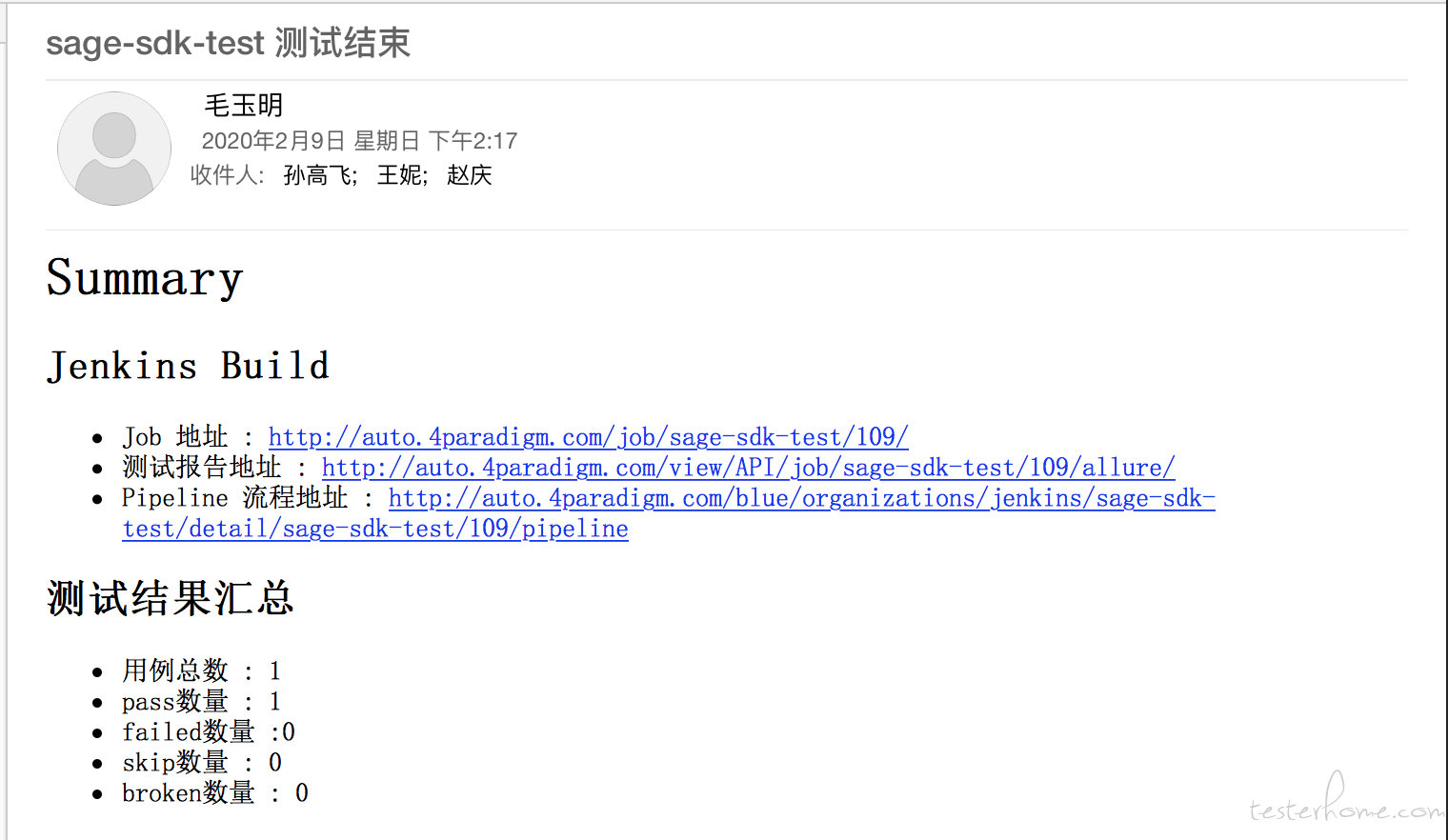
使用方式如下:

只需要在 always 里调用这个 sendmail 就好。这样就不用根据不同的状态去写发送邮件的逻辑了。 因为共享库里会自己判断当前的任务状态, 我当初傻傻的是直接调用 jenkins 的接口来获取当前运行状态的。 后来才知道好像有个环境变量有这个状态。。。。。。 然后在逻辑中会获取 allure 暴露出来的接口, 拿到运行信息,这样就可以把测试报告中的 summary 写在邮件中了(这里领导提的需求, 他不想每次都点 jenkins 链接看结果, 有些时候它直接看邮件中的 summary,发现没啥异常就不管了。)
groovy 语言介绍
当然要编写共享库就要对 groovy 这门语言有一定了解。 groovy 语言跟 java 非常像,语法什么都差不多。 java 系的同学写起来会很舒服。 我再这里介绍一些比较重要的东西。
NonCPS
在上面发邮件的实战中我使用了@NonCPS 这个注解, 注意开发 jenkins 相关功能的时候很多时候会遇到序列化问题, 这是 jenkins 内部的机制, 所以有些时候如果你碰到了序列化的异常,那你需要在方法上加入这个注解。
全局变量
在 java 中没有全局变量一说, 要说有的话,static 关键字算不算? 在 python 中我们都知道要在函数中使用函数外面的变量需要在函数中使用 global 关键字。 而 groovy 不同, 在需要在声明变量时使用@Field 注解声明
加载第三方依赖
在 java 中我们使用 maven 来安装依赖包, python 中我们用 pip。 而在 jenkins 的共享库开发中, 你要引入第三方依赖需要用@Grab注解。 我再 sendmail 里需要使用 http request 来像 jenkins 和 allure 发送 http 请求。 这需要 httpbuilder 这个包。 所以在上面使用@Grab来引入, 这样 groovy 语言就可以下载依赖了。 这是 groovy 语言提供的默认的加载第三方包的方式。
函数和变量的声明方式
groovy 的语法大多数源自 java ,但是做了相应的改变。 所以在 groovy 语言中你可以像在 java 中一样用 String a = "dfs" 这样的方式声明变量。 但是也可以使用 def a 这种方式在声明变量, 让 groovy 语言自己来推断类型, 这个跟 python 有点像。
闭包
在 groovy 语言中的闭包你可以理解为 java8 的 lamda 表达式,都是匿名函数的实现的一种 (当然实际上不是一样的,概念也不太一样,但是你可以先这么理解,方便入门)。比如在 sendmail 中:
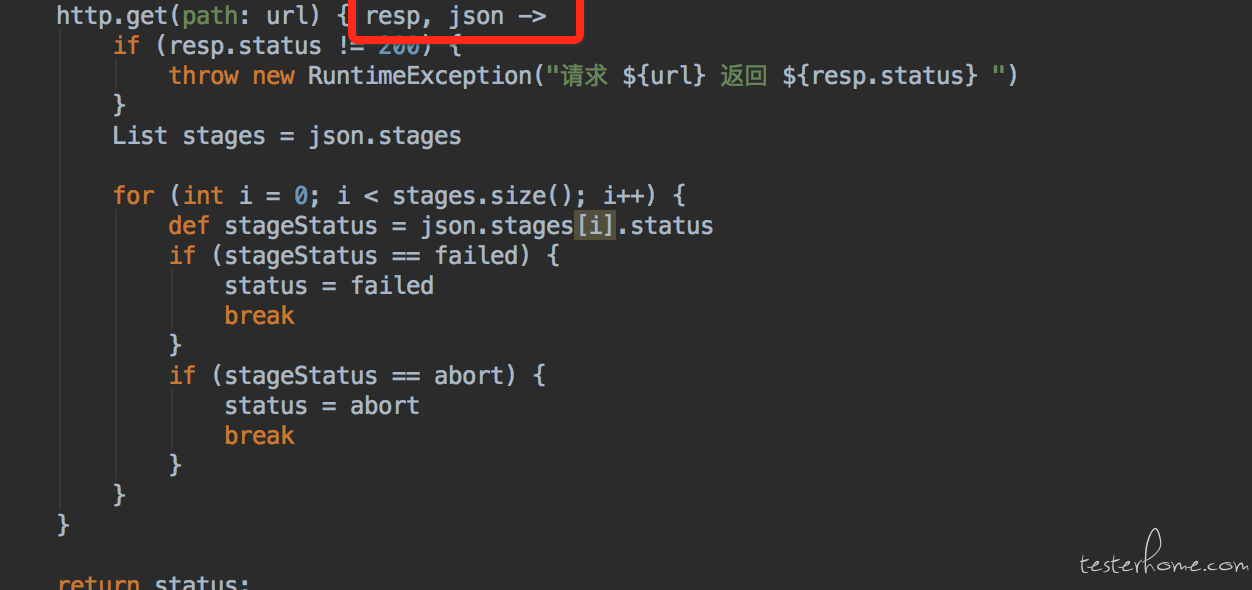
这个跟 java8 是不是感觉很像。
OK, 其他的不多讲了, 先讲这些经常用的到的。
结尾
今天先讲这么多, 由于没精力详细的讲每个知识点,所以今天就讲了 jenkins pipeline 中最主要的部分。 主要就是分享一下重点的技术细节, 希望对大家有用。 下一次讲 jenkins 与 k8s 集成的一些东西。