
作为一名软件测试人员,自己对产品相关的内容,也比较感兴趣,但就是有点后知后觉。
比如龙叔的饭否,2016 年就被曝光了,我是前几天才知道,赶紧跑去围观了一把,满足下自己作为中年油腻大叔的好奇心。
一看竟然写了 118 页,翻页累,翻页完了还需要拉到底部往上回溯时间线,更累,作为专业技术人员,咱绝不干这种点点点的累活,我要一把撸出来轻轻松松的看。
说干就干,直接拿 Python 调用 requests.get(url) 就准备收工了。
理想很丰满,现实贼骨感,没预见的一堆坑正在前方朝我招手,和这些坑一一握手后,我决定把她们写下来,然后和她们彻底说拜拜。
1、饭否需要登录,requests 直接获取的都是登陆页
当我信心满满的使用 requests.get(url) 获取网页内容进行解析时,却发现,怎么都解析不出来我需要的内容。
把获取到的 html 打印出来一看,竟然是登陆页,晕,这就是想象和实践的区别呀,我自己手动操作时都是登陆过账号的,但是程序操作是全新的 session,所以跳转到登录页了,我一开始竟然没想到,该死。
那就想办法搞定登陆呗,我记得有办法直接在请求中带上账户密码,但是实现有点麻烦,所以我立马又想到了另一个讨巧的方法来搞,就是用 Selenium 模拟登陆操作。
好了,登录的问题终于完美解决,html 内容也获取正确了。
2、退出错误的问题,退出前 time.sleep(3) 搞定
看着顺利跑起来的 Selenium,心里还在为自己这点小鸡贼窃喜,可是在执行完成后,总是会多出来下面这种错误:

没有仔细看懂错误信息是什么意思,但是作为专业测试人员的直觉告诉我,浏览器在自动操作中退出的太快了,于是在退出前顺手加了下 sleep,搞定。
3、html 内容解析使用的分隔符不合理,导致结果错位
本来只想把帖子内容爬出来的,后来想想还是带上时间线比较好,但是时间线和帖子内容在 html 中是分开的,我需要分别获取,然后再做对应关系。
先说一下哈,我没有用标准的 html 解析的库,因为看起来很简单很有规律,而且是一次性的活,所以直接使用的全文字符串解析,嗯,后面说的都是基于这个实现方式的哈。
本来找的很准确的规律,在很有信心的输出后,竟然出现了意想不到的错位,如下图:
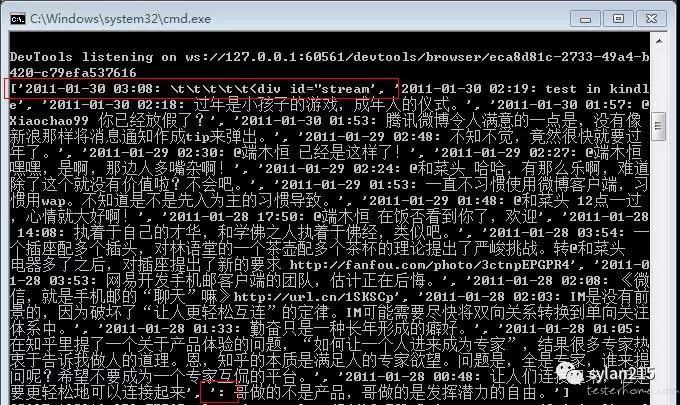
我得说,都是字符串解析的锅,全文字符串解析,必须要选择合理的 split 字符串,不然后续继续解析就会存在不唯一性,那么结果必然出错了。
这次出现的问题是我在第一次 split 时,把帖子内容和时间线分开了,所以造成了二次处理的难度,重新选择 split 分词后,保证时间线和帖子内容在同一段内容中,绝对的保证了一致性,错位问题成功解决。
这么描述起来不太好理解,大家可以后台回复关键字「龙叔」获取我实现的源码,然后查看函数 get_target_str 的实现即可。
4、gbk 解码错误
好了,顺利通关前三个问题后,单页内容的爬取终于搞定了,我开始把页数设置为 range(1, 119) 自动跑,然后放心的去上厕所了,憋死我了。
回来一看,哇,跑完了,爽,但是仔细一看,不是正常结束的,报错了:
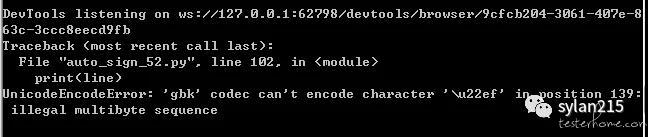
看完报错信息我就偷偷的笑了,还好还好,这个问题我之前解决过,只是输出信息中有部分无关紧要的特殊字符,在处理时加上errors='ignore'就行了,之前因为这个问题被坑过,算是终身难忘了。
编码问题瞬间搞定,继续重新跑起来。
5、帖子总条数不符合预期
经过上面的处理,这次终于跑完全程了,如果你以为这就完事,那就 Too 样 Too simple 了。
作为专业测试人员的严谨性,咱不能看到一通输出就当作完事,必须要对结果进行二次确认才放心,所以我对比了一下输出的帖子条数。
预期应该是(117 页 * 每页 20 条)+ 最后一页 11 条 = 总共 2351 条, 而实际只有 2285 条,足足少了 66 条。
于是我又按照页码,把每一页的条数打印出来,异常的数据情况如下:
11 页输出 16 条,少 4 条;
26 页输出 16 条,少 4 条;
33 页输出 3 条,少 17 条件;
57 页输出 19 条,少 1 条件;
72 页输出 8 条,少 12 条件;
76 页输出 2 条,少 18 条件;
81 页输出 13 条,少 7 条件;
82 页输出 19 条,少 1 条件;
102 页输出 18 条,少 2 条件;
把少的加一起,刚好 66 条,看来不错数据源问题,就是我的统计问题。
我先去 11 页看了看,确实是 20 条,一点不少,那肯定是我解析的问题了。
先猜测是否是 encoding 时加了 errors='ignore' 把一些数据过滤没了,所以去掉 encoding 选项试试,还是不正确。
继续怀疑是不是分隔符字符串选取的不合理,一通插桩后(把所有做了解析处理的地方都做了输出,来对比验证输出是否符合预期),终于发现是自己自作聪明的使用'\n'作为段落分隔符造成的问题。
我自己手动查看的几个页面,龙叔发的内容都是不带换行符的,所以所有帖子内容是一个完整的整体,这时候使用'\n'刚好可以把 html 的头和尾去掉,一旦龙叔帖子中出现换行,去球,上面的方法直接入坑,唉,偷懒使用山寨的土方法,那么就有山寨的坑,慎重慎重。
于是去掉 '\n' 的分隔,直接整个 html 进行全文解析,搞定。
在经历了过山车式的 5 个问题后,终于顺利达成目标,再综合总结下经验:
1、注意细节,不要理所当然,一定要做确认;
2、认真对待每一个处理,不要有轻视的心理;
3、分析问题比解决问题更关键,只有正确的分析了问题,才能对症下药。
以上,我完整记录了自己一次分析和解决问题的经历,描述了过程中自己是如何思考以及如何应对的,不知道你工作过程中是否有碰到类似的问题,你当时是如何处理的呢?欢迎给我留言,说说你的经历。
当然,如果你觉得我得分享对你有帮助,请帮忙分享转发 + 点个「赞」让更多人看到,谢谢。
PS:想获取实现源码和张小龙全部饭否记录的同学,请点击「这里」,文章底部有获取方式说明。