新手
arrow (arrow)
第 22495 位会员 / 2017-11-07
6 篇帖子 • 348 条回帖
-
请问大家 Python 怎样下载一个 url 请求的文件,可能我描述的不是很清楚,直接贴代码 at 2018年03月05日
一般页面内下载是通过 frame 嵌套或者是 302 重定向来实现下载的,只要拿到资源的地址,直接请求就好了
import requests url = 'http://www.aaa.com/download/demo.zip' # 获取到资源地址 r = requests.get(url) with open("demo3.zip", "wb") as file: # 文件名通过解析url地址得到 file.write(r.content) -
pytest 运行后无法执行测试用例,不清楚是不是命令写错了 at 2018年03月05日
你把 -m pytest 去掉,应该是用例筛选掉了
-
pytest 运行后无法执行测试用例,不清楚是不是命令写错了 at 2018年03月05日
贴开头部分就可以了,不用全部发出来
-
pytest 运行后无法执行测试用例,不清楚是不是命令写错了 at 2018年03月05日
能否把用例贴出来看看
-
求助,APP 在 login 和 Logout 两个状态的启动 activity 不同,如何处理 at 2018年03月05日
app 启动主界面肯定只有一个,应该是开发根据登录状态做了跳转,你问一下开发就知道了

-
pytest 运行后无法执行测试用例,不清楚是不是命令写错了 at 2018年03月05日
pytest.main(['-m', 'pytest', 'main_test.py', '--html=test.html']) -
求问,selenium grid 是否能做到 java rmi 的效果,在远程机器执行 java 代码 at 2018年03月02日
selenium grid 只能执行浏览器的操作,如果想同时在多台机器上执行,可以添加多个 jenkins job,每个 job 指定不同的 slave,应该就可以了
-
testerhome 搜索结果能否增加排序功能? at 2018年03月02日
我觉得楼主的意思应该是筛选吧,百度和谷歌都有这个功能
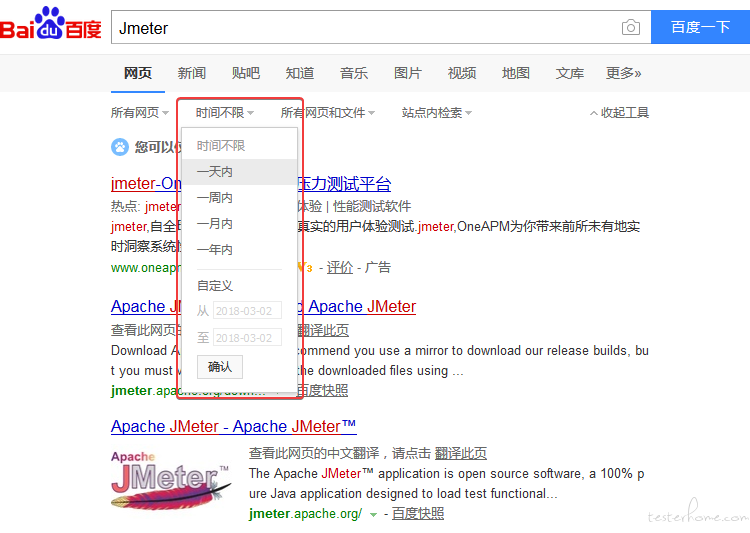
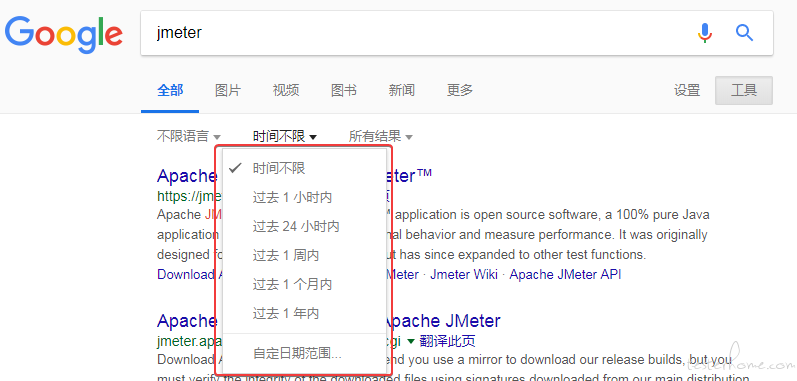
-
答题这种模式的项目,通过 websocket 来实现的,怎么来做接口自动化呢 at 2018年03月01日
可以用 Appium + Selenium 操作 APP;
也可以直接请求 websocket 接口 (python 有对应的库websocket-client); -
如何统计页面在不同网络下的耗时 at 2018年02月28日
- 页面加载慢,先确定是 APP 的问题,还是 API 响应慢的问题,这个通过对 API 进行性能测试可以分析出来;
- 如果是 API 慢,应该着重对后端服务进行优化、服务器开启压缩等;
- 如果是 APP 渲染慢,IOS 参考这篇文章,安卓参考这篇文章;
- h5 加载慢,看看是不是 js 加载慢了,可以考虑缓存 js 等。
-
[支付宝芝麻信用分] 小电租借,600 以上免押金,足够信用分了也需要我缴纳 at 2018年02月28日
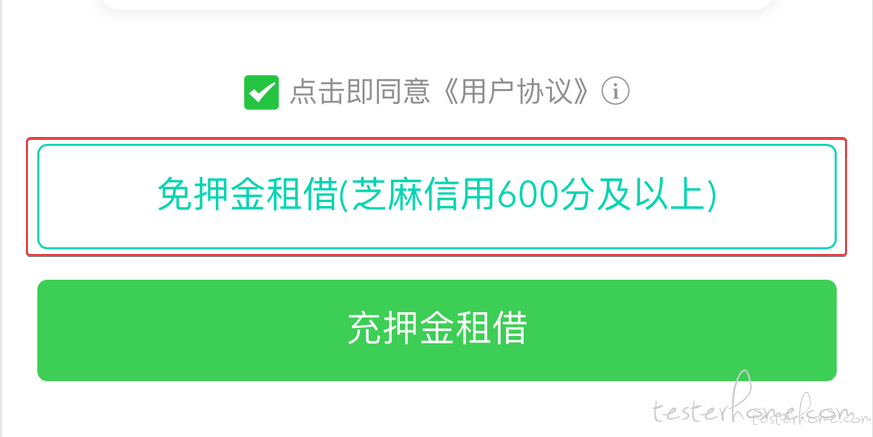
点这个应该就好了吧 -
2018年 我很慌 at 2018年02月28日
感觉跟我有点类似,一个人做自动化,没什么进展。。
-
暂时停更 at 2018年02月28日
好好休息!!!
-
Testerhome 回复帖子后,楼层显示不正确 at 2018年02月23日
-
Mi6 有没有 Root?有可能是没有 root 导致的
-
2017 末,两年半 at 2018年02月23日
很不错,已经比大多数人强了,加油
-
发现一个 TesterHome 里不知道算不算问题的问题 at 2018年02月23日
被转义了,重新发一下 < > &
-
发现一个 TesterHome 里不知道算不算问题的问题 at 2018年02月23日
在 Markdown 语法里面,尖括号,and 符号,需要用 < > & 等转义符来表示。