-
有偿在线求答案,ios-ui 自动化 webdriveragent 问题 2 个 at May 18, 2021
ThankQ
-
有偿在线求答案,ios-ui 自动化 webdriveragent 问题 2 个 at May 18, 2021
有运行效果图吗?稳定性怎么样?
-
深聊自动化测试 -- codeless 之争 at May 14, 2021
搞测试自动化,写代码、coding 测试用例是最正确的姿势,其他都是死路一条,毋庸置疑!
-
GUI 自动化遍历 遍历过程和结果如何报告化? at April 01, 2020
Allure2 和测试框架本身没有任何关联,测试框架只是给 Allure2 编写了几个接口调用. 所以不使用任何测试框架自己编写也完全可以
-
pytest+allure 生成漂亮的 html 测试报告 (一) at December 24, 2019
Allure 是 Allure, Pytest 是 Pytest, Pytest-Allure 只是对 Allure 需要的.json 文件的生成做的一个插件.
Allure1 的时候需要的是一个.xml 文件
Allure2 的时候需要的是一个.json 文件 (好像是),并且 2 兼容 1
所以,介绍 Allure 的时候可以脱离 Pytest 的,只要自己写几个装饰器用来生成 allure 需要的 xml 或者.json 日志文件. 即可以脱离 pytest 使用. -
SoloPi 架构解析 | 录制回放的原理与实战 at August 08, 2019
占个位,留着忙完这段时间回来翻看并体验尝试
感谢大佬分享 -
接口自动化测试平台演进之路 at August 02, 2019
感觉第二版才是适合复杂逻辑使用的. 第三版看描述就是第一版的界面优化版.
-
测试平台——接口自动化、UI 自动化.... at July 09, 2019
想看下 UI 自动化这块的界面功能介绍...可以展示下不
-
为什么用 appium 做自动化测试的时候,单个用例可以通过,但是所有用例一起运行会有些用例失败 at July 05, 2019
没贴出来错误信息,无从判断.
猜测是运行时间长不稳定, 或者是数据逻辑问题? -
在 airtest 中使用 ocr 反向识别文本内容进行断言 at July 04, 2019
如果中文的化,可以直接用百度云的 API, 免费一天 1000 次,用来解决问题足够了.
另外: 感觉举得例子有点不太合适,文字也可以被当作图片来做识别的, 可能是一些逻辑判断分支的情况下, 才会 OCR 识别出文字然后做逻辑处理. -
求助,大量 web 端的 UI 自动化测试用例的执行,是怎么节约时间的? at April 10, 2019
selenium+grid 可以用的, 创建一个 Hub, 然后注册一堆 Node 到这个 Hub 上. 这个 Hub-Node 就是运行环境.
-
浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure) at January 14, 2019
@allure.feature("suite1")
@allure.story('Case01')
def test_case_01():
pass@allure.feature("suite2")
@allure.story('Case02')
def test_case_02():
pass你试一下, 看是否是你想要的效果.....
还有, allure 分 1 和 2 两个版本,1 已经不更新了, 现在 github 上都是 allure2.x 的. 你截图的那个 好像是 allure1.x 版本的, 可能显示位置和 allure2.x 版本有点界面上的不一样 -
浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure) at January 10, 2019
你这不是四个 suite 显示么..不知道你所说的在一个 suite 是什么意思

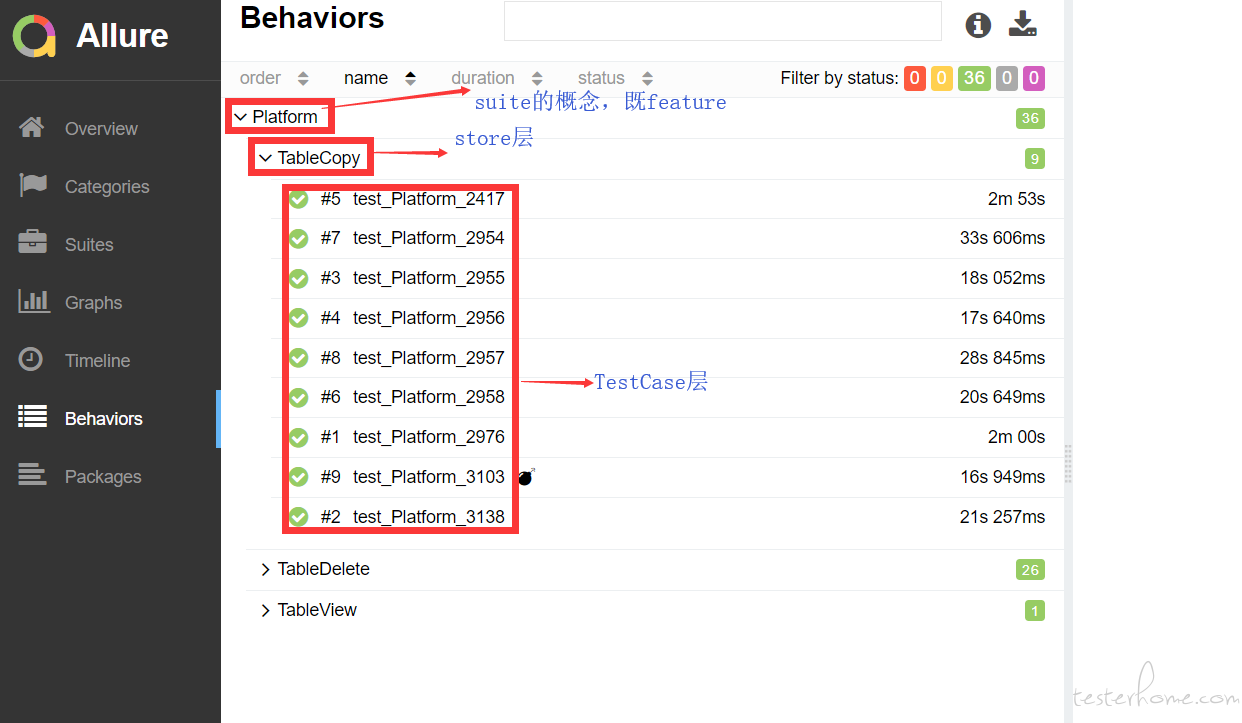
feature 对应你说的 suite, story 是 feature 的下一层, 在 allure 的 html 报告界面, 主菜单的 Suites 表示按 feature 分类显示, Behaviors 表示按 feature-story 显示. 还有其它的按线程分类显示, 图表显示等等 -
浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure) at January 09, 2019
或者来个你最后 pytest 生成的 xml 日志的截图. 检查下这个 xml 日志文件中对应的每个 Case 的 feature 和 story 和你在代码中设置的一样不
-
浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure) at January 09, 2019
可以来个截图么, 你代码的截图 和 allure 报告的截图
-
浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure) at January 09, 2019
上面提到了呀, 如果你使用的是 pytest.allure 插件的话,用 allure.feature 和 allure.story 装饰器来设置每个 Case 的所属 suits. 如果不是用的 pytest 的话,就找下看你用的框架哪个 function 负责写 xml 日志中的 feature 和 story 节点的,用它这个 function 就行
-
浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure) at January 09, 2019
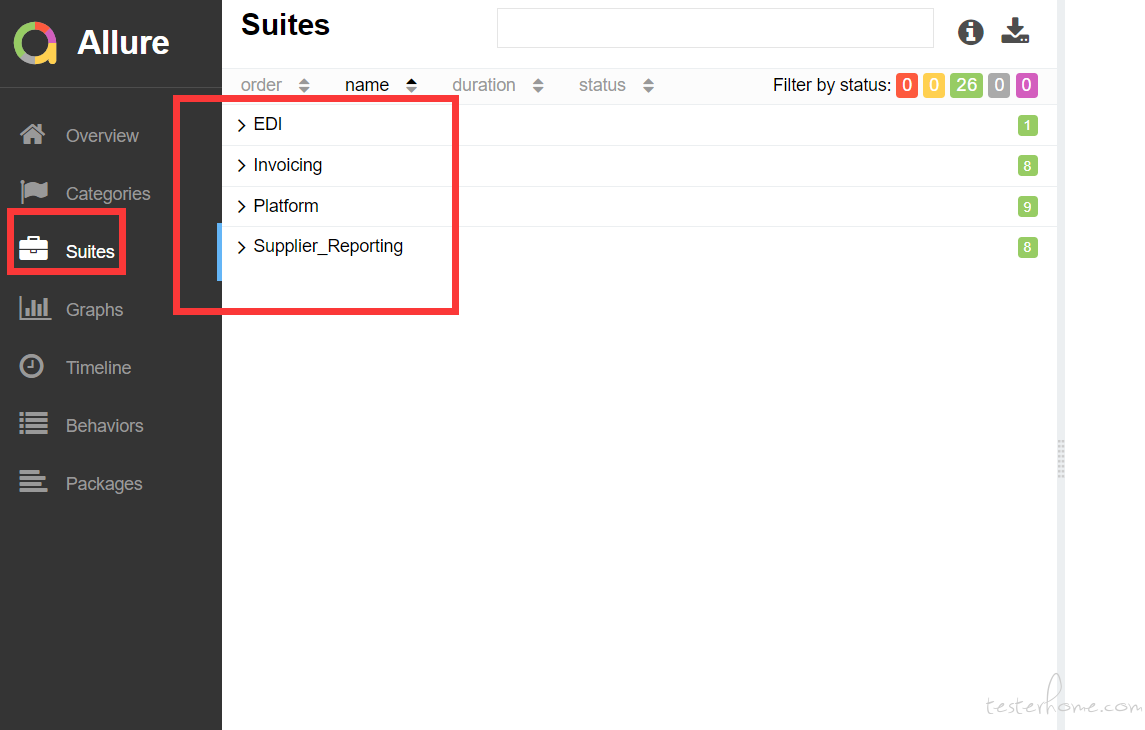
Sorry,截错了, 这个才是你说的那个图
-
浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure) at January 09, 2019
-
浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure) at January 08, 2019
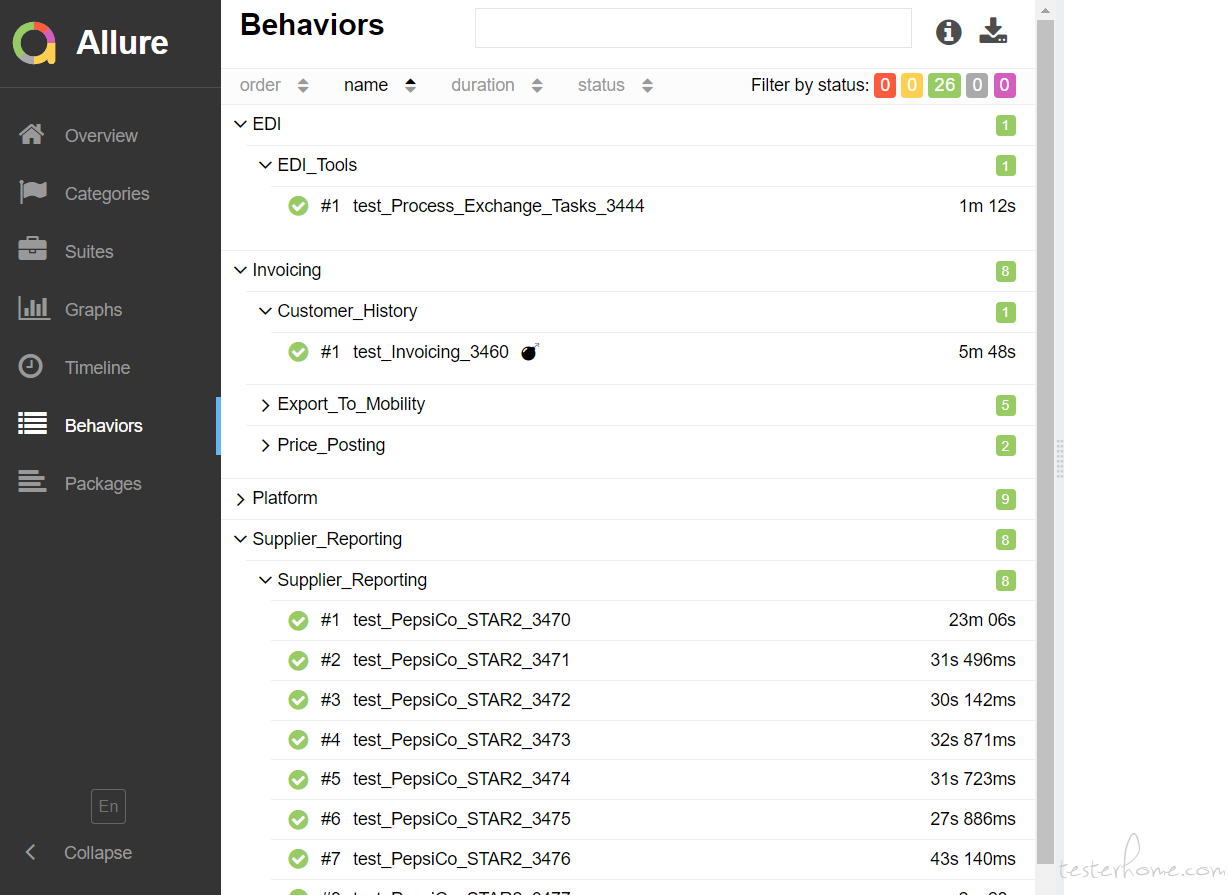
看我上面回复, Allure 有 store,feature,severity,thread,host 等五个分类, 你说的 suits 应该指的是 feature 的概念, feature 下面还有 store 这一层。 如果你适用的是 pytest.allure 插件的话,你可以用 allure.feature 装饰器和 allure.story 装饰器来设置每个 Case 的所属 suits。
最后附一张报告截图,
-
浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure) at January 07, 2019
没有太理解你的需求, 你是想将多个组的 Case 分别按组显示 Allure 的报告吗?还是 不同组的 Case 显示在不同的 Allure 中.
如果是第一种: Allure 有 store,feature,severity,thread,host 等五个分类, 你将 Case 分别按照这些分类就好,最终的 Allure 页面 可以分组显示每种类别下面的每个 Case。
如果是第二种:需要在运行过程中自己去创建每个 suites 的文件夹来存放对应的 xml 日志文件, 然后最终通过 allure generate 去生成 allure 报告的时候,分别指定不同的 suites 文件夹, 就可以生成多个 allrue 页面了. -
Appium-同一个元素不同定位方式的区别 at November 12, 2018
是的, 已知父元素, 然后去查子元素这个我试了, ok 的.
反过来 已知子元素, 然后查父元素, 这个 api, 我翻了翻 Python 版的 Appium-Client 和 selenium 的源码, 没搜到类似功能的 API 呀,有这种吗? -
Appium-同一个元素不同定位方式的区别 at November 12, 2018
楼主你好, 关于谓词定位的问题 (iOSNsPredicateString) 请教下...
有个场景需要使用 xpath 的父子定位和兄弟定位 (xpath 轴), 比如 xpath = "//XCUIElementTypeButton[@label = 'xyz']/following-sibling::XCUIElementTypeButton" 或者 xpath = "//XCUIElementTypeButton[@label = 'xyz']/.."
这样的父子元素和兄弟元素定位场景, 用 iOSNsPredicateString 有套路实现吗?或者用其它方式实现 (xpath 除外)...(我从 Web 转过来的, 上面的对 App 的 xpath 例子可能没写好
 ,大概是这么个意思哈)
,大概是这么个意思哈) -
一招让 IOS 自动化化快的飞起 at November 11, 2018
感谢
 我琢磨下它这个 api....能用了我来分享哈
我琢磨下它这个 api....能用了我来分享哈 -
一招让 IOS 自动化化快的飞起 at November 09, 2018
图像识别么, 有些尴尬的元素,比如一些文本输入框,页面有很多...可能不太适合图像识别,全空白...
如果有 get_parent(element) 这样的实现思路最好了, 不熟悉 APP 这块, 在 Client 端的源码里翻了翻没找到这样的方法... -
一招让 IOS 自动化化快的飞起 at November 09, 2018
请问个问题, 在不适用 xpath 轴的情况下, 有什么办法能够通过已知的元素得到它的父元素吗?
比如用谓词定位到了 element-A, 现在想通过 element-A 得到它的父元素, 或者兄弟元素,有思路吗?