前些日子在 testerhome 群问了不少关于 LR 性能测试的问题,现在总结归纳下。在此感谢一些东哥等人的指点,虽然被说的体无完肤 .
.
一、 业务类型选取
1、 针对应用服务器的压测,可根据业务配比选择交易较高的业务
2、 针对数据库服务器的压测,可选择对数据库进行增删改查频率较高的业务
二、 业务数据分析
1、 需要调研每个关键接口每天调用的次数,这样可以算出单笔业务的 TPS
比如:系统每天订单提交量为 1000(基本每人一单),根据 2/8 定律,80% 的交易在 20% 的时间完成,每天交易量 1000 笔,一天 8 小时
TPS=80%*1000/(8*3600*20%)=0.139
并发数 / (响应时间 + 考虑时间) ≈ 总业务数 /总时间 = TPS
假如用户对响应时间的上限为 2 秒
并发数 ≈ 2*0.139 = 0.278
2、 需要调研访问系统的用户数及登录时长,算出系统的并发用户数
比如:某系统有 30000 个用户,平均每天大约有 1000 个用户要访问该系统,对一个典型用户来说,一天之内用户从登录到退出该系统的平均时间为 4 小时,在一天的时间内,用户只在 8 小时内使用该系统。
计算平均的并发用户数: C = nL/T
C 是平均的并发用户数;n 是 login session 的数量;L 是 login session 的平均长度;T 指考察的时间段长度
C = 1000*4/8 = 500
三、 脚本录制方式选择
1、 如果应用是 WEB 应用,首选是 HTML-based 方式;
2、 如果应用是使用 HTTP 协议的非 WEB 应用,首选是 URL-based 方式;
3、 如果 WEB 应用中使用了 java applet 程序,且 applet 程序与服务器之间存在通讯,选用 URL-based 方式;
4、 如果 WEB 应用中使用的 javascript、vbscript 脚本与服务器之间存在通讯(调用了服务端组件),选用 URL-based 方式。
四、 模型创建
例如:100 次业务中,有 20 次购买,另外 80 次只浏览不购买,购买前都需要浏览商品
1、 业务模型
浏览商品—> 购买—> 80%
浏览商品— — —> 20%
2、 接口模型
浏览商品— — —> 100/120
购买 — — — —> 20/120
五、 通用的测试策略
1、 基准测试
在系统没有压力的情况下对各功能进行单线程的测试,测试结果主要用来作为基准值为后续测试结果做比对参数
2、 单交易测试
采用梯度测试方法对单个功能或接口在不同压力下的进行测试,可以得出单个功能的最大 TPS,结合基准测试的结果可以分析性能的增长趋势 (响应时间/系统资源等增长趋势)
3、 混合场景测试
使用相关模型进行测试的场景,主要验证整体性能是否满足上线要求,或者给出基于模型的最大 TPS
4、 稳定性测试
一般在系统最大 TPS 的 80% 压力下 执行 12 或 24 小时,主要验证系统在执行大量业务交易 (一般模拟一个月的业务量) 后性能表现
六、 场景分析
来源:http://www.cnblogs.com/stay-sober/p/4136062.html
⑵.事务摘要
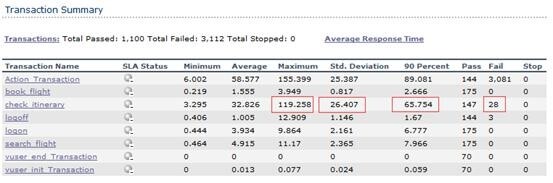
现象:
Transaction Summary 部分显示:
- Average 表明事务的平均响应时间。响应最慢的事务:check_itinerary;
- Fail 表示事务失败的个数。失败较多的事务:check_itinerary;
- Std. Deviation 表明事务的波动情况、稳定性。波动较大的事务:check_itinerary;
- 90 Percent 表明 90% 的事务的响应时间,波动大的事务查看 90% 的响应时间较准确。90% 响应时间较大的事务:check_itinerary;
分析:
从响应时间、波动性、失败情况可以看出问题最突出是 check_itinerary 事务,进一步分析该事务。
⑵.Running Vusers
running vuser 为场景运行时,正在运行的 vuser 情况。由于性能的问题由并发增大引起,所以,看其他指标需要结合 running vuser 情况。
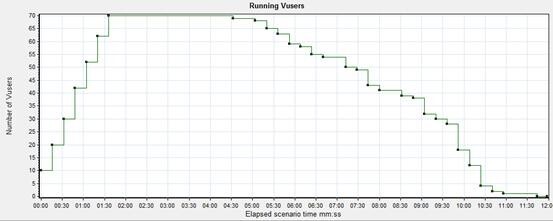
现象:
起始为 10 个 vuser,以 10 的阶梯递增,在 1:36 秒维持了 3 分钟,而后以 1 个阶梯减少;
分析:
需结合其他指标图表。
⑶.Errors per Second (by Description)
每秒的错误数信息。可以查看随着运行时间,不同错误的发生曲线。
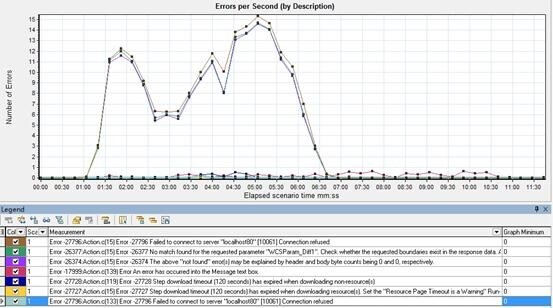
现象:
在高并发时,前三个为突出的问题;Error 27728、27727 出现在高并发阶段;Error 17999 运行 1 分开始小幅波动,但具体什么错误不知道。
- Error 27796:connection refused;
- Error 26377:未找到关联;
- Error 26374:响应为空,可能导致了未找到关联的错误;
- Error 17999:message box 处发生的错误;
- Error 27728:step download timeout 下载 non-resource 元素时,下载超时;
- Error 27727:step download timeout 下载 resource 元素时,下载超时; 前 3 个问题发生较多,中间有下降、上升的大幅波动,最后下降,呈 M 状,3 个问题的趋势一致。 分析:
- Error 27796:说明了和服务端连接有问题;需要确定连接数是不是满了,排查连接各环节的连接设置,看 Connections 图;
- Error 26377、26374:说明了,服务端未响应;进而需要看 throughput、Average Transaction Response Time、transactions per second 此类服务端性能的指标;
- Error 17999:暂不清楚;
- Error 27728 、27727:在高并发时才出现的下载超时的问题,应考虑服务端的处理能力;(如果场景开始就有下载超时,就需要检查 runtime setting-internet protocol 中对超时时间的设置是不是太小了) 结合 vuser 图,错误集中时段是并发数高于 55 个 vuser 时间段,高并发导致了大量的 error。系统目前性能情况,最大允许并发为 55。
Error:连接拒绝
I.1 Hits per Second-Connections
连接数显示了场景运行时,打开的 http 连接数。
根据上一步的推论,查看随着 vuser 的增加,请求的增加,连接数是否达到了最大,因此导致了服务端拒绝访问的问题。如果是这样的情况则需要调整 web 服务端的最大连接数。
正常情况下,连接数的趋势应该随着 vuser 增加,请求增加,是逐步增加。但是此图曲线有中间的下降,需要结合点击率来较为准确的查看请求情况。
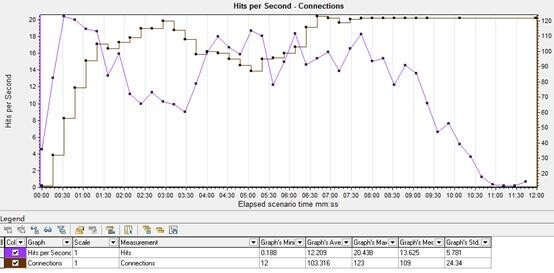
现象:
点击率开始为增加趋势,中间有降、升,而后波动,最后下降,基本呈 M 状。
分析:
考虑到连接统计的延迟,连接数基本符合点击率的波动情况,但是后面仍然保持在较高的连接数;
推论一、是否是因为连接未及时关闭,致使连接数满了,继而导致了服务端拒绝连接的问题;进而需要查看每秒的连接打开和关闭情况。
推论二、服务端、客户端之间的连接数设置的过小,导致连接数满了。
I.2 Connections per Second
显示了在运行时,打开和关闭的 http 连接情况。如果连接关闭的曲线和连接打开的曲线差得多,表明连接未被及时关闭,连接被占用,会导致服务端连接的满了,拒绝客户端的访问的错误。
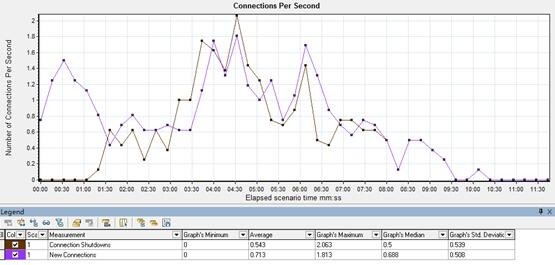
现象:
曲线基本一致。
分析:
不是因为连接关闭不及时导致的连接数满,服务端拒绝访问的问题。所以根据上一步的推论二基本确定连接数设置问题,需要进一步查看 web server、服务端操作系统连接数设置、客户端操作系统连接设置、lr 运行的设置等相关的连接数情况。
Error:服务端响应不过来
II. 1 Throughput
显示场景运行时,每秒从服务端获得的数据量,可以判断服务器的处理能力。
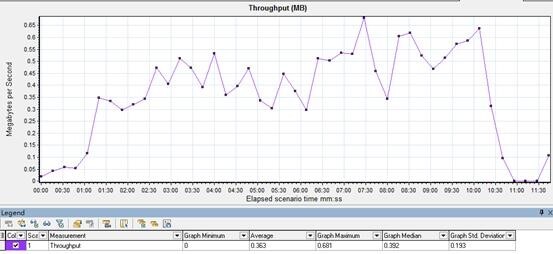
现象:
吞吐量开始递增,而后在高并发阶段趋势较平稳,最后下降。
分析:
服务端处理能力较为稳定,没有发现问题。
II. 2 Hits per Second - Average Transaction Response Time
Average Transaction Response Time 显示场景运行时,事务执行所用的时间。事务的响应时间和请求数结合来看,查看 check_itinerary 事务响应时间。
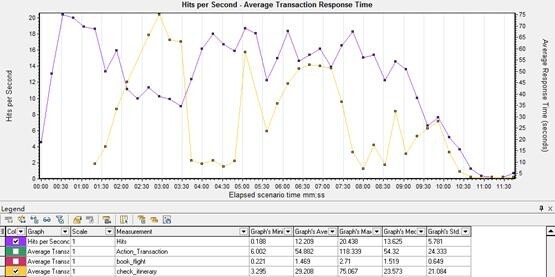
现象:
两个曲线在中间大幅下降后,后面波动的趋势大致相符。
分析:
响应时间的降低是因为点击率减少,服务端接收到的实际请求减少,压力较小,响应快了。未分析出其他问题。
II. 3 Transaction per Second
显示了事务的成功、失败、停止的数量,通过此项可以确定系统在时间点的事务负载情况。和平均事务响应时间对比,可分析事务数对执行时间的影响。
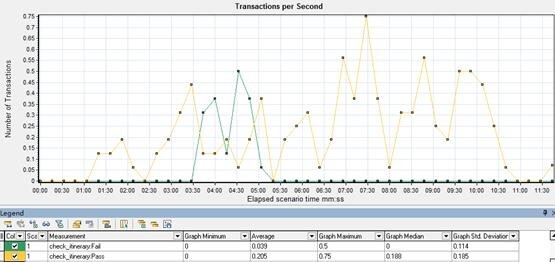
现象:
check_itinerary 成功的事务较波动,数值较小;check_itinerary 失败的事务集中时间为并发高峰时段。
分析:
TPS 数值太小,说明了的服务端处理事务能力较弱,继而需要查看 system resource 图。
II. 4 System Resource
** 处理器的指标 **
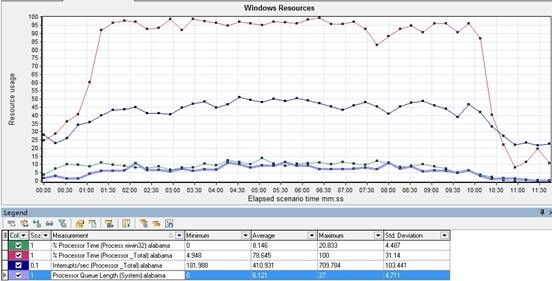
现象:
Processor_total 大部分在 90% 以上,表明 cpu 配置较低;
Interrupted/sec 中断并发高时较多,但低于 60%;
Process_xiwin32 较为平稳;推测为 xiwin32 进程(web server);
Processor queue length cpu 的平均负载很大;
分析:
系统 cpu 瓶颈较明显,又考虑 process_xiwin32 占用 cpu 不算多。推测是由于系统服务端其他进程占中了大部分 cpu。优化服务端的进程情况,使 web 服务更有效的占用 cpu;或更换高配的 cpu;或改为 linux 服务器,减少其他进程的占用。
** 内存的指标 **
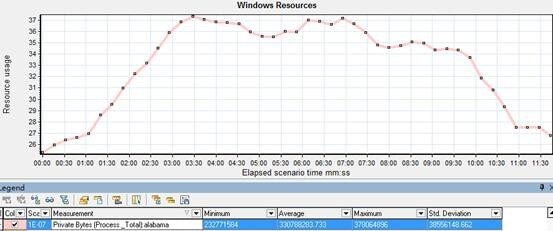
现象:
Private byte 随并发请求增加,内存相应增加,后面下降。
分析:
未发现问题。
磁盘的指标
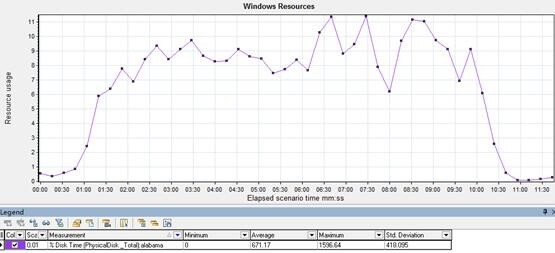
现象:
随着并发请求增加,磁盘交互响应增加,比较平稳;
分析:
未发现问题;
Transaction:check_itinerary
III.1 Web Page Diagnostics
此图为对事务的各元素各种响应环节的细分情况。以下图为 check_itinerary 的事务细分情况。
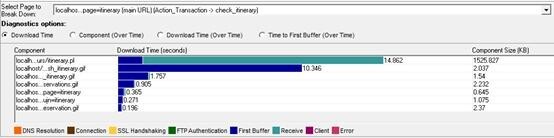
现象:
check_itinerary 事务中 itinerary.pl 和 sh_itinerary.gif 的下载时间最长,请求 itinerary.pl 响应字节数较大,接收时间较长;sh_itinerary.gif 并不大,但是 first buffer time 很长。
分析:
请求 itinerary.pl 的业务为查询日程安排,推论是因为响应的数据量较大,导致的接收时间长。可以考虑优化该文件的代码,拆分文件,压缩输出等。
sh_itinerary.gif 文件 first buffer time 较长,进而分析该项的 time to first buffer 情况。
First buffer time:
细分为服务端时间、网络时间。
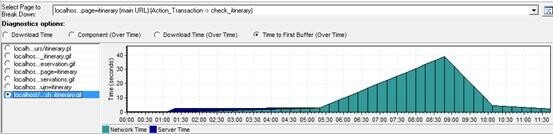
现象:
网络时间明显很大。
分析:
此文件的网络时间较长,可推论出网络方面的问题,需要进一步查看网络指标确定。
七、 瓶颈查找定位
查找瓶颈时按以下顺序,由易到难。
---〉服务器硬件瓶颈
---〉网络瓶颈(对局域网,可以不考虑)
---〉服务器操作系统瓶颈(参数配置)
---〉中间件瓶颈(参数配置,数据库,web 服务器等)
---〉应用瓶颈(SQL 语句、数据库设计、业务逻辑、算法等)
