不能阅读被屏蔽的文章。
Appium 求助,通过 XPATH 抓取 H5 页面的元素,一直是无效的,求各位朋友,分享一下你们的成功经验好吗,我用的是 Python
求助,通过 XPATH 抓取 H5 页面的元素,一直是无效的,求各位朋友,分享一下你们的成功经验好吗,我用的是 Python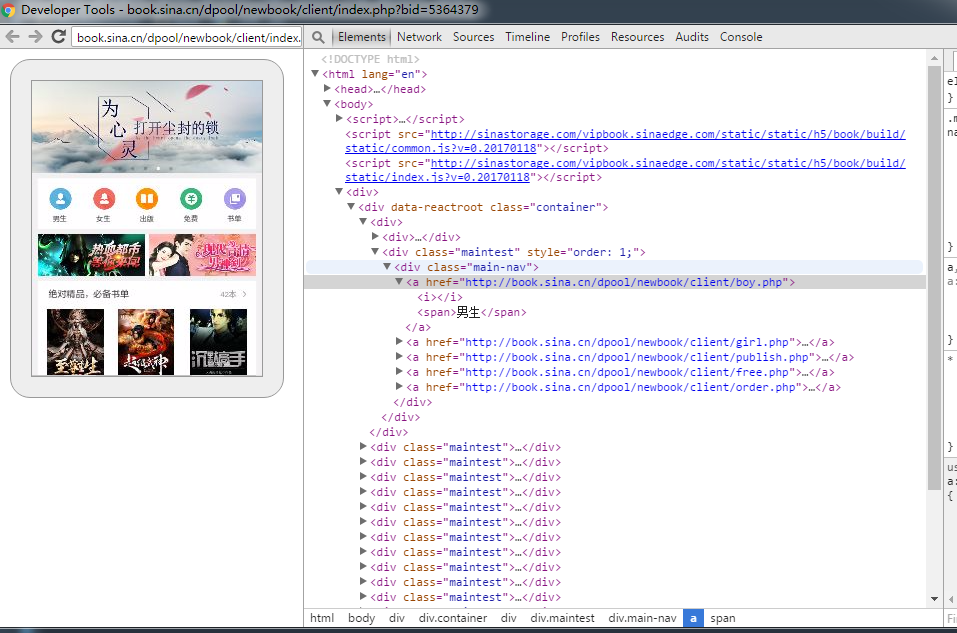
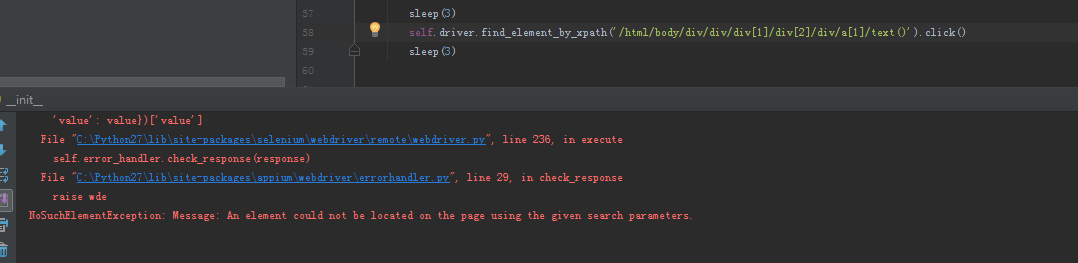
麻烦大家了,谢谢
「原创声明:保留所有权利,禁止转载」
你有没有先切换到 webview 模式?
大神,我什么都已经搞定了,只是用 Xpath 定位不到元素,我已经贴了我要定位元素的图,就是要定位男生,女生,用 XPATH,您可以分享一下代码吗,我这块比较烂,谢谢
 这样我已经试过了,我贴的图就是这样得来的 XPATH,显示的是定位无效
这样我已经试过了,我贴的图就是这样得来的 XPATH,显示的是定位无效
driver.get("http://book.sina.cn/dpool/newbook/index.php")
driver.find_element_by_xpath("//*[@id='nav']/li[2]/a").click()
这样可以吧。
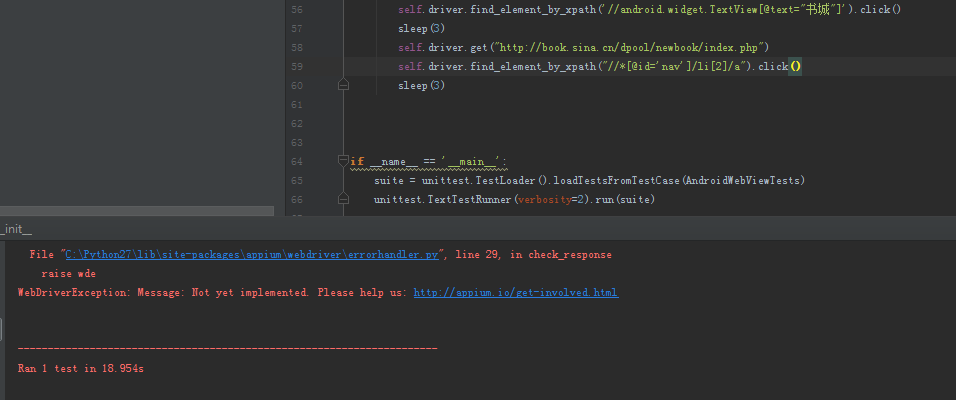
//*[@id='nav']/li[2]/a
你只用这个 xpath 试试。
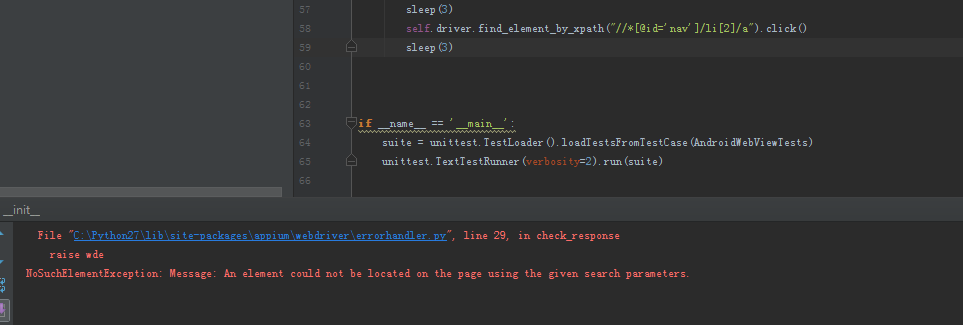
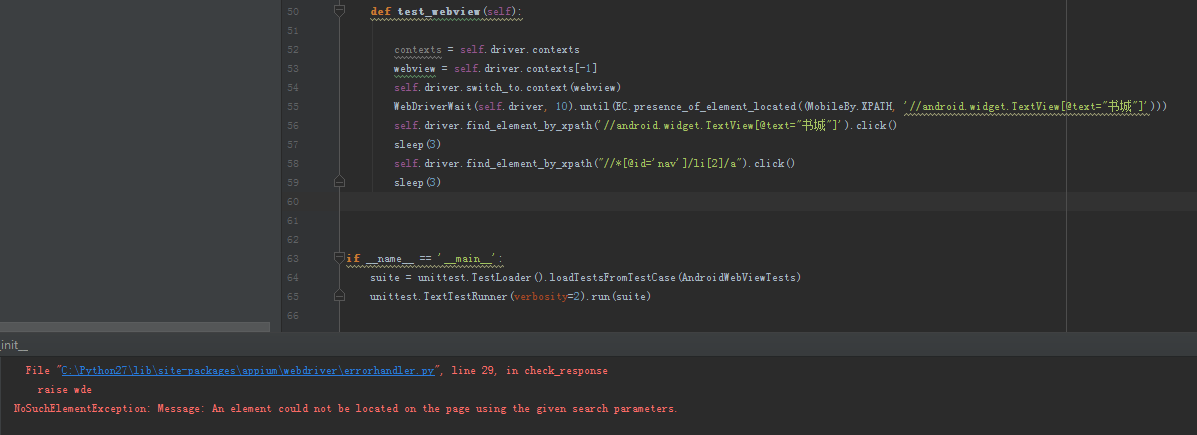
大神,我真心是和您一摸一样的,您看看,我还是报错是无效的,真的很无奈啊
@friday 你谷歌浏览器的版本和 chromedriver 的版本 分别多少 你的 chromedriver 的路径位置让我看看
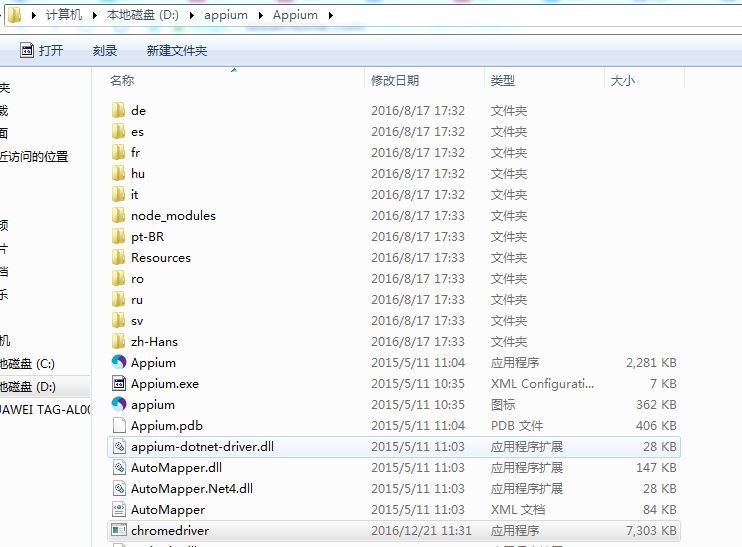
@friday 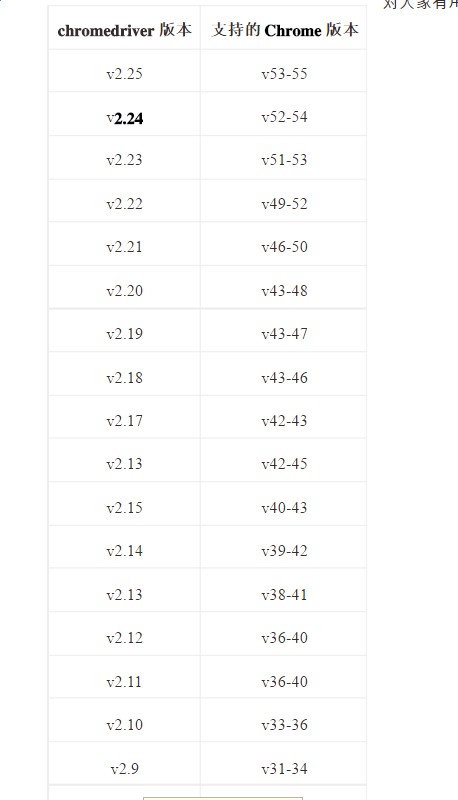
你的 chromedriver.exe 放到网盘链接 我帮你试试 是不是版本的不兼容导致的
对
 Tester_web
回复
Tester_web
回复
https://pan.baidu.com/mbox/homepage?short=slk4o6D
朋友,可不可以把你的是怎么定位 XPATH 的告诉我,我现在挺着急的
@friday xpath 就是你定位到元素 右击复制的 你试试 ID name class 或者相对路径 xpath
@friday 你书城 xpath click 成功了没 就是你 click 的第一个操作
对
Tester_web
回复
我贴的代码,除了最后一行定位元素的 XPATH,其他都是成功跑过的,没有任何问题,图和我的代码都展示的很清楚了,您可以直接指导一下你成功的代码吗