移动测试基础 robotframework-appium (客户端 UI 测试) 学习之路 (2):写好一个登录功能的 case
一、前面的话
距离上一次发帖已经三个月了 [捂脸]。。。这期间 Xcode 从 7 一跃变成了 8,废除了 UIautomation 那一套东西,导致原本写的自动化工程全都罢工了。网上扒帖子说 appium 升级到 1.6 之后才能用,就一直等啊等。。。。等到 1.6 出来了,由于工作上需求,开始研究 ios sdk 接口测试,ui 自动化就这么阴差阳错的被关进小黑屋了 [再次捂脸]。今天突然觉得还是应该把之前的学习总结一下(大部分内容是从同事、网上那里学习然后经过自己的加工理解,搬运过来~),希望给准备入坑 or 刚刚入坑 robotframework-appium 的新司机提供借鉴,也希望入坑许久的老司机多多指点。
如题目所示,‘’ 写好一个登陆功能的 case”,所以我打算从两方面来讲。
- 如何写一个登录 case
- 如何写好这个登录 case
那么什么是好呢?我觉得有着这么几点
- 可读性强;测试用例看起来条理清晰,易读,利于与他人协作
- 可维护性、可拓展性强;一方面,当 app 有新的功能功能模块时,可以在原有测试工程的基础上添加新功能的自动化用例,另一方面,当界面 ui 元素发生变化时(比如控件的 xpath 等发生变化时),能够改动工程中很少(最好只是一个)的地方去满足改动后的 app,也就是所说的控件定位与控件操作分离。
- 自动化测试用例健壮性强,尽量减少误报错的情况
- 对于每个 case 的判断(每个 case 可以分为执行和判断两部分)要尽量靠谱,避免出现自动化的测试用例通过了,但是实际上是有 bug 的情况。
以上是我认为,当我们开始去编写自动化测试用例时应该去考虑和遵循的原则,上面所提到的所谓的 “好”,也就是朝着这几个方向去努力。
二、写一个登录 case
2.1 一些概念
关于如何创建一个空白的 robotframework 工程,网上各种教程,再次不再赘述;同样 suite,test case,resource 以及 testlib(就是引入的 AppiumLibrary 之类的)这些比较基本的概念也不再解释了,如果对这些没有概念,赶紧去搜一搜查一查,然后再回来 :D。
2.2 写一个登录 case
在我上一篇文章就写到 robotframework 是基于关键字驱动的,其实就是由 testlib 或者内置的库(例如 BiultIn)提供了各种各样的关键字(功能)来让我们使用。那么一个登录 case 就比较容易想到是这样实现的:安装/打开 app,输入账号,输入密码,点击登录,然后验证登录是否正确跳转,关闭 app,结束。这些所述功能都由 testlib(AppiumLibrary)提供了对应的关键字,我们调用就 OK 了,效果下图所示
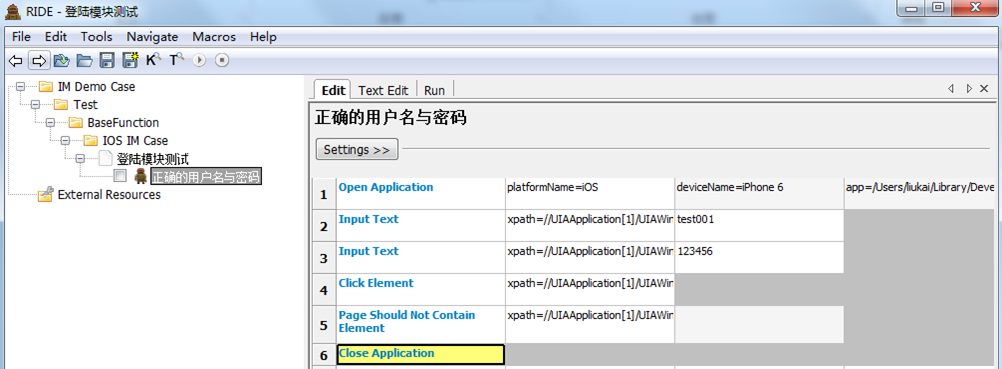
图中六个步骤,根据英文可以比较清晰的看出对应的步骤,额外说明的就是 ,判断是否正确登录这个过程,采用方法是登录动作完成后,判断跳转的页面不应该包含在登录页面的某个空间元素,一般来说自动化测试的判断方法大致就是在某个动作执行完后,判断当前页面应该/不应该包含某个控件或文本来实现的。
到这里 robotframework 易上手的优点就体现出来,感觉没有用特别难的门槛就初步入门了,但是离我们真正打造一个可用的测试用例工程还有要改进的地方,下面就着重讲一下如何写好这个登录 case。
三、写 “好” 一个登录 case
3.1 优化
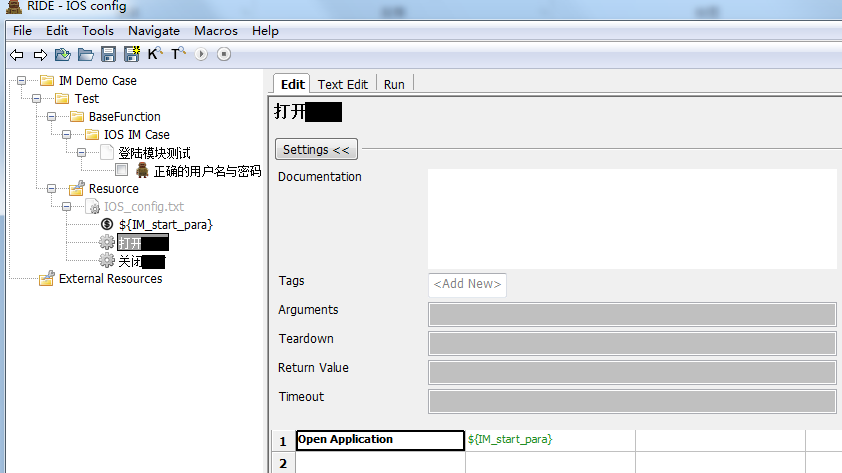
首先比较容易想到的一步,把 app 的配置信息单独挪出来,即这个工程是测得哪个 app 和该 app 对应的参数。这样整个工程看的更清晰。做法如下图所示,我们单独见了一个 resource 文件夹,里面分别有 app 的启动参数(存在了一个 dictionary 变量里),以及二次封装了一下 ‘’ 打开该 app‘’,‘’ 关闭该 app‘’ 的关键字,这样其他地方可以直接调用该关键字实现对应功能。这里我们是在每一个 test case 的 set up 里 填入 ‘’ 打开该 app‘’ 关键字,在 teardowm 里填入 ‘’ 关闭该 app‘’ 关键字,实现的效果就是每一个 case 执行前打开该 app,每一个 case 执行完后关闭 app,保证 case 与 case 之间的没有依赖关系。
3.2 再优化
然后我们继续思考,如果别的地方用到了登录功能,都需要复制这么好几行关键字的调用,会很麻烦。另一方面所有元素的定位变量(就是图中的控件的 xpath)都写死在每一个关键字里,一旦某个控件变量改动我们需要去改动所有用到该关键字的控件 xpath,所以我们要实现分离。具体的做法是我们在新建一个 UI 的文件夹,这个文件夹存放各个页面/某个功能的所涉及的所有操作和控件变量。如下图所示
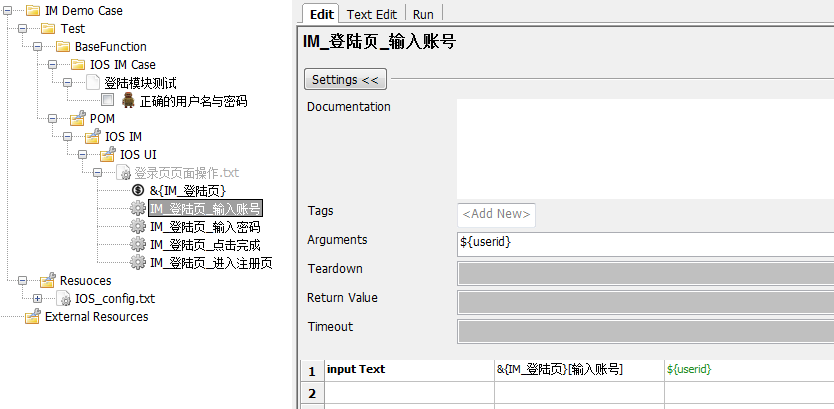
我们这里的思路 1.把控件的 id or name or xpath 放到这个 “登录页页面操作.txt” 这个 resource 文件中的 dictionary 变量里,这样别的地方调用时就用该变量名称即可,如果控件的 xpath 变化只需要改动底层的这个 dictionary 变量即可,其他地方均不需要改动。2.把该页面所有涉及的功能操作,封装好放到该 resource 文件下面,供上层的 testcase 调用,这样我们在写测试用例就去对应的页面的 resource 文件查询对应的关键字来调用即可,从工作流程和协作方面也更加方便,同时用中文对关键字进行封装,阅读起来也更加方便。这样我们最开始的 case 就变成下图的样子。
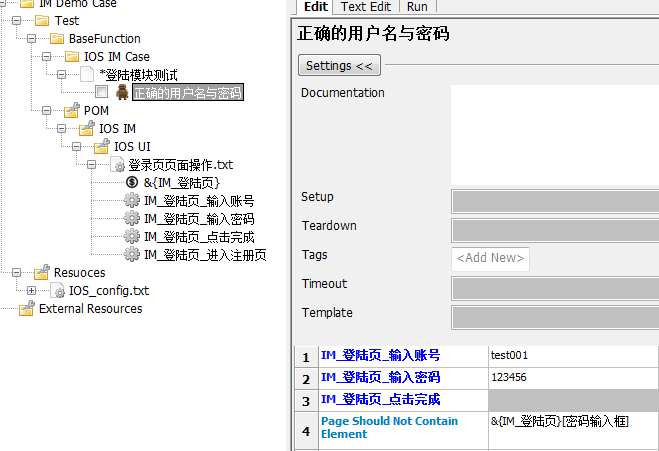
是不是看起来简洁了很多~(打开 app 和关闭 app 的关键字在 testcase 的设置项中的 setup 和 teardown 里)。同样注册功能,通讯录页等页面也可以类似登录页面,添加对应的 resource 文件,把控件变量和操作都放进去供上层测试用例使用。
3.3 再再优化
继续思考。。。由于登录功能我们使用的场景太多了,虽然现在看起来很清晰很明了,但是每次还是需要调用三个关键字操作,输入账号、密码、点击完成。所以我们继续再进行一次封装。我们再封装的这一层,就是把各个页面常用的操作做个集合。如下图所示
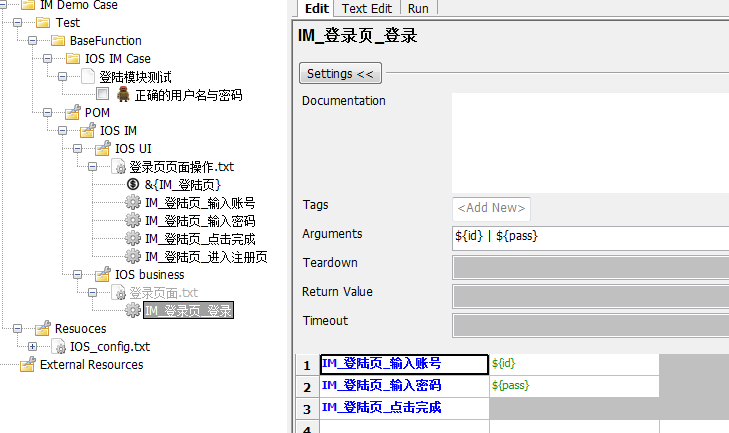
这样我们的登录 case 部分就变成了如下图所示
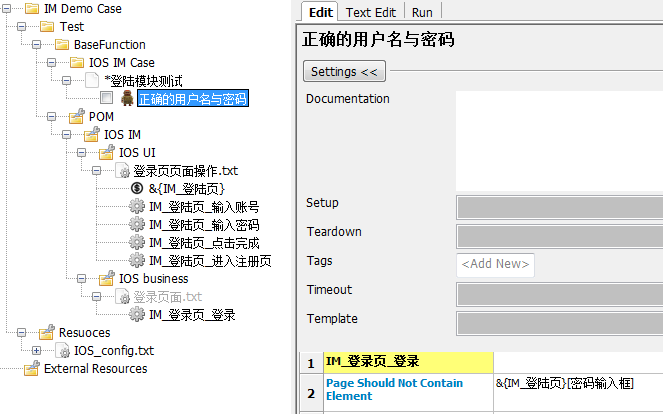
又简洁很多呢~~同样对于一些常用的集合操作,你都可以在 UI 页面元素操作关键字的基础上,去做二次封装,进一步让上层的用例看起来更简洁,更易用。
3.3 再再再优化
如果此时把用例跑几次,我发现有时候是会提示登录用例失败,但是实际并没有失败。原因就是我们目前的这个用例是在登录按钮点击完成之后,立马进行了判断。但实际情况呢,有时候由于网络等原因登录会画个 1-2s,而在这和期间如果页面还没来得及跳转,我们就进行判断,就会发生误判断,所以我们在发生页面跳转或者操作完毕之后不要急着去执行判断的关键字,而是让自动化程序等一等,然后再去判断,从而降低误判断的概率,如下图所示。(这里我是调用了 sleep 来实现等待,但是我看 robotframework 官方网站上面说,尽量少使用 sleep,一直也没太明白,也没有找到对应的替代方法,求大神指点~)
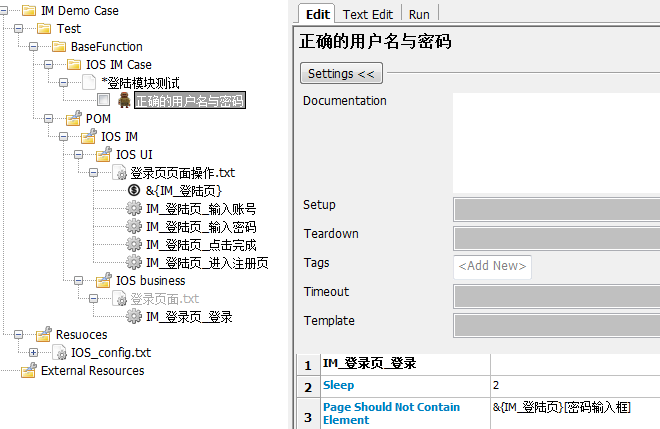
3.4 再再再再优化
其实下一步优化大家估计比较容易猜到了,就是对判断那块进行关键字二次封装。因为判断这个操作太常见了,所以我们就把他单独拉出来放在一个地方。效果如下图所示
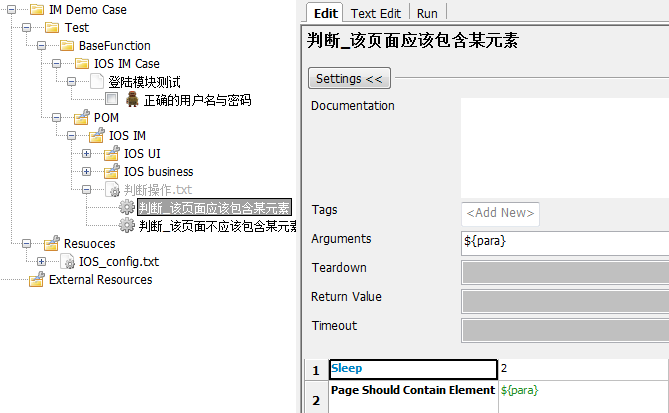
经过这一番折腾,我们的上层测试用例就变成了下图的样子。
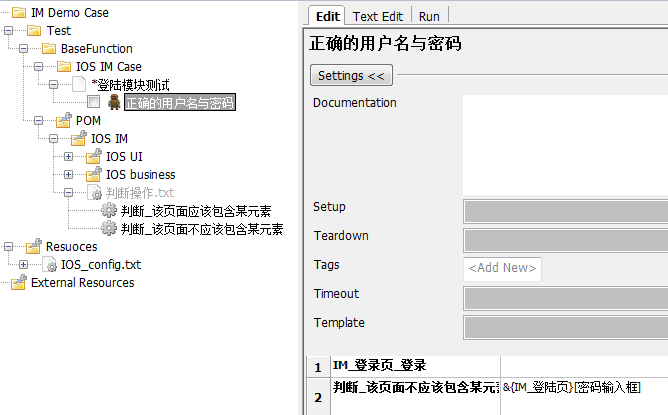
一个字:清爽!
3.5 再再再再再优化
其实讲到这里,优化思路基本上就是以上那些了,我这里只是用了下上面所述的思路以及结合实际的工作,又做了一些小优化。例如我们打开微信,会有四个 tab 键 “微信”“通讯录”。。这四个 tab 键呢你很难去归类他属于哪个页面的操作,所以我这里又单独创建了一个 resource 文件用来专门存放这种常用公共的控件操作。这里就不详细展示了。所以最终的目录结构就变成的如下图所示。
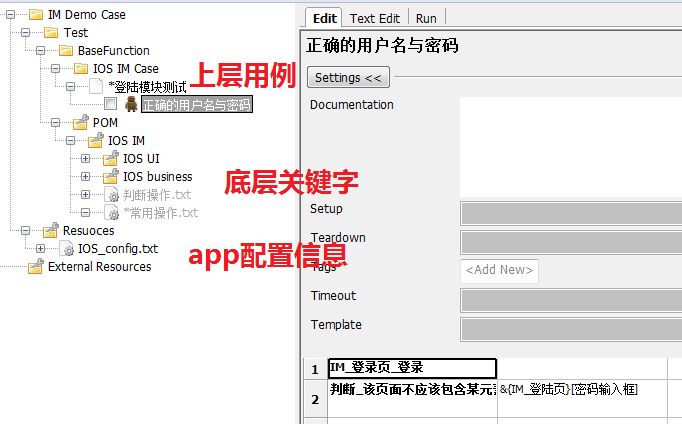
四、后面的话
以上就是我经过前一段学习的理解,如果有不对的地方请不吝指教。另外当然肯定还有其他优化的地方,也请老司机多多指教,同样也希望能够给新司机带来帮助,嘻嘻~
