腾讯WeTest 老司机乱谈『代码之美』 ——不要束缚了自己前进的脚步
Seastar 是一个优秀的 c++ 网络框架,代码量低,注释详细,可读性高,在一些基础部门已经开始应用。框架之中有很多美的地方值得我们学习,本文主要介绍了 Seastar 框架的代码之美和一些关键特性。对于代码之美是站在 C++ 程序员的角度来看的,比如 haskell 程序员看到这样的代码,也许会感叹:“Pieceofsh**!”。学习不同的语言,不同的框架,用不同的方法解决问题,可以让我们扩宽思路,打破思维局限,丰富自己思考问题的方式,提高自己解决问题的效率。比如用 haskell 实现一个快速排序,是这样的:
q_sort n=case n of
[]->[]
(x:xs)->q_sort [a|a<-xs,a<=x]++[x]++q_sort [a|a<-xs,a>x]
再对比一下你桌子上 C 语言版的《数据结构》,对,蓝色的那本。所以再次强调本文中提到的美,请从 C++ 语言的角度去看,不要跟其他语言比☺。
《程序员修炼之道》中有一段话 “Invest Regularly in Your Knowledge Portfolio”。对于技术人员来说,如果长期停留在自己的舒适区间你的优势将变成你的劣势。随时保持自己对技术的敏锐,停留在学习区间,光阴荏苒,日月如梭,多年之后,蓦然回首,你将发现自己已经蜕变。保持学习的态度,切莫辜负了岁月。
代码之美
先看一下这个框架以简驭繁的美。用一个 EchoServer 举例(省略了 main 函数)。

可以看到代码很简洁清晰。该代码监听了一个 1234 的端口,只要 accept,就发送一个固定字符串,然后关闭连接。这里面使用里 future/promise 模式还作为代码的胶合剂,把整个代码组织起来。同样整个框架也是用这个模式组织起来的。Future/promise(可以理解为常用的 Callback,只是换了种方式重新组织了起来)模式后面再详细介绍一下,公司的 taf 框架里也有这个模式可以参照对比一下。另外这里出现的 do_with 和 keep_doing 都是配合该模式的一些函数(看名字也可以大概猜出来干啥的),有兴趣可以参考源文件 future-util.hh(业界良心有注释)。
测试一下,注意这只是一个测试的例子,所以限定使用单线程否则会出错,如果正式使用应该使用 sharded 模板,使得实例运行在每一个 core 上面,这个后面再讲。
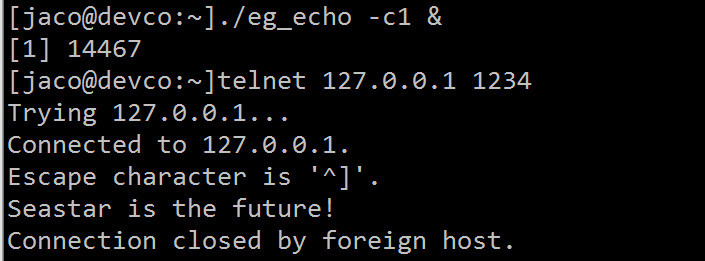
使用这个框架当然是可以提高开发效率,但是这是一把大威力的加特林机枪,并自带了炸膛功能,如果对框架理解的不够对 C++ 理解不够,那后果真是,不可限量。当然好的一面是,这个框架的代码量不大,注释比较详细,短时间就可以阅读所有核心代码。
性能之美
Seastar 框架在代码上是美的,在性能方面也毫不含糊。对基于 Seastar 的 httpd 来测试,已经具备在单节点(服务器)上每秒处理 700 万请求的能力,突破千万也指日可待。鱼(开发效率)和熊掌(运行效率)可以兼得了。

硬件配置
CPU:2x Xeon E5-2695v3
网卡:2x Intel Ethernet CNA XL710-QDA1(Transfer rate :40 Gbps,每 cpu 对应一个网卡)
使用 Seastar 开发的应用层代码和底层网络模式是隔离的,应用无需编译,可以通过配置选择使用 Linux 的 tcp 协议栈,还是使用 Seastar native 协议栈(用户态的 tcp 协议栈,zero-copy, zero-lock, and zero-context-switch,通过 DPDK 直接存取物理网络设备。DPDK 处理一个包只需要不多于 80 个 cpu 时钟周期)
架构之美
对于多线程程序,理论是完美的,现实是残酷的,下图就体现了理论和现实的差别。

Seastar 在架构的上都是一些成熟经验,每个 core 运行一个线程(称之为 shard),每个 core 上运行的线程只处理自己所负责的数据,把异步事件通过 Promises 的模式调度起来。这样的设计达到了 shared-nothing 的效果,所以避免了多核之间的锁,理论等于现实。当然这样设计当然避免不了 core 之间的交互,这个后面会提到。
下面给一个官方的配图。

我们看一下关键代码,每个线程运行的主循环,是 reactor::run(),是一个典型的 reactor 事件驱动模式,这个模块称之为引擎。

我们写的一个应用比如 httpd,通过 sharded 模板,然后跑到不同的 core 上去,这个模块称之为服务。

Parallel_for_each 循环 smp::count(可以通过启动参数进行重置少于物理 core 的数量) 次,通过 smp::submit_to 把服务创建到各个 core 的实例上去。这段代码也很美。
这里 Cpu 可以看作工厂,每一个 core 是一个车间,Reactor 可以看作为引擎,我们写的服务(例如 httpd)看作为机床,引擎驱动机床运转,每个车间互不干扰。
我们看一下 httpd,限定为 3 个车间(shard),可以看到有 3 个同样的引擎在处理同样的事情,互不干扰。这里底层使用了 SO_REUSEPORT(注意需要 3.9 以上的内核支持)。

Future/promise
这是框架的胶合剂。Future,一个数据结构代表了尚未决议的结果,并且可以绑定一个 Continuations(理解为回调函数)。Promise,就是这个结果的 Provider。
这里需要强调的是,各种框架里实现的 Promise 包括标准库里提供的,细节上都是有所不同的,需要注意其中的差别。
我们先看一个示例,第 11 行我们创建了一个 promise,并且它的 future 绑定了一个回调函数。当第 16 行对这个 promise 进行赋值的时候(比如异步结果从服务器返回),我们绑定的回调函数将会被调度,比如这里就跟公司的 taf 框架的实现有些不同,taf 中的回调函数会在对 promisesetvalue 的时候立即调用,seastar 还存在一个统一调度的过程(在第 19 行后才被调度)。同样后面的 sleep 函数也会返回一个 future,也绑定了一个回调函数。

执行结果,注意秩序顺序。

虽然只是一个小小的机制,但是带来的收益确是巨大的,在整个框架中这种机制把各个模块连接成了一个整体。回调那种丑陋的代码到处都有就不再举例了。
Programs must be written for people to read, and only incidentally for machines to execute.
— Harold Abelson and Gerald Jay Sussman
Message passing
前面说到了 shared-nothing,但是没有跨核通讯是不太可能的,对于跨核的通讯,框架中使用了无锁队列来实现。要达到无锁,不能出现多读多写,所以这里任意 2 核心之间都需要一个队列,对于 16 core 的 cpu,就需要 16*16-16 个队列(自己无需跟自己通讯)。

队列的定义与初始化

队列的轮询处理

smp_message_queue 的定义
这里看到了内存洁癖,工匠精神。这里有 2 块数据,发送端的统计(Acore 使用),和接收端的统计(Bcore 使用),中间插入了一个其他的数据结构。作者解释为了避免 cpu 的 prefecther 造成 A core 的 Cacheline 和 B core 的 Cacheline 加载了相同的内容 。这里多解释一下,如果多加载了会造成什么现象。我们以 Intel 处理器来举例,如果 prefecth 失败了,数据块 2(这里已经按照 cacheline 的大小 64 字节对齐)只存在于 B core 的 cacheline 中,状态可能为 E(Exclusive),如果中间没有其他数据结构 A coreprefecth 成功了。数据块 2 还存在于 Acore 中,cacheline 的状态可能为 S(Shared)。S 状态的写需要操作到 InvalidateQueue,必然在硬件层面上造成了性能上的负担。如果想了解相关细节,可以阅读《Memory Barriers: a Hardware View for Software Hackers》,注意这里不必深究,不同 cpu 的实现都不太一样。
后记
回到《程序员修炼之道》这句话 “Invest Regularly in Your Knowledge Portfolio”,有一个关键的问题,如何持之以恒的呢?其实这根本不是一个问题,如果你学习一个东西的过程感觉跟看《天龙八部》一样很精彩,那这会是一个问题吗?如果你的学习过程味同嚼蜡,那这也不是一个问题,因为可能已经走错路了。另外学习的过程中肯定有些东西无法完全理解,学会囫囵吞枣,不妨先放下,过一段时间回来看看,可能有不同的认识。学习是一个持续的过程,在这个过程中没有终点,但在过程之中自己会慢慢变得强大。
腾讯 WeTest 是腾讯游戏官方推出的一站式游戏测试平台,用十年腾讯游戏测试经验帮助广大开发者对游戏开发全生命周期进行质量保障。
腾讯 WeTest 提供:兼容适配测试;云端真机调试;安全测试;耗电量测试;服务器压力测试;舆情监控等服务。点击链接:http://wetest.qq.com/gaps/立即体验