前言:
在基于Docker 的分布式测试系统构建(一)中主要阐述了两个方面的内容,分别为开发此分布式测试系统的缘由以及 docker 基础镜像的构建和踩过的坑。在本篇中主要有 4 个部分的内容,分别为分布式测试系统的架构、技术实现细节简述、docker Node 节点的部署,以及前端实现。
---- 搜狗 ADTQ 测试组出品
一、分布式测试系统的架构
整体的测试架构主要 Docker Nodes 节点,Mongodb Broker,Mongodb DB, Front Web,这 4 个部分构成,其实现的架构简图如下所示:
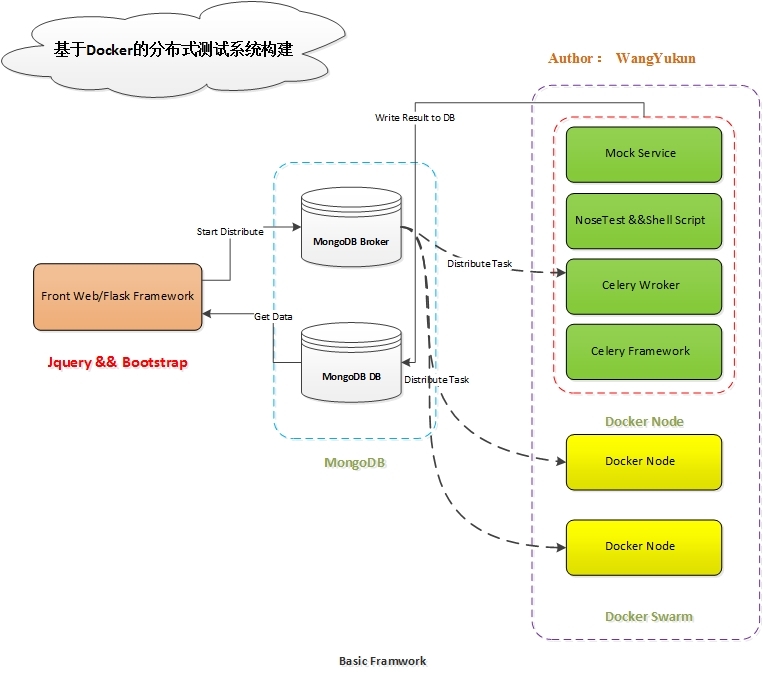
现在就每个部分简要叙述:
1. Docker Node 节点简述
Docker Node 节点主要有 Celery 异步框架,Celery Worker 任务,Nosetests 测试框架,Mock 服务构成。
其分布式实现主要有 Celery 来完成,通过编写 Celery worker 任务来实现具体的测试逻辑。由于业务逻辑本身的需求情况,分层级的调用关系成为实现的有效途径。Celery Worker 从 Mongodb Broker 接收需要完成的任务信息,然后调用 Node 节点本身的 Nosetests 框架和 Shell 脚本,最后调用 Mock Service 辅助完成测试任务。Celery Worker 完成待定的测试任务后,将测试结果写入 MongoBD 数据库中以备前端调用。
2. Docker Swarm
由于本系统的 docker node 节点并不多,考虑实现成本以及后续管理难易程度,本系统使用 Swarm 来管理 docker node 节点。如果 docker node 节点众多,可以考虑 k8s。关于 docker swarm 在第二部分会进行说明,这里不在叙述。
3. Mogondb
在本系统中,MongoDB 主要有两个方面的用途。用途一,作为 Celery 的 broker,接收前端发送过来的任务请求信息,当 broker 中有数据时,Celery Worker 从 broker 中获取数据,完成后续任务执行过程;用途二,作为 DataBase,Celery worker 完成任务后,将 result.json 数据写入到数据库中
4. 前端实现
由于部门内当前的 web 系统,使用的是 Flask Web 框架,所以前端主要由 Flask + Jquery + Bootstrap 实现
整个架构实现还算比较清晰,这对后期的维护也带来了方便。
二、技术实现有关细节简述
1. 关于使用 Celery 作为异步框架
由于测试用例本身都是基于 python 来开发的,并且 web 系统为 Flask,所以有充分的理由选择 Celery,关于异步框架的选择可以参考基于 Docker 集群的分布式测试系统 DDT (DockerDistributedTest)文章中对异步框架的对比。
2. 关于 Nosetests 的插件化
默认安装的 nosetests 是并未安装 json 插件的,但是提供 xml 格式。为了便于后续的结果处理,需要事先安装 json 插件。这里还有一个小插曲,由于之前从来都是使用默认的插件,都不太清楚原来 nosetests 也可以私自开发插件并安装,走了不少弯路。当然 json 的插件不需要自己再重复造轮子,可以直接下载安装。
由于 nosetests 提供了 xml 格式报告输出,所以第一时间选择的是 xml 作为最后的结果报文格式。用到--with-xunit 参数,同时需要安装 nosexunit 插件,但是安装的过程中,需要 coverage 特定版本的支持,为 2.85 版本。但是即使安装了 2.85 版本的支持包,https://pypi.python.org/pypi/coverage/2.85也同样会报错。
安装后,使用--with-xunit 来运行,会提示如下信息:NameError: global name 'pylint' is not defined。但是 pylint 已经被正确安装,出现这个错误很是匪夷所思。后来以为是 nosexunit 的版本的问题,现在安装的是最新版本 0.3.3,后来换成 0.3.2 和 0.3.1 都会出现错误,暂时还没有发现原因。所以最后还是使用 json 作为结果输出格式。
3. 关于测试数据以及环境准备
数据更新以及运行相关环境的准备,总体来说可以有两种大的途径,可总结为远程拉取,和本地挂载。
- 远程拉取
远程拉取可以有多种方法,第一种为通过 rsync 方法,将目的机中的数据远程拉取到 docker node 中,但是由于运行环境的数据量太大,所以当初认为并不可行。经过统计,在内网中完全拉取大小在 5.5G 左右的文件夹,需要 6 分钟左右,这个时间太长了。所以当初这个方案是被废弃了。
第二种方法为使用 svn 或者 git,svn 的话对于一些特别大的文件,会提示上传受到限制,这种情况下可以使用 svn ignore 对某些大的文件进行排除,后来发现由于文件夹太大的原因导致 svn 报错,使用 svn ignore 属性同样不能解决问题,现在 svn 报错也还无法查明原因。
- 本地挂载
通过将所需要的文件传输到 docker node 宿主机中,然后在运行 docker node 的时候通过 docker -v 本地挂载的形式,可以比较方便的解决环境问题。但是这样会使得部署一个 node 节点也复杂了一步,必须先同步环境相关数据到 docker 宿主机,这样又绕回了问题本身。所以本地挂载在本分布式测试系统中并不合适。
所以最后还是要考虑第一个方案。在仔细研究了 rsync 服务后,发现之前对 rsync 的研究并不深入,并不清楚 rsync 的差异性同步模式,通过这篇文章进行了详细的了解,https://segmentfault.com/a/1190000002427568,最后决定使用 rsync 的方式来进行文件同步。
举例如下:
rsync -auvrtzopgP --progress --delete --exclude "core.*" --exclude "your/log" 192.168.56.73::root/the/des/directory/ ./
#receiving incremental file list
#sent 17376 bytes received 2397856 bytes 536718.22 bytes/sec
#total size is 17239007382 speedup is 7137.62
通过设置--exclude 参数可以将不需要同步的文件排除,比如日志文件,这在实践中很有用
4. 关于分布式系统的执行粒度
在第一篇文章中我有提,现在的分布式系统执行的最小粒度是文件,也就是说 nosetests 在运行测试程序时,最小是全部执行某一个文件中所有的 case。比如 A.py 文件中有 10 个 cases,而 B.py 文件有 50cases,那么运行过程是 node1 运行 A.py 中的所有 case,node2 运行 B.py 中的所有 cases。由于 A.py 中的 cases 比较少,所以 node1 运行完成后,就闲置了。而总的运行时间有 node2 来决定,这种情况下系统的资源被浪费了。
当以 casesID 作为执行的基本单元时,这种情况就不复存在了,假如运行一个 case 为 1 分钟,那么原先需要运行 50min 才能运行完所有的 case。而在现有的执行粒度下,只需要 30min 就可以运行完所有的 case。关于 python 文件中 casesID 的收集,可以通过 nosetests --collect-only 命令来进行收集。
5. 关于 Celery worker 的命令
由于每一个 cases 的运行都需要 Mock Service 的支持,其主程序在内存中只允许运行一个实例,所以每一个 docker node 节点每次只可以运行一个 case,否则便会相互影响。在解决这个问题的时候走了不少弯路,后来在仔细研究了 celery worker 的命令后,发现可以通过 celery worker 的运行时参数就可以控制,当时便有一个柳暗花明又一村的感觉。
举例如下:
celery -A pc_ads_distribute_worker worker -c 1 --maxtasksperchild=1 -l INFO
其中的-c 参数表示 worker 并发为 1,--maxtasksperchild 表示每一个 worker 最多有几个孩子,同样设置为 1,这样就可以满足具体业务测试要求了
三、docker node 节点部署
在已经有了 docker 镜像后,需要搭建私有的 docker registry 来方面 docker 宿主机更新 docker 镜像,关于 docker 私有 registry 的搭建可以参考如下的网址,这里不再累述了:
https://github.com/docker/distribution/blob/master/docs/index.md
https://github.com/docker/docker.github.io/blob/master/registry/index.md
关于具体的使用方法示例如下:
#Images查询地址:
curl http://192.168.56.73:5000/v2/_catalog
#Tags查询:
curl http://192.168.56.73:5000/v2/pc/centos6.6_base/tags/list
#具体使用方法:
docker tag centos6.6:program_auto_v3.6 192.168.56.73:5000/pc/program_auto_v3.6
docker push 192.168.56.73:5000/pc/program_auto_v3.6
docker pull 192.168.56.73:5000/pc/program_auto_v3.6
由于我测试系统中,并未升级到引擎的 1.2.1 版本,所以需要下载额外的 swarm 镜像来完成,关于如何通过 swarm 来管理 docker node 镜像由于比较简单,就不多写了,有兴趣的可以参考http://dockone.io/article/227来配置。
四、前端部分
前端的展示主要有三个部分组成,分别为生成分布式任务、测试任务预览、测试任务统计与查询
1. 生成分布式任务及测试任务预览
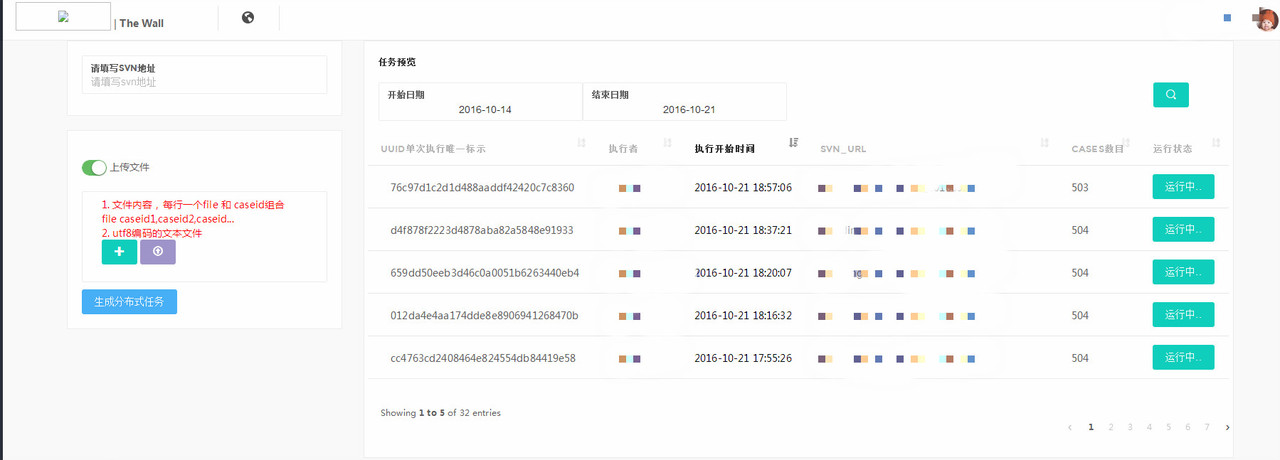
左边栏包含两个主要部分,分别为填写 svn 的地址以及上传文件。
svn 地址为必填,因为分布式测试任务必须要明确是对 svn 的哪个版本进行的分布式测试;上传文件为可选,如果不上传文件,则运行所有测试用例,如果上传文件,则只运行上传文件中写明的测试用例文件以及确定的 caseid,这个功能在只需要运行测试用例集中的某一个子集时比较有用,右边为生成的任务预览模块,每生成一次任务则新增一条记录。
2. 任务执行统计
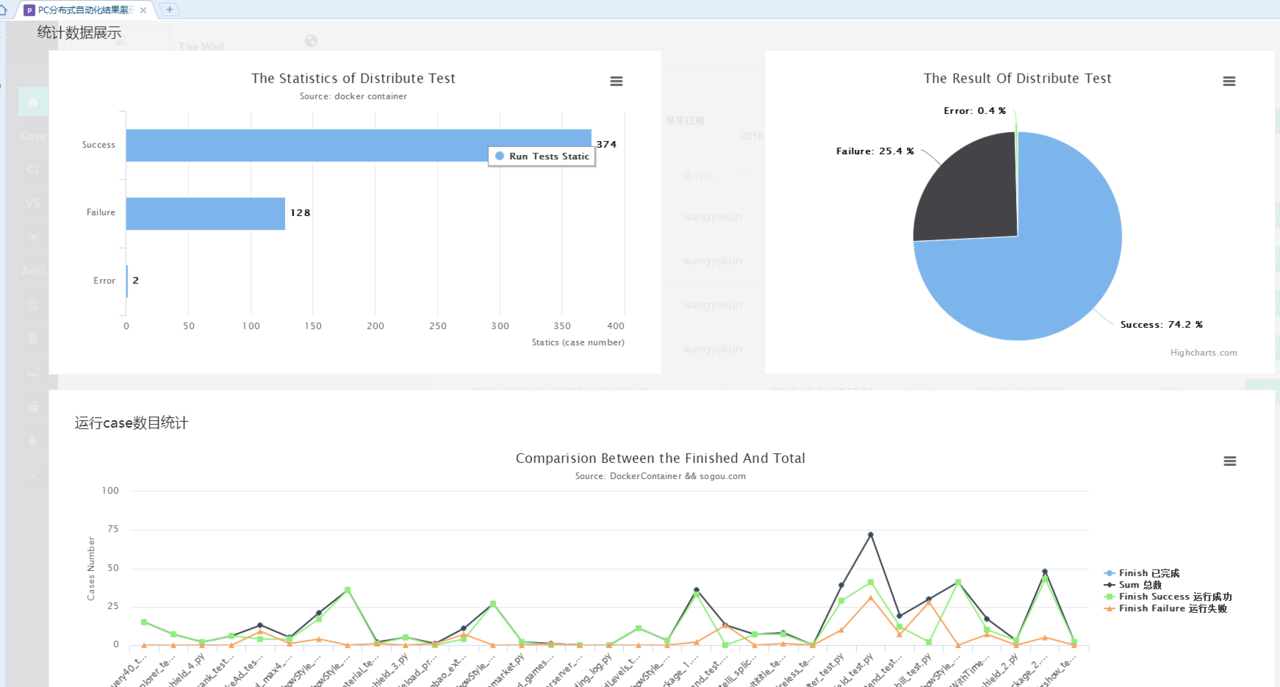
这个图比较清楚就不再说明了
3. 具体任务查询
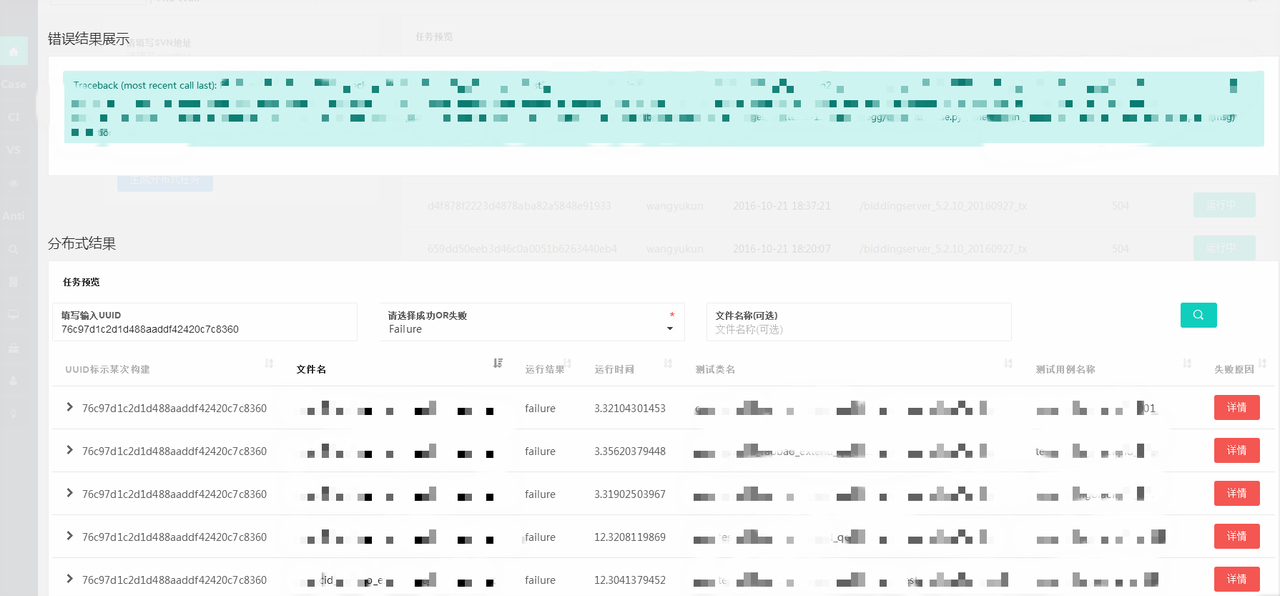
可查询某一次具体的执行情况,必须根据运行的成功还是失败,或者根据具体的文件名来查询都可以
五、结语
这两篇算是对之前所做工作的一个总结吧。一天连写两篇,有种写吐了的感觉,好了,就这样吧,希望对各位童鞋有帮助……