MinerU 作为火出圈的 OCR 领域 SOTA 模型,它的成长之路上也少不了 “数据烦恼”——训练数据质量参差、模型解析结果偶有缺陷……
那么,MinerU 是如何一步步突破瓶颈、提升精度的呢?
答案就在它背后的 “数据守护者”:Dingo。
Dingo 是一款数据质量评估工具,能够自动检测数据集中的质量问题。它内置多种评估规则与模型评估方法,同时支持自定义扩展,适用于文本与多模态数据集,覆盖预训练、微调到评测等不同阶段。
今天我们就来揭秘 Dingo 在 MinerU 生产流程中,如何化身 “数据侦探”,覆盖全面的 OCR 问题指标,助力模型持续进化!👀
Dingo 开源仓库:
https://github.com/MigoXLab/dingo
全面的 OCR 问题指标体系
首先,让我们通过下表直观了解 Dingo 所覆盖的多维度 OCR 问题指标体系,为模型质检与优化提供了系统化的参考标准:
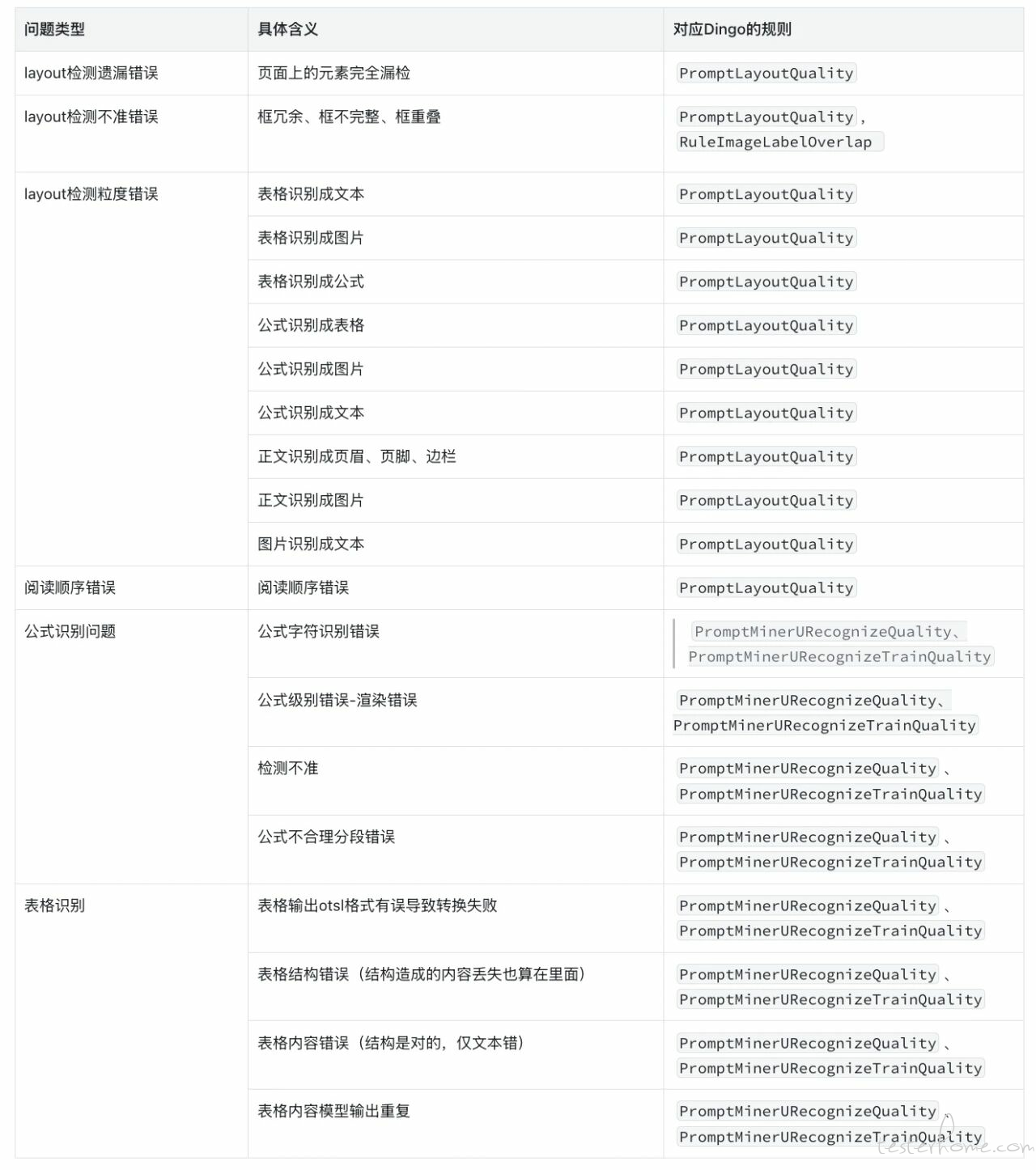
从 layout 结构错误、识别精度偏差到公式与表格解析异常,Dingo 的规则库实现了对 OCR 全链路问题的精细化覆盖。不同类型的检测规则(如 PromptLayoutQuality、PromptMinerURecognizeQuality 等)可灵活组合应用,为模型提供可追溯、可量化的质量诊断依据。
Dingo 的工作流:如何筛查问题
了解了这些指标后,我们来看看 Dingo 是如何在实际研发中进行问题筛查的。如果你也是 OCR 模型的开发者,下图的 Dingo 质检 OCR 工具的流程图将非常直观:
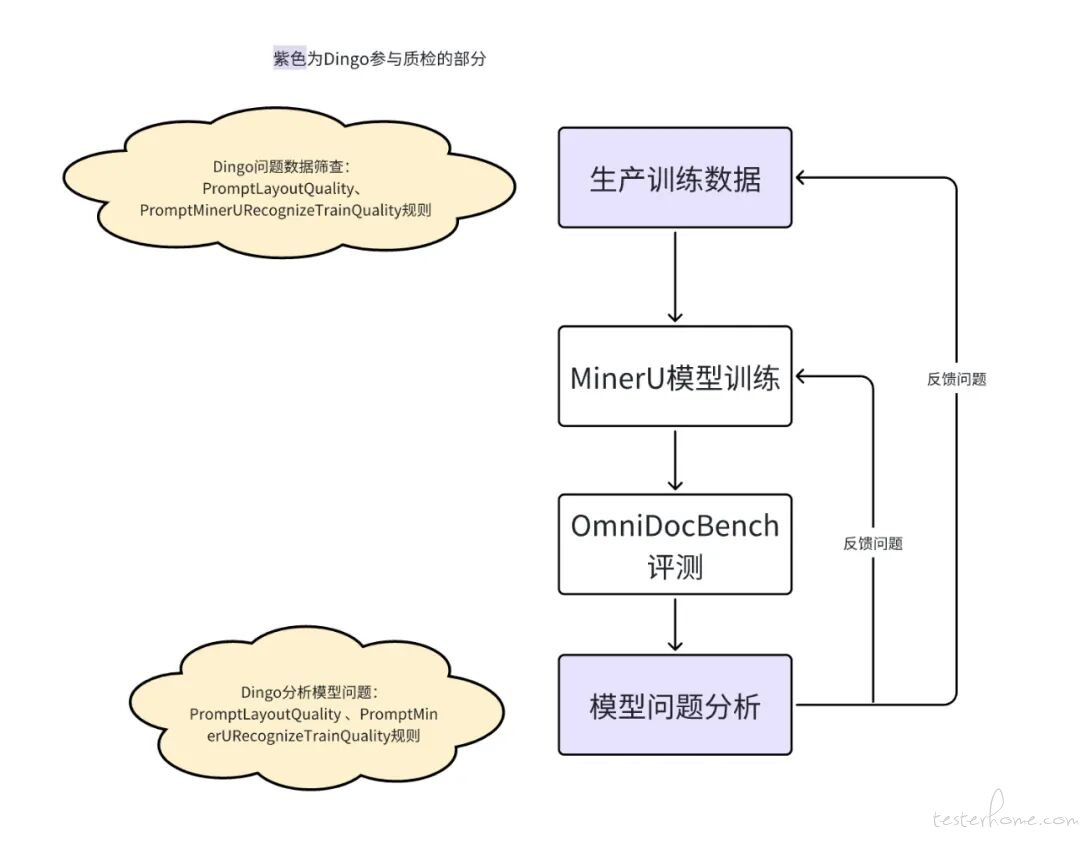
Dingo 如何深度融入研发流程
如上图所示,我们将 Dingo 深度整合到了模型研发的全流程中,具体体现在以下几个关键环节:
1. 数据质检:利用 Dingo 对原始训练数据进行初步筛查。
2. 标注复核:在微调数据生产环节,通过 Dingo 对人工标注结果进行自动化检查,确保数据质量。
3. 模型诊断:模型训练完成后,除使用 OmniDocBench 进行量化评分外,我们会运用 Dingo 对模型输出进行问题分类与定位,并辅以人工核查,完成系统性 “体检”。
4. 迭代驱动:在模型分析阶段发现的所有问题,都将被汇总为具体的产品需求,直接指导下一版本的模型迭代。那么,在训练/微调数据质检和模型质检分析中,Dingo 具体是依赖哪些规则来诊断的呢?详细解读如下。
环节一:训练/微调数据质检
在模型微调数据生产阶段,Dingo 就提前介入,对人工标注数据进行多维度质量检查,快速定位标注错误,确保数据 “干净可用”。我们检查的质检规则包括:
1. Layout 检测遗漏:在基于检测的两阶段模型中,若页面中的元素未被检测出,将直接导致该部分内容从识别结果中丢掉。
- Layout 检测不准:检测框出现冗余、不完整或相互重叠等问题,会进一步导致 OCR 输出内容中出现文本分段错误、信息缺失或重复输出。
- 识别粒度错乱:当表格被识别为普通文本、公式被误判为图片,或正文内容被错误归类为页眉/页脚时,将引发结构理解错误,具体表现为表格失去行列结构、公式无法以符号形式识别,以及正文被错误过滤或忽略。
- 阅读顺序错位:若 Layout 分析所输出的区域逻辑顺序错误,将直接导致 OCR 识别出的文本内容在顺序上混乱,严重影响后续解析语料在 RAG/大模型训练场景应用数据的流畅性。
错误标签:检测遗漏错误模型输出:
{
"error_id": 1,
"error_type": "检测遗漏错误",
"error_location": "页面上有两处明显的检测遗漏:1. 页面右上角的页眉 '英文缩略语' 未被检测。 2. 页面右下角的页码 '435' 未被检测。",
"suggestion": "应为页眉添加新的边界框并标记为 'header',为页码添加新的边界框并标记为 'page_number'。"
}
示例截图:

环节二:模型评测与问题定位
模型训练完成后,通过权威评测集 OmniDocBench(https://github.com/opendatalab/OmniDocBench)对模型进行量化评估,精准对比版本间差异与业界表现。更重要的是,Dingo 会进一步对模型输出进行深度 “体检”,从检测与识别两大维度定位问题症结:
维度一:文档检测类问题→ PromptLayoutQuality
文档检测类问题不仅会出现在训练数据中,也会出现在模型预测结果中,我们的输入基于带类别和阅读顺序的 layout 检测框,针对以下问题判断:
- Layout 检测遗漏 → 页面上的元素漏检
- Layout 检测不准 → 框体冗余/不完整/重叠
- 识别粒度混淆 → 表格/公式/图片/正文类别相互误判
- 阅读顺序异常 → 阅读顺序混乱,导致解析的结果不流畅
错误标签:阅读顺序错误模型输出
{
"error_id": 1,
"error_type": "阅读顺序错误",
"error_location": "模型输出的元素ID顺序不符合自然的阅读习惯。当前的ID顺序为...元素2(页眉网址) -> 元素3(左侧边栏) -> 元素4(页眉标题)...。这个顺序在读取页眉中间插入了边栏内容,打断了对页眉区域的连续阅读。",
"suggestion": "应调整ID顺序,使得同属于页眉的元素1、2、4在序列中是连续的,例如将顺序调整为...1, 2, 4, 3...,即先完成页眉区域的阅读,再阅读边栏和正文。"
}
示例截图:

维度二:识别与格式类问题→ PromptMinerURecognizeQuality
基于 OmniDocBench 分析 Badcase,我们可以采样标注的 GT 来作为参考对预测结果的错误分类,具体错误如下:
- 公式识别:字符错误、内容重复
- 表格问题:格式错乱、结构错误、内容错误、重复输出
- 段落问题:段落异常粘连或拆分
- 列表与标题:列表项合并异常、标题格式丢失、分级错误
- OCR 识别:字符识别错误
错误标签:标题相关问题 - 标题格式丢失, 表格识别相关问题 - 表格内容错误 Dingo:
{
"data_id": "page-138026c8-3c0e-4d98-a389-f009a550ce1f",
"prompt": "# 树立远大理想 筑梦美好未来\n\n<table border=\"1\"><tr><td>我的人生理想</td><td>①____▲____</td></tr><tr><td>我的行动计划</td><td>②____▲____</td></tr></table>\n\n答案略。(根据自身实际情况回答,符合题意即可)\n\n",
"content": "树立远大理想 筑梦美好未来\n\n<table><tr><td>我的人生理想</td><td>①▲</td></tr><tr><td>我的行动计划</td><td>②▲</td></tr></table>\n\n答案略。(根据自身实际情况回答,符合题意即可)",
"error_status": false,
"type_list": [ "表格识别相关问题", "标题相关问题" ],
"name_list": [ "标题相关问题-标题格式丢失", "表格识别相关问题-表格内容错误" ],
"reason_list": [ "{\n\"errors\": [\n {\n \"bbox_id\": \"1\",\n \"bbox_type\": \"text\",\n \"error_category\": \"标题相关问题\",\n \"error_label\": \"标题格式丢失\"\n },\n {\n \"bbox_id\": \"2\",\n \"bbox_type\": \"table\",\n \"error_category\": \"表格识别相关问题\",\n \"error_label\": \"表格内容错误\"\n }\n]\n}" ],
"raw_data": { }
}
示例截图:


从训练数据准备到模型迭代,Dingo 是 MinerU 的 “质量守护者”。
当前的质检规则与标签体系还有持续进化的空间,为了打造更精准的 OCR 质检体系, 诚邀社区贡献者携手共建,共同优化质检规则、完善 Prompt 与标签体系,让 OCR 模型的 “火眼金睛” 更锐利。
小提示:建议基于 Gemini 2.5-Pro 构建质检模型,以获得更高的识别准确率。