AI测试 ElevenLabs 估值翻倍至 66 亿美元;B 站开源 IndexTTS2;通义推出 Qwen3-ASR-Flash 丨日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的技术」、「有亮点的产品」、「有思考的文章」、「有态度的观点」、「有看点的活动」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@Jerry fong,@ 鲍勃
01 有话题的技术
1、告别「AI 味」:Bilibili IndexTTS2 发布,实现影视级情感与上下文定制化语音合成
在语音合成技术不断演进的背景下,早期版本的 IndexTTS 虽然在多场景应用中展现出良好的表现,但在情感表达的细腻度与时长控制的精准性方面仍存在提升空间。为了解决这些问题,并进一步推动零样本语音合成在实际场景中的落地能力,B 站语音团队对模型架构与训练策略进行了深度优化,推出了全新一代语音合成模型——IndexTTS2 。
相比于自回归(Autoregressive, AR)系统,非自回归(Non-Autoregressive, NAR)系统的一大优势在于生成时长可控,便于对语速、节奏进行精确编辑。而在 IndexTTS2 中,研究团队创新性地提出了一种通用于 AR 系统的「时间编码」机制,首次解决了传统 AR 模型难以精确控制语音时长的问题。这一设计让模型在保留 AR 架构在韵律自然性、风格迁移能力、多模态扩展性等方面优势的同时,也具备了合成定长语音的能力。该技术已率先应用于 B 站「原声视频翻译」功能,目前正在内测,部分用户已可体验。
在实际使用中,往往难以同时获得音色匹配且情感准确的参考音频。为此,IndexTTS2 引入了音色与情感解耦建模机制,除了支持单音频参考以外,额外支持分别指定音色参考与情感参考,实现更加灵活、细腻的语音合成控制。同时,模型还具备基于文本描述的情感控制能力,可通过自然语言描述、使用场景描述、上下文线索等进行精准调节合成语音的情绪色彩。
IndexTTS2 在灵活性与可控性之间实现了更优平衡,不仅支持高质量的零样本语音合成,还显著提升了语音在情感表达维度的真实感与表现力。其合成语音情绪自然饱满,贴近真人,广泛适用于 AI 配音、有声读物、动态漫、视频翻译、语音对话、播客创作等场景,是推动零样本 TTS 走向实用化的重要里程碑。
为进一步推动语音合成技术的开放创新与行业应用落地,官方已将 IndexTTS2 的相关研究成果整理为论文《IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech》,现已发布于 arXiv,并已于 9.8 正式开源 IndexTTS-2.0 的推理代码与模型权重,诚邀关各位开发者、研究者、内容创作者前往项目仓库点击 。
项目仓库:
https://github.com/index-tts/index-tts
(@ 魔搭 ModelScope 社区)
2、AI2 OLMoASR 开源:挑战 Whisper,树立 ASR 透明化新标杆
艾伦人工智能研究所(AI2)近日发布了「OLMoASR」,一套完全开源的自动语音识别(ASR)模型系列。该系列模型在性能上可与 OpenAI 的 Whisper 等闭源系统相媲美,同时以前所未有的透明度公开了所有训练数据标识符、过滤步骤及训练方案,旨在推动 ASR 领域向更开放、更科学的基础发展。
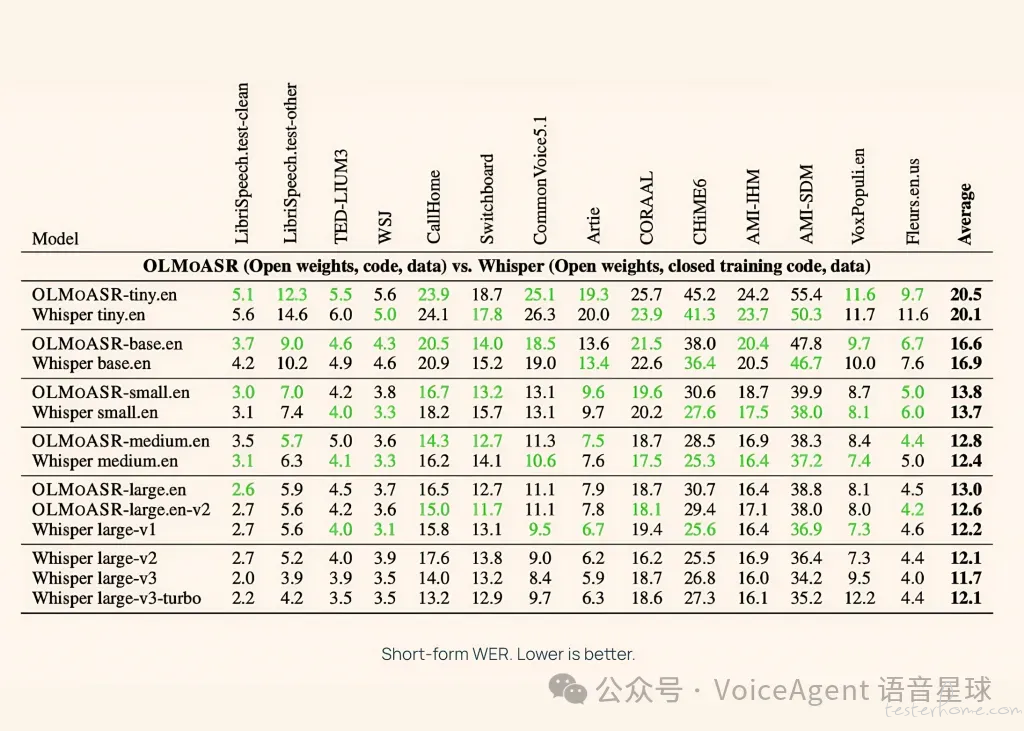
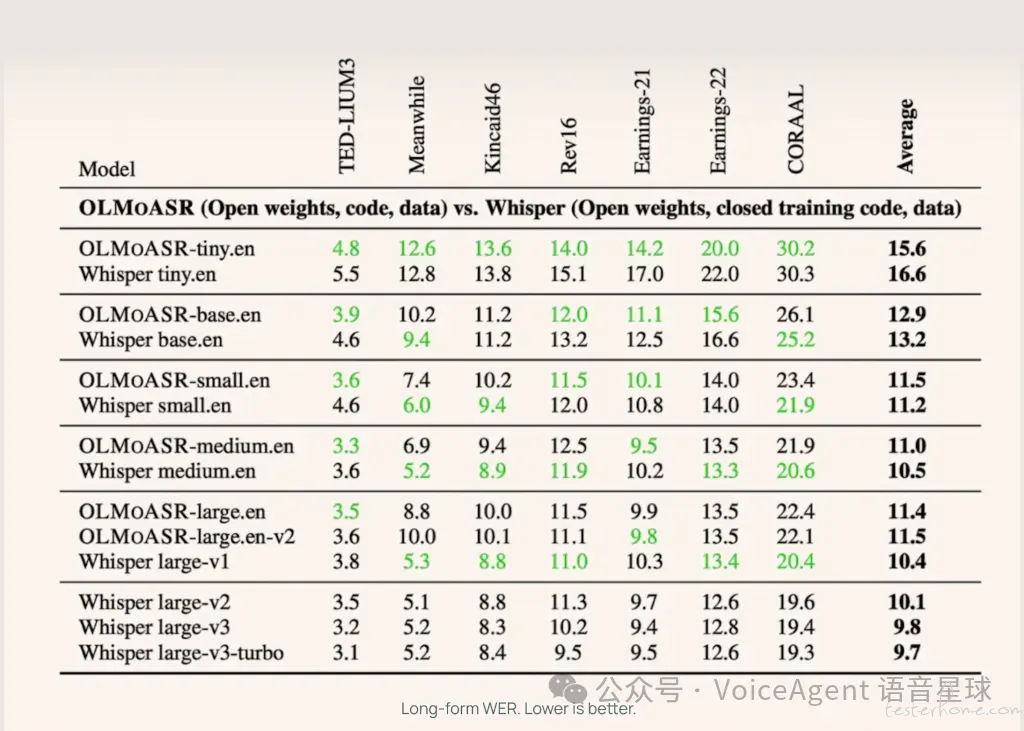
关键亮点
性能比肩业界标杆:「OLMoASR」系列模型,特别是 1.5B 参数的「large.en-v2」版本,在长语音任务中的词错误率(WER)为 12.6%,与「Whisper large-v1」的 12.2% 仅相差 0.4%。中型模型(7.69 亿参数)在短语音和长语音任务上的 WER 也几乎与「Whisper medium.en」持平。
全流程开源与透明化: AI2 不仅公开模型权重,还首次提供了训练数据标识符、过滤步骤、训练方案和基准测试脚本。这种彻底的透明度解决了闭源 ASR 系统缺乏可验证性的问题,极大促进了 ASR 研究的可重复性和科学进步。
多尺寸模型系列:「OLMoASR」涵盖从 tiny.en(39M 参数) 到 large.en-v2(1.5B 参数) 等六种针对英语训练的模型尺寸。这为开发者提供了灵活性,可根据计算资源和准确性需求选择最合适的模型,适用于从嵌入式设备到大规模研究的多种场景。
高质量数据集: 发布了包含约 300 万小时弱监督语音的「OLMoASR-Pool」和经过严格过滤、质量更高的约 100 万小时「OLMoASR-Mix」数据集。这些数据集的公开,配合详细的过滤方法,显著提升了模型的零样本泛化能力和领域适应性。
发布计划与范围
「OLMoASR」模型权重、训练代码和数据集标识符已通过 GitHub 和 Hugging Face 平台全面开放。开发者可以使用简单的 Python API 进行音频转录,并能根据提供的训练方案对模型进行微调,以适应特定领域的需求。
详细链接:
https://allenai.org/blog/olmoasr(@Voice Agent 语音星球)
###
02 有亮点的产品
1、AlterEgo:捕捉大脑意图信号,实现无声交流与智能操控
它能读出你想说还没说出来的话,也可以与其他人进行无声交流,等于失语者靠它能重新说话了。它还可以把无声语音转成其他语言,进行实时翻译。还能跟其他设备连接,比如相机、摄像头,进行无声交互。
Alterego 被动读取大脑在「准备说话」时下发给语音系统的微弱电信号,只在心里默念还没出声前,就会被捕捉到。但是,它不会读取你的任意思绪,只识别你想对外表达的内容。
AlterEgo 硬件类似耳机,佩戴在头部和面部,设备上有多个高精度的电极传感器,放置在面部和颈部,喉部、舌骨、颊部、下巴以及眼眶下方等位置。
体验地址:
https://www.alterego.io/(@AIGCLINK\@X)
2、通义千问推出 Qwen3-ASR-Flash:多语言、高精度、创新支持歌声及上下文定制化语音识别
阿里云正式推出通义千问系列最新的语音识别模型 Qwen3-ASR-Flash,它基于 Qwen3 基座模型,经海量多模态数据以及千万⼩时规模的 ASR(自动语音识别)数据训练构建而成。
Qwen3-ASR-Flash 实现了⾼精度⾼鲁棒性的语⾳识别性能,⽀持 11 种语⾔和多种⼝⾳。与众不同的是,Qwen3-ASR-Flash ⽀持⽤户以任意格式提供⽂本上下⽂,从⽽获得定制化的 ASR 结果,同时还⽀持歌声识别。
核心技术亮点:
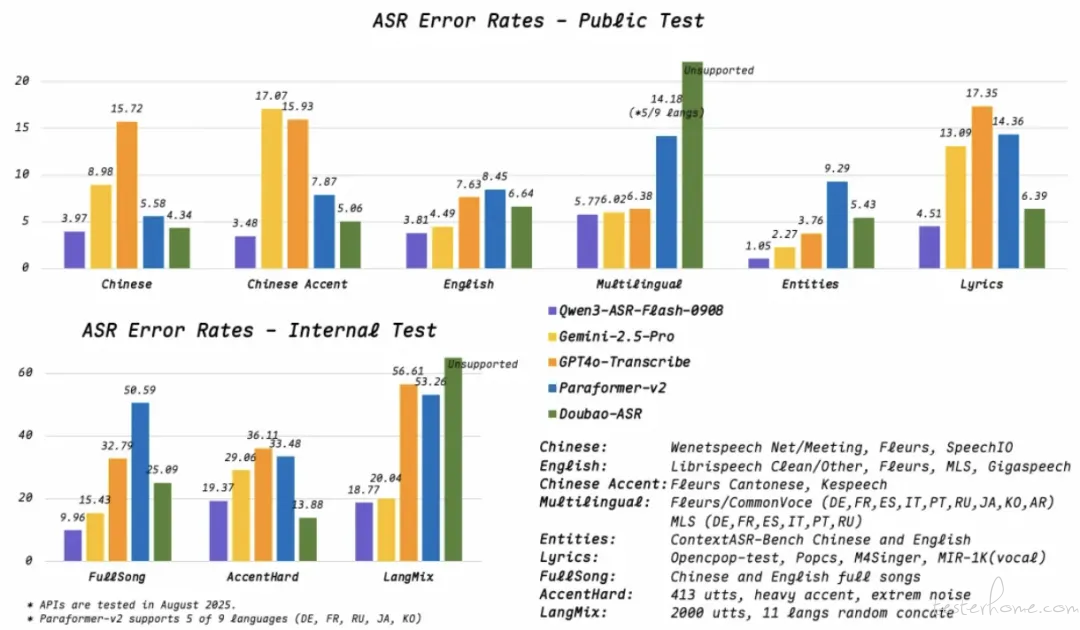
领先的识别准确率:Qwen3-ASR-Flash 在多个中英文,多语种 benchmark 测试中表现最优。
惊艳的歌声识别能力:支持歌唱识别,包括清唱与带 bgm 的整歌识别,实测错误率低于 8%。
定制化识别:用户可以以任意格式(如词汇表、段落或完整文档)提供背景文本,模型能智能利用该上下文识别并匹配命名实体和其他关键术语,输出定制化的识别结果。
语种识别与非人声拒识:模型能精确分辨语音的语种,自动过滤非语音片段,包括静音和背景噪声。
鲁棒性:面对长难句、句中语言切换和重复词语等困难文本模式,以及在复杂的声学环境中,模型仍能保持高准确率。
语种支持:
中文: 包括普通话以及四川话、闽南语、吴语、粤语等主要方言。
英语: 支持英式、美式及多种其他地区口音。
其他支持语言: 法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语、阿拉伯语。
体验方式:\
https://modelscope.cn/studios/Qwen/Qwen3-ASR-Demo(@ 通义千问)
3、Google AI 模式全球发布五种新语言支持,深化本地化搜索体验
#####
Google 今日宣布,其强大的 AI 搜索体验——AI 模式,现已在全球范围内推出,新增支持五种语言:印地语、印尼语、日语、韩语和巴西葡萄牙语。
Google 强调,构建一个真正全球化的搜索体验,其深度远超简单的语言翻译。它要求对本地信息有细致入微的理解。通过定制版 Gemini 2.5 搜索引擎,Google 在语言理解方面取得了巨大进步。
AI 模式凭借 Gemini 2.5 先进的多模态和推理功能,能够确保在其支持的每种新语言中都具有高度的本地相关性和实用性。这意味着,用户不仅能用自己偏好的语言提问,而且能获得与本地文化和语境更贴合的 AI 搜索结果。(@Google Blog )
4、估值翻倍至 66 亿美元,ElevenLabs 启动 1 亿美元员工股票回购
#####

AI 音频独角兽 ElevenLabs 宣布启动一项 1 亿美元的员工股票回购计划,公司估值达到 66 亿美元,是九个月前 C 轮融资的两倍。此举反映了其惊人的商业增长——年经常性收入(ARR)已突破 2 亿美元,且企业级业务正成为其核心增长引擎,标志着公司正从工具型产品向平台级解决方案成功迈进。
财务与估值猛增: 本次回购由现有投资者 Sequoia 和 ICONIQ 领投,将公司估值推高至 66 亿美元。公司财务状况强劲,ARR 已突破 2 亿美元,并预计在年底达到 3 亿美元。
企业业务成为新引擎: 企业客户收入在过去一年中增长了 200% 以上,正迅速接近与自服务客户 50/50 的收入比例。其技术已被 Cisco、Epic Games、Adobe 和 NVIDIA 等行业巨头采用。
平台化战略见效: 增长主要由「ElevenLabs Agents Platform」驱动。开发者和企业已使用该平台构建了超过 200 万个「对话式智能体」(conversational agents),用于客服、应用交互等多种场景。
核心产品持续创新: 除了面向企业的智能体平台,其「Creative Platform」也持续迭代,近期发布了表现力更强的文本转语音模型「Eleven v3」和文生音乐模型「Eleven Music」。(@ElevenLabs Blog)
03 有态度的观点
1、吴恩达:智能体当下的最大瓶颈在于「人」
#####
近期,斯坦福大学计算机科学系副教授吴恩达接受《No Priors》节目采访,其在节目中与主持人共同探讨了当前 AI 技术发展的核心驱动力、智能体(Agentic AI)的实现障碍,以及未来行业变革的关键趋势。
他认为,当前由少数顶级公司主导的「规模至上」叙事,已严重带偏了公众认知。尽管模型扩展仍有空间,但其难度已极其巨大。真正的突破将来自多个维度 —— 智能体工作流、多模态创新、实践应用驱动等。吴恩达表示,AI 的发展绝非单一路径,而是由无数聪明人从不同方向共同推动的多元化进程。
针对智能体,吴恩达坦言当前智能体领域「营销热度的增速远超实际业务进展」。实现真正智能体应用的最大障碍,并非技术组件(如计算机控制、安全护栏),而是人才与工程化流程的缺失。
在当前最具自主性的应用案例中,他特别提到了 AI 编程助手:其展现出的多步骤规划与执行能力,使其成为当前最成熟、最具经济价值的智能体之一。
值得一提的是,吴恩达提出一个尖锐的观点: 「现在看来,太多 2022 年的工作方式在 2025 年已经完全失效。」 他预测,未来五年最令人震撼、且多数人尚未意识到的,将是拥抱 AI 的个体所获得的能力提升。无论是专业工作还是个人事务,善用 AI 的人将获得「超乎想象的超能力」。
(@APPSO)


阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻