AI测试 Orpheus 语音模型支持中文预训练和微调,模拟细微语音特征;谷歌版 MCP 来了,A2A 协议让不同厂商 Agent 协作

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@qqq、@ 鲍勃
01 有话题的技术
1、Orpheus 语音模型发布多语种版本,提供中文预训练和微调模型
Canopy Labs 近日发布了 Orpheus Multilingual 语音模型,旨在提升 AI 语音生成在非英语语种的表现力。本次发布的一大亮点是,该模型已支持包括中文、法语、德语、西班牙语、意大利语、韩语和印地语在内的多种语言。
Orpheus Multilingual 致力于提升语音生成的真实感和自然度。不同于以往的模型,它专注于于模拟人类更细微的语音特征,力求让 AI 语音更接近真人:
情感表达: 根据语句内容,调整语音的情感基调,例如表达喜悦或悲伤。
非语音元素: 模拟人类自然发出的非语音声音,例如笑声、叹息等。
口语化特征: 模拟口语中常见的停顿、重复和自我修正等特征,使语音更自然。
据悉,即便在训练数据有限的情况下,该模型也能生成高质量的语音。
本次发布内容包括:
- 预训练和微调模型: 针对上述多种语言,提供预训练和微调后的模型。
- 多语种训练指南: 提供详细的训练指南,鼓励开发者基于该模型进行定制化开发。
- 开源代码: 相关代码已开源,方便研究者和开发者使用。
特别值得关注的是,该模型提供中文预训练和微调模型,为中文语音应用的开发提供了更灵活的选择。
2、「谷歌版 MCP」来了,开源 A2A,不同厂商 Agent 也能协作
谷歌推出 A2A 协议 ,即 Agent2Agent,能让 AI Agent 在不同生态系统间安全协作,而无需考虑框架或供应商。
不同平台构建的 AI Agent 之间可以进行 通信、发现彼此的能力、协商任务并开展协作 ,企业可通过专业 Agent 团队处理复杂工作流,重点是开源的。
借助 A2A 协议,招聘这件事儿还能这么玩:
在谷歌 Agentspace 统一界面中,招聘经理可以向自己的 Agent 下达任务,让其寻找与职位描述、工作地点和技能要求相匹配的候选人。
然后,该 Agent 立马与其它专业 Agent 展开交互,寻找潜在候选人。
用户会收到推荐人选,之后可指示自己的 Agent 安排进一步的面试,面试环节结束后,还可以启用另一个 Agent 来协助进行背调。
总结来说,A2A 遵循五大设计原则:
- 发挥 Agent 的能力: 专注于让 Agent 以自然非结构化的模式进行协作,即使它们之间没有共享内存/工具/上下文信息,致力于实现真正的 Agent 多场景,不会将某个 Agent 局限为一种「工具」。
基于现有标准构建: 该协议是在包括 HTTP、SSE、JSON-RPC 等现有常用标准基础上构建的,更容易与企业日常使用的现有信息技术堆栈相集成。
默认安全: 支持企业级身份验证和授权,在推出时其安全性符合 OpenAPI 级别的认证标准。
持长时间运行的任务: 各种场景 A2A 都能应对,包括从快速完成的任务,到那些可能需数小时甚至数天才能完成的深入研究任务。整个过程中,A2A 可为用户提供实时反馈、通知以及状态更新。
模态无关: 支持包括音频、视频等在内的各种模态。
据了解,A2A 已经得到了包括 Atlassian、Box、Cohere、Intuit、Langchain、埃森哲、BCG、Capgemini、Cognizant 等在内的 50 多家技术合作伙伴和服务提供商的支持。(@ 量子位)
3、字节最新人像视频生成模型 DreamActor-M1,推特关注超百万!即梦 AI 即将上线
自数字人技术 Omnihuman-1 引起行业关注之后,字节智能创作团队再放大招。
最近,这支团队一项基于 DiT 架构的可控人像视频生成技术 DreamActor-M1,一经发布,又在推特上引起了超百万量级的关注。仅需一张静态照片和一段驱动视频,便可生成高质量、达到电影级别的视频,将人像视频生成的表现力提升至全新水平。
DreamActor-M1 不仅能够保留原图中的身份特征,还能精准捕捉并迁移驱动视频中的动作和表情,呈现出高度逼真的效果,极大地简化了现有的动作捕捉、角色动画以及内容创作流程。
据悉,Omnihuman-1 技术已经应用于即梦数字人玩法的「大师模式」而 DreamActor-M1 模型也将于近期上线即梦 AI,用户将可以在「数字人」-「动作模仿」功能下体验新模型。相比已有的动作模仿效果,在生成内容逼真度、画风支持、画面比例支持等多个方面将大幅优化。(@ 新智元)
4、月之暗面开源轻量级 MoE 多模态模型,支持推理,效果超过 GPT-4o
月之暗面最新开源了 基于 MoE 架构的高效多模态模型 Kimi-VL ,它具有先进的多模态推理、长文本理解以及强大的 agent 能力,模型总参数为 16B,但是推理时激活参数不到 3B。
作为一个通用的 VLM,Kimi-VL 在多轮 agent 交互任务(例如 OSWorld)中表现出色,取得了与旗舰模型相当的最先进的结果。此外,它在各种具有挑战性的视觉语言任务中展现出卓越的能力,包括大学级别的图像和视频理解、光学字符识别(OCR)、数学推理、多图像理解等。在基准测试中,它超过了 GPT-4o-mini、Qwen2.5-VL-7B 和 Gemma-3-12B-IT 等高效的 VLM 模型,同时在几个专业领域超越了 GPT-4o。
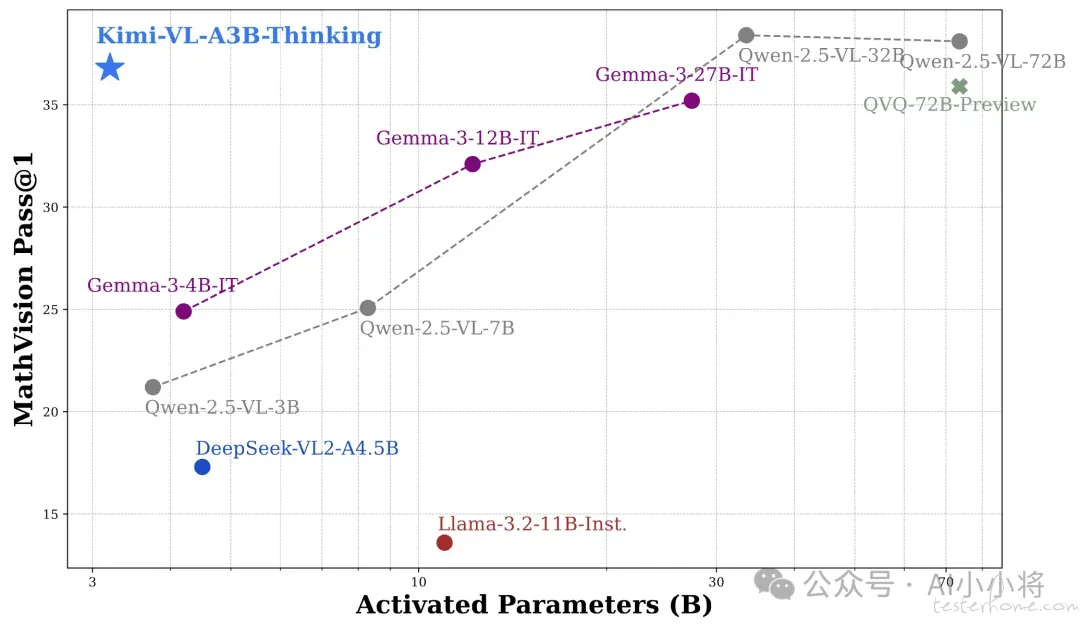
Kimi-VL 还在处理长文本和清晰感知方面推进了多模态模型的帕累托前沿:配备了 128K 扩展上下文窗口,Kimi-VL 能够处理长且多样化的输入,在 LongVideoBench 上得分 64.5,在 MMLongBench-Doc 上得分 35.1;其原生分辨率的视觉编码器 MoonViT,进一步使其能够看到并理解超高分辨率的视觉输入,在 InfoVQA 上取得了 83.2 的分数,在 ScreenSpot-Pro 上取得了 34.5 的分数,同时在处理常见视觉输入和一般任务时保持较低的计算成本。
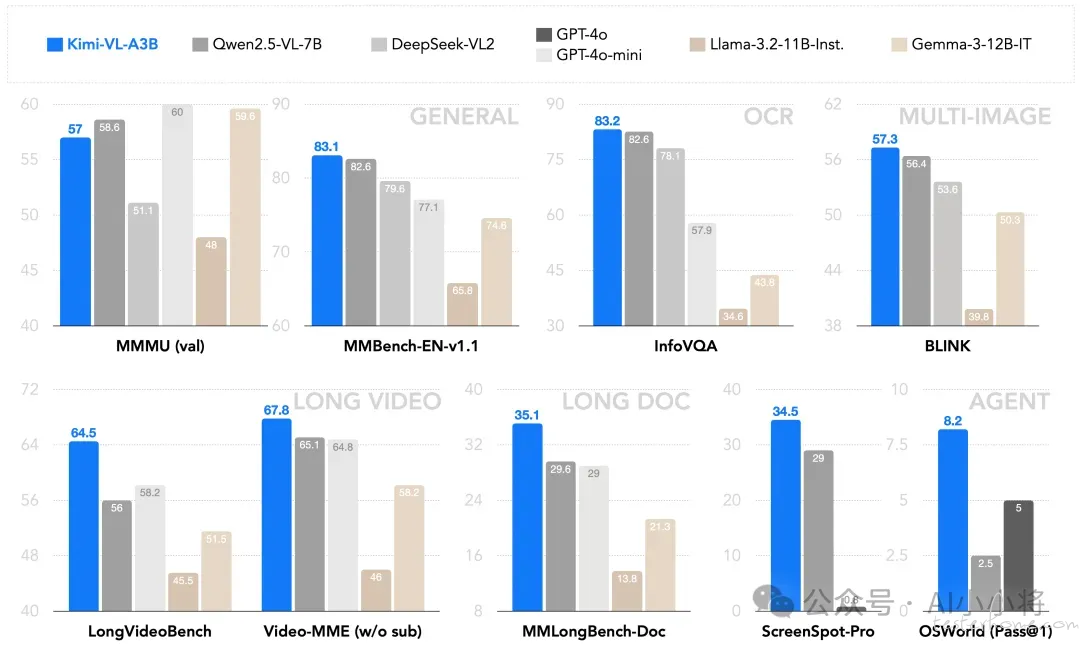
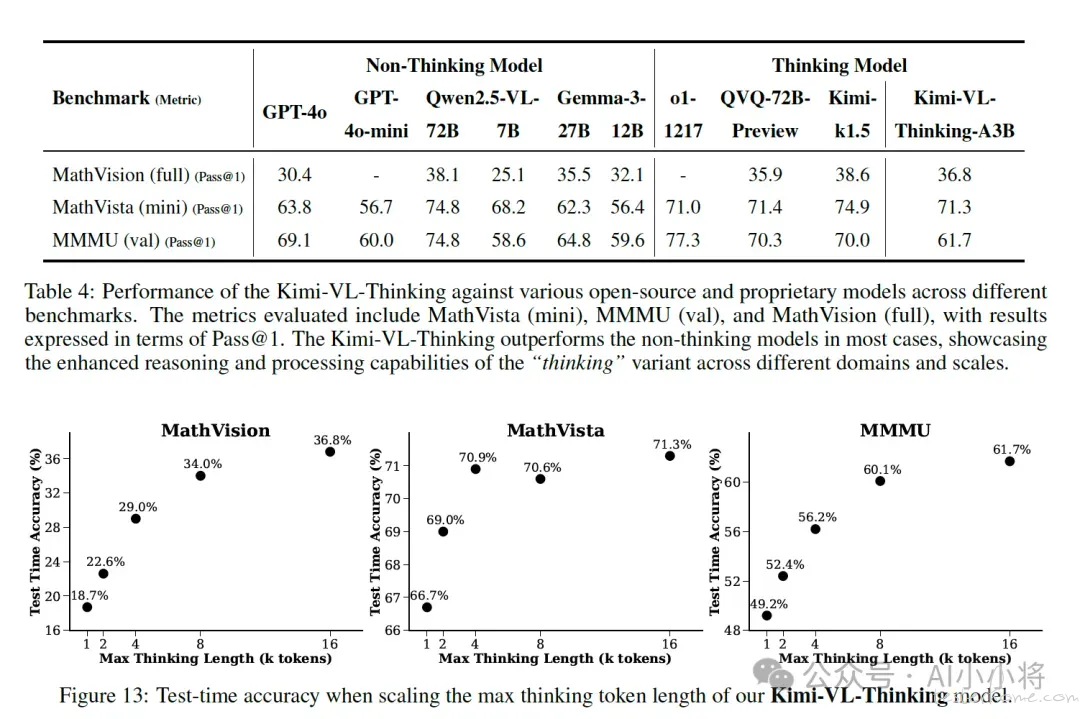
在 Kimi-VL 基础上,月之暗面还推出了支持推理的多模态模型:Kimi-VL-Thinking。通过长链推理(CoT)监督微调(SFT)和强化学习(RL),该模型展现出强大的长期推理能力。它在 MMMU 上取得了 61.7 的分数,在 MathVision 上取得了 36.8 的分数,在 MathVista 上取得了 71.3 的分数。
(@AI 小小将)
02 有亮点的产品
1、阿里 AI 智能眼镜将在年底发布

近日,根据维深信息 Wellsenn XR 独家信息,阿里已经确定了 AI 智能眼镜项目方案,目前正在积极招聘和扩充团队。据了解,阿里 AI 智能眼镜主要由智能信息事业群旗下的天猫精灵团队负责,硬件规格将超越目前火爆的 Ray-Ban Meta 智能眼镜:
采用高通 AR1 芯片 + 恒玄 BES2800 双芯片双系统架构,在功耗和续航方面将有更优秀的表现。
眼镜摄像头与 Ray-Ban Meta 一样采用索尼 IMX681 CMOS,1200 万像素,摄像头模组由立景提供,整机代工则由立讯承接。较为惊喜的是,阿里 AI 智能眼镜将分为两个版本,其中一款为带显示的 AI+AR 智能眼镜,并且该版本的优先级更高。报道称,AR 版本将采用表面浮雕光栅衍射光波导,采用了单绿色的 Micro LED 光机模组。AI 方面,上述 AI 智能眼镜将与 AI 旗舰应用「夸克」深度融合。夸克 AI 基于通义大模型技术,是将传统搜索升级为集 AI 对话、深度研究、任务执行于一体的「AI 超级框」。(@APPSO)
2、Google Deep Research 迎来重大更新
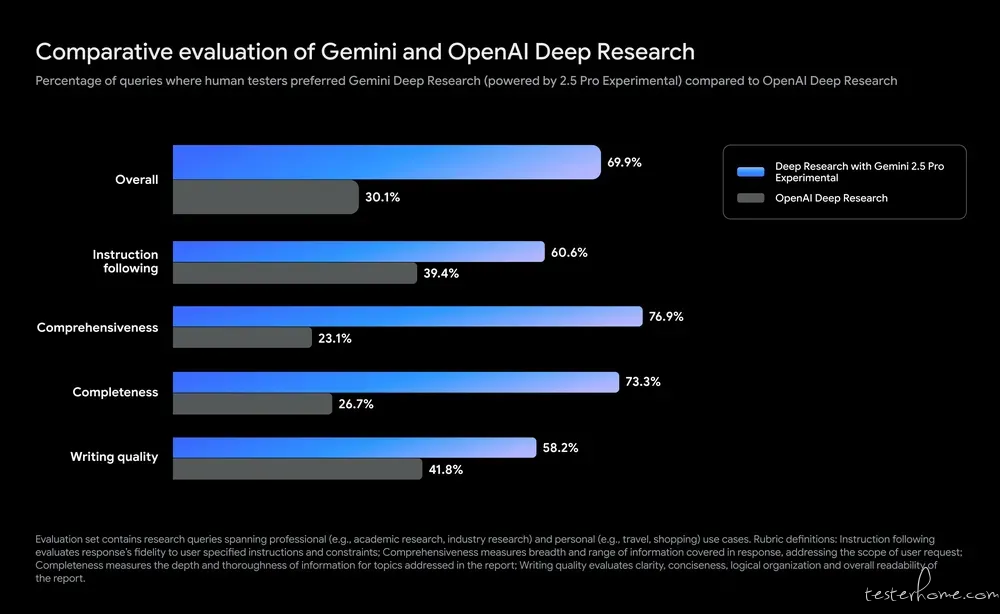
昨日,Google 正式为 Gemini Advanced 订阅用户更新基于 Gemini 2.5 Pro 的 Deep Research 功能,据介绍,该版本的 Deep Research 将拥有以下提升:
逻辑更加清晰,能提供更具深度的结论;
信息整合能力提升,从海量数据中快速提取重要内容,并且能化繁为简;
能生成更加详细的报告,并提供一定的独特角度见解。
Google 还放出了新版 Deep Research 与 OpenAI 的 Deep Research 对比。从结果显示,Google Deep Research 多项性能测试大幅领先 OpenAI 的 DR,整体性能提升超 40%。Google 也在报告中透露,Google Deep Research 生成的报告受到评估者的选择,程度远超其他 DR 工具 2 倍多。
而据多位 AI 专业人士测试,Google Deep Research 生成速度快,并且报告内容详细准确(还会在文末准确提供相关信源、文献),甚至还能将报告转换为语音播客。但也有专家指出,Google Deep Research 会存在一定的 token 数量限制,并指出 Google 应该让报告的生成实现无缝恢复,不然会导致严谨的研究内容受限。目前,新版 Google Deep Research 已上架 Gemini 的网页端、安卓或 iOS 的 App,Gemini Advanced 订阅用户独享。(但 Gemini Advanced 用户仅需 19.99 美元即可享受,相比 OpenAI 200 美元的 DR 便宜不少)(@APPSO)
03 有态度的观点
1、腾讯研究院院长:智能向善需要可信、可靠、普惠

近日,腾讯研究院院长司晓通过《中国网信杂志》发表了个人观点,以大模型为代表的生成式人工智能背景下,他提出了推动智能向善的三个「路标」:
需要可信的共识机制:司晓强调,可信是筑牢智能向善的基础,其表示,现在的各类生成式功能都有了不错的表现效果,但在大模型知识输出的精准度、专业度(即大模型的可信度),将成为人工智能应用赛道的核心竞争指标。司晓提出,大模型的「幻觉」不只是技术问题,更需要人类为其引入更多权威的内容数据,并打造新的、可信的共识机制和供应体系。
需要可靠的行业应用:司晓指出,大模型依靠着深度思考、科学推理和研究能力,并且越来越靠近人类的思考方式,随着推理能力的提升,大模型结合上述的各方面,可靠性也会得到提升。司晓预测,随着国产芯片、自主框架等技术日益成熟,今年我们将会迎来大模型应用增长年,大模型的安全性、可靠性将进一步提升。
需要普惠的成果共享:司晓最后提到,普惠是衡量智能向善的标尺。司晓表示,技术迭代过快导致普通大众会产生应用障碍,因此平台企业需要主动承担技术门槛降低的责任,让人工智能普惠于民;另一方面人工智能在工作场景中应该赋能各行各业劳动者,并且为劳动者创造新的就业机会,提升劳动者的自由度与工作舒适性。(@APPSO)

更多 Voice Agent 学习笔记:
a16z 合伙人:语音交互将成为 AI 应用公司最强大的突破口之一,巨头们在 B2C 市场已落后太多丨 Voice Agent 学习笔记
ElevenLabs 33 亿美元估值的秘密:技术驱动 + 用户导向的「小熊软糖」团队丨 Voice Agent 学习笔记
端侧 AI 时代,每台家居设备都可以是一个 AI Agent 丨 Voice Agent 学习笔记
世界最炙手可热的语音 AI 公司,举办了一场全球黑客松,冠军作品你可能已经看过
对话 TalktoApps 创始人:Voice AI 提高了我五倍的生产力,语音输入是人机交互的未来
2024,语音 AI 元年;2025,Voice Agent 即将爆发丨年度报告发布
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻