AI测试 月暗推出音频模型 AudioX:任意内容生成音频和配乐;开源 TTS 模型 Orpheus,可生成叹息、笑声等非文本线索丨日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@qqq、@ 鲍勃
01 有话题的技术
1、OpenAI 史上最贵 API 上线,o1-pro 比 DeepSeek-R1 溢价千倍
OpenAI 终于正式开放了万众期待的 o1-pro API,价格非常感人,比 o1-mini 贵 100 多倍。
大模型界的劳斯莱斯根据官方定价,o1-pro 输入价格 150 美金/每百万 token,输出价格 600 美金/每百万 token。目前,主要面向 T1-T5 特定开发者开放。相较于满血版 o1,pro 版本使用了更多的算力,能够提供高质量的连续响应。
而且,o1-pro 还支持视觉、函数调用、结构化输出,同时兼容 Responses 和 Batch API。
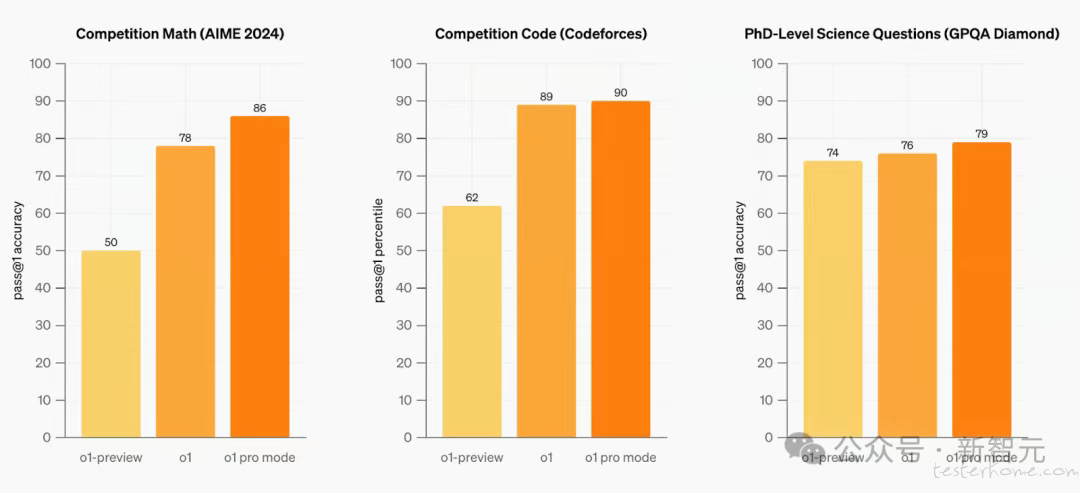
最新 API 官方文档介绍中强调,o1-pro 消耗更多 token 进行深入思考,推理最强,速度最快。
具体来说,o1-pro 拥有 200,000K 上下文长度,最大输出 token 为 100,000,模型知识更新截止到2023年10月1日。
以下是,o1-pro 和 o3-mini、GPT-4.5 模型功能对比。
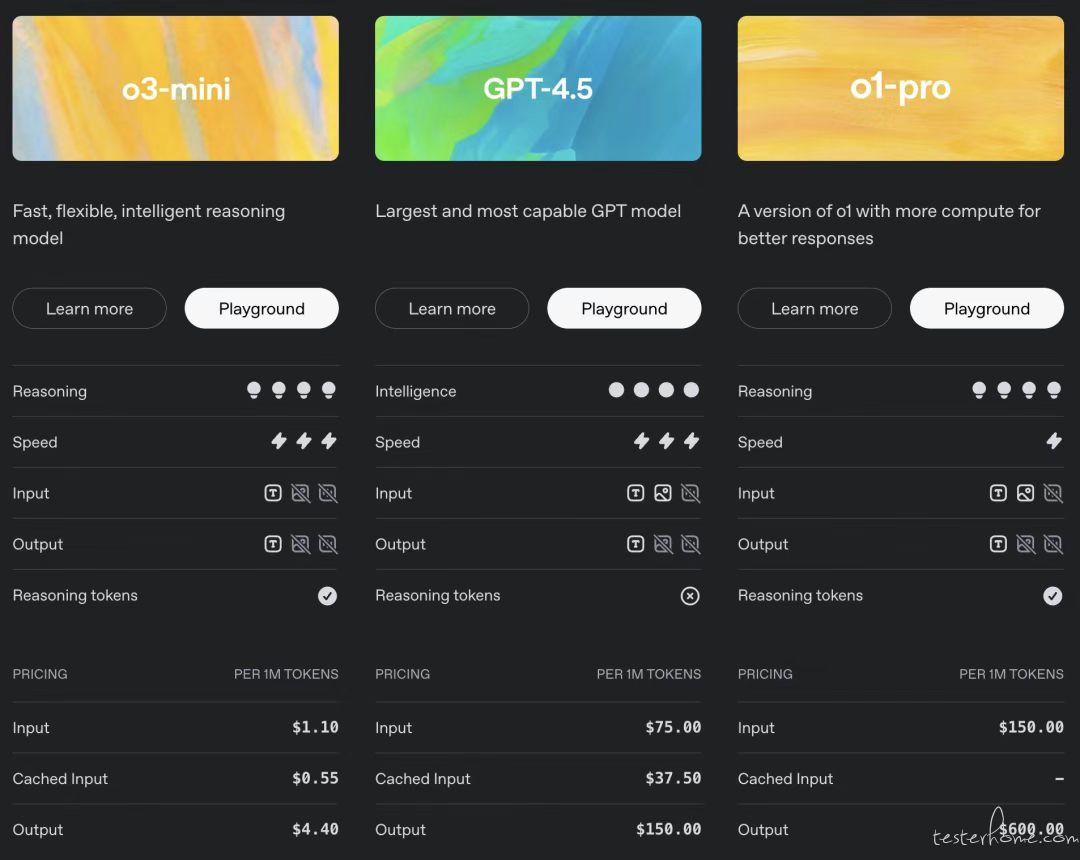
(@ 新智元)
2、stability.ai 发新模型,2D 图片一键转化 3D 视频
stability.ai 发布了 Stable Virtual Camera 模型,将 2D 图片转化成 3D 视频输出且可实现镜头控制。
核心要点
应用多视角扩散模型,不需要复杂的重构或者针对场景的优化,就可以实现 2D 图片到 3D 视频的转换,且能有现实深度与视角。
输入图片最多可以 32 张,生成的 3D 视频遵循用户定义的镜头轨迹,还有 14 个其他动态路径可选,包括 360°、八字形、螺旋、推拉变焦、旋转等等。
Stable Virtual Camera 在非商业许可下可用于研究用途。目前可以在 Hugging Face 上下载权重,在 GitHub 上访问代码。(@ 白鲸出海)
3、港中深开源语音理解模型:Soundwave,能基于语音内容智能对话
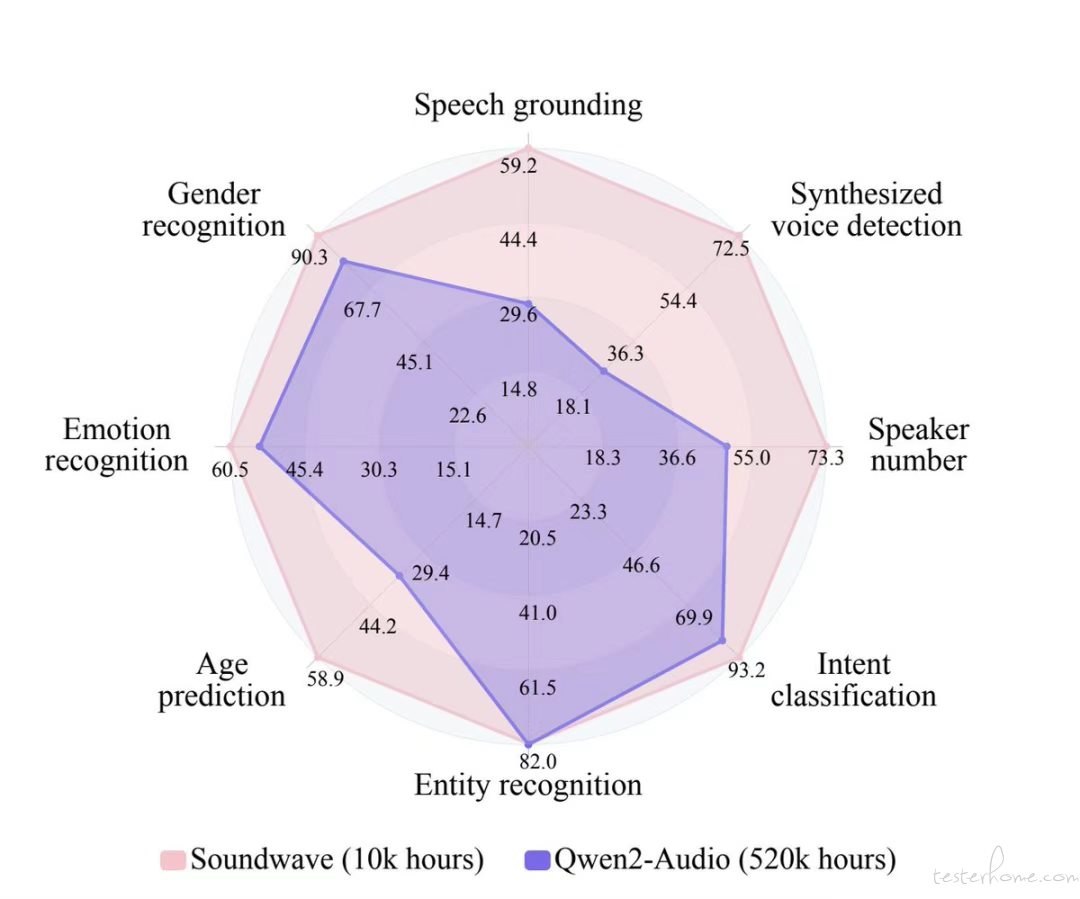
香港中文大学(深圳)开源了一款语音理解模型:Soundwave,核心优势在于它的语音文本智能对齐和理解能力。Soundwave 不仅能「听懂」话,把语音转换为文字,它更注重理解语音内容含义,支持更复杂的语音交互,比如语音翻译、语音问答等,并且具备智能对话能力,能基于语音内容进行智能对话,且保持对话的连贯性和智能性。其在接受了 1/50 的训练数据(1 万小时)后就达到了与 Qwen2-Audio 相当的性能。(@AIGCLINK@X)
4、Canopy Labs 开源 TTS 模型 Orpheus,可生成叹息、笑声和咯咯笑等非文本线索
Canopy Labs 推出开源文本转语音(TTS)模型 Orpheus,宣称其能力超越包括 ElevenLabs 和 OpenAI 在内的开源和闭源 TTS 模型。
语音与情感能力
Orpheus 生成高品质、悦耳的语音,接近人类情感智能。
通过叹息、笑声和咯咯笑等非文本线索,表达同理心和情感,远超以往开源 TTS 模型。
模型特性
初始版本参数规模为 3B ,未来将发布 1B、500M 和 150M 的较小模型。
即使在极小模型规模下,仍能实现极高品质的语音生成。
微调版本适合对话场景,预训练版本可用于语音克隆、分类等任务。
基于 Llama-3b 模型,具备零样本语音克隆、低延迟(实时应用约 200 毫秒,可优化至 100 毫秒)及通过标签引导情感和语调的功能。
Orpheus 是 Canopy Labs 开发与真人无异的 3D 数字人类计划的一部分。公司设想未来每个 AI 应用都配备一个可以互动的「人类」化身。(@Elias@X)
5、港科大联合月之暗面提出 AudioX,任意内容生成音频和音乐
香港科技大学联合月之暗面提出了 Audiox,这是一种用于任意输入到音频和音乐生成(Anything-to-Audio and MusicGeneration)的 Diffusion Transformer 模型。与以往的特定领域模型不同,AudioX 既能生成高质量的通用音频和音乐,同时提供灵活的自然语言控制,并能无缝处理文本、视频、图像、音乐和音频等多种模态输入。
AudioX 具备秒级生成电影级环境音、智能匹配视频节奏生成 BGM、史诗级音乐续写等创新能力。它支持文本、视频、图像到音频转换,可根据输入自动生成匹配的音效或音乐,并能修复缺失音频、补全未完成音乐。(@AI 妙妙房)
02 有亮点的产品
1、Skarbe :一款针对中小企业的 CRM-free 销售引擎,通过自动化跟进和分析提高销售效率
(图片来源:Product Hunt)
Skarbe 产品定位为中小企业的 CRM-free 销售引擎,主要面向那些不喜欢传统 CRM 系统的销售人员。其核心价值主张在于自动化跟进和分析,帮助用户节省时间。目标用户是那些希望简化销售流程、提高效率的销售团队。Skarbe 解决了传统 CRM 系统过于复杂和耗时的痛点,为用户提供了更直接的销售管理体验。
在功能方面,Skarbe 的亮点包括自动化的交易跟踪、电子邮件跟进、通话录音和会议洞察。产品的差异化优势在于其简洁易用、不依赖传统 CRM 的设计,提供了更为直观的用户体验。用户可以通过 Skarbe 快速管理销售流程,减少每日工作时间。(@Z Potentials)
2、Fluently :一款 AI 驱动的英语辅导平台,提供 24/7 的英语口语练习

(图片来源:Product Hunt)
Fluently 产品定位为非母语者的 AI 英语辅导工具,主要面向希望在工作场合提高英语口语能力的专业人士。其核心价值主张在于提供经济实惠且高效的英语练习机会,帮助用户改善语法、词汇和发音。目标用户是那些需要在工作中自信使用英语的非母语者。Fluently 解决了传统英语辅导昂贵且不便捷的问题,为用户提供了更为灵活和经济的英语学习解决方案。
在功能方面,Fluently 的亮点包括 AI 驱动的语音纠正、词汇和语法改进,以及发音练习。产品的差异化优势在于其 24/7 可用性和经济实惠性,提供了比传统英语辅导更为便捷和亲切的学习体验。用户可以通过 Fluently 快速提高英语水平,增强在工作场合的自信心。(@Z Potentials)
3、Wispr Flow for Windows :一款基于 AI 的语音转文本工具

(图片来源:Product Hunt)
Wispr Flow for Windows 是一款基于 AI 的语音转文本工具,允许用户通过自然语音输入来写作,速度可达传统打字的三倍,并且无需额外编辑或纠正打字错误。
Wispr Flow for Windows 产品定位为提高生产力的语音转文本工具,主要面向希望提高写作效率的用户。其核心价值主张在于通过自然语音输入来实现更快的写作速度,减少打字错误。目标用户是那些需要快速完成文档或邮件的专业人士和学生。Wispr Flow 解决了传统打字速度慢、容易出现打字错误的问题,为用户提供了更为高效和准确的写作体验。
在功能方面,Wispr Flow 的亮点包括语音转文本功能、无需额外编辑以及跨应用支持。产品的差异化优势在于其速度快且准确,提供了比传统打字更为便捷和高效的写作方式。用户可以通过 Wispr Flow 快速完成写作任务,节省大量时间。(@Z Potentials)
03 有态度的观点
1、腾讯汤道生:要把前沿的技术,变成「好用的 AI」产品

3 月 19 日,2025 腾讯全球数字生态大会上海峰会召开,腾讯集团高级执行副总裁、云与智慧产业事业群 CEO 汤道生在大会上阐述了自己对 AI 未来的理解。汤道生表示,随着 Deepseek 的开源与深度思考的突破,AI 大模型正跨过产业化落地的门槛,站上普及应用的全新节点。而公司也要立足用前沿的技术,打造「好用的 AI」,为用户提供有实效、有温度、可进化的智能产品和解决方案,助力大家的美好生活,推动实体产业创新突破。「大模型技术是智能 AI 应用的基础。」汤道生表示。并且他引入腾讯对模型的发展理念,认为一方面要坚定不移的推进大模型的全链路自研,而另一方面,也积极拥抱先进的开源模型,让用户针对不同场景自由选择,满足各自对场景与性价比的要求。此外,汤道生还指出模型是 AI 应用的核心,但好的模型还需要搭配实用的场景、权威的内容来源、稳定的算力服务,才能在用户需要的时候,提供可靠的 AI 服务。(@APPSO)

更多 Voice Agent 学习笔记:
ElevenLabs 33 亿美元估值的秘密:技术驱动 + 用户导向的「小熊软糖」团队丨 Voice Agent 学习笔记
端侧 AI 时代,每台家居设备都可以是一个 AI Agent 丨 Voice Agent 学习笔记
世界最炙手可热的语音 AI 公司,举办了一场全球黑客松,冠军作品你可能已经看过
对话 TalktoApps 创始人:Voice AI 提高了我五倍的生产力,语音输入是人机交互的未来
2024,语音 AI 元年;2025,Voice Agent 即将爆发丨年度报告发布
对话谷歌 Project Astra 研究主管:打造通用 AI 助理,主动视频交互和全双工对话是未来重点
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻