本文整理自声网 SDK 新业务探索组技术负责人,IoT 行业专家 @ 吴方方 1 月 18 日在 RTE 开发者社区「Voice Agent + 硬件分享会」上的分享。本次主要介绍了 AI 对话式智能硬件的发展历程,新一波 AI 浪潮所带来的创新机遇、技术挑战以及未来的展望。
在语音交互浪潮的推动下,AIoT 行业正在经历一场前所未有的变革。今天,我们来聊聊这一领域的发展。
从「听到」到「听懂」,AI 对话式智能硬件的发展历程
2017 年,第一波 AI 浪潮带来了技术突破,解决了语音转文字、文字转语音以及简单的自然语义理解问题。这三项技术结合在一起,催生出了 AIoT 的概念。
到了 2020 年,AIoT 进入快速发展期。此时,人与机器通过自然语言进行交流交互已成为现实。在这一阶段,ASR 的识别准确率超过了 93%,TTS 在自然性和感情表达方面也取得了显著进步。例如在听有声小说时,有时几乎无法分辨声音是由计算机合成的还是人类朗读的。这些技术成果,成为上一个 AI 浪潮留下的重要资产。
如今,大模型的出现正在各行各业引发深远影响,AIoT 行业也因此迎来了全新的发展机遇,以下是几个关键变化:
自然语言理解: AI 助手的理解能力迈上了新的台阶。过去,AI 助手只能 “听懂” 用户的指令并完成一些简单的任务。 但现在,它们不仅能理解具体的任务,还能领会指令背后的真实意图。 这种能力让 AI 助手不再局限于被动执行,展现出更强的智能和灵活性。
生成式对话: 早期的 AI 对话模型依赖大量标注数据进行训练,对语义的理解生硬且机械,像 “查字典” 一样。而大模型的出现带来了根本性改变, 现在的 AI 模型能够真正理解对话的含义,并基于语义自主生成内容。这一转变显著提升了 AI 发展的速度,技术的进步曲线变得更加陡峭。 随着数据和语料库的扩充,AI 的自主性将持续增强,呈现指数级增长。
多模态: 通过整合文本、语音、图像等多种形式的数据, AI 能够从多个维度感知环境, 从而对世界有更全面、更深入的理解。未来,更多传感器数据的加入将进一步增强 AI 的感知能力,为其在更多领域的应用提供更坚实的技术支持。
自学习能力: 当前,Agent 已具备接受用户 纠正和反馈的能力。 通过不断学习和调整,Agent 能够适应不同用户的个性化需求,提供更加精准、贴心的服务。这种自学习能力为 AI 的持续优化和用户体验提升奠定了基础。
大模型带来的这些技术突破,将推动 AIoT 行业进入一个全新的发展阶段,为更多创新和应用开辟广阔空间。
 "1313d4db2474b1.png")
在这些变革的推动下,AIoT 领域的产品形态正在发生显著变化,以下几个例子可以清晰展现这一趋势:
会议助手
早期的会议助手功能单一,主要充当会议记录员的角色。在会议中,它通过麦克风收集语音信息,并利用 ASR 技术将语音转化为文字以供后续查阅。如今,AI Agent 的出现让会议助手功能大幅升级。它不仅能记录内容,还能对会议讨论进行总结,提炼出核心话题和最终决策事项,并梳理出下一步行动计划。这种能力显著提升了会议的效率和质量。
AI 实时转译耳机
AI 实时转译耳机为翻译领域带来了全新变革。在跨语言交流场景中,用户只需佩戴耳机,AI 即可实时提供同声传译,帮助不同语言背景的人实现无障碍沟通。这项创新突破了语言障碍,为全球交流与合作提供了更加高效便捷的工具。
机器人助手
机器人助手在功能上超越了早期的智能音箱。智能音箱通常只能执行简单的语音播放任务,而机器人助手凭借多模态能力,可以主动与用户互动。它不仅能识别语音指令,还能捕捉用户的表情、动作等非语言信息,并据此提供综合回应。机器人助手能完成从设置闹钟到预订机票等多样化任务,在日常生活中扮演越来越重要的角色。未来,它将不断进化,成为人们贴心的个人助理,全方位满足生活和工作的需求。
实时交流、海量传输,AIoT 还将面临哪些挑战
任何变革都伴随着挑战。大模型在 AIoT 新时代的应用推动了技术变革,同时也带来了新的技术难题,主要表现在以下几个方面:
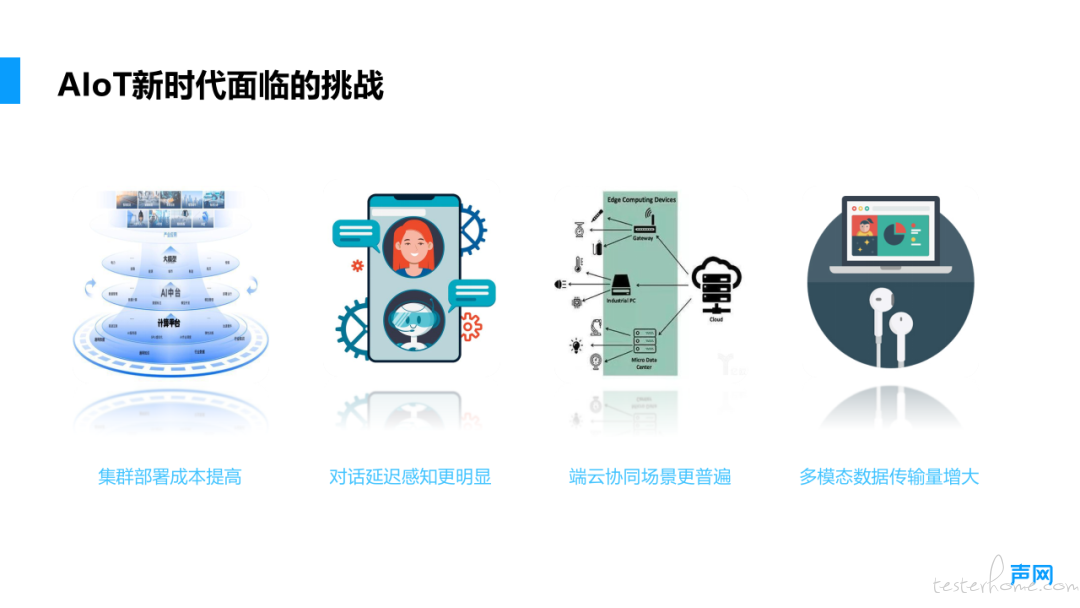
部署成本提高
以前,小型企业在提供 AI 服务时,主要专注于数据标注和模型训练,成本相对较低。然而,大模型的训练需要巨额资金投入,同时为了实现低延迟和多模态功能,还需额外承担算力、存储和流量成本。
对延迟的苛刻要求
随着人们对人机交互体验的期望提升,对话的流畅性和即时性成为关键。过去,机器主要用于接受控制指令,而现在用户希望与 AI 进行更自然、更实时的交流,这对延迟提出了更高要求。
端云协同的普及
大量数据处理需要依赖云端的强大算力,这要求云端具备高效的计算能力,同时确保端与云之间的稳定连接和高效数据传输。
多模态数据的传输压力
多模态技术的发展使数据传输量激增,对网络带宽和稳定性提出了更高要求。只有具备高带宽和高稳定性的网络,才能支持多模态数据的快速、准确传输,保障 AI 系统的正常运行。
延迟低、传输快 RTC 助力 AIoT 新玩法
面对这些挑战,引入新的技术成为必然选择。而 RTC 的技术优势可以为 AIoT 场景带来更多创新可能。
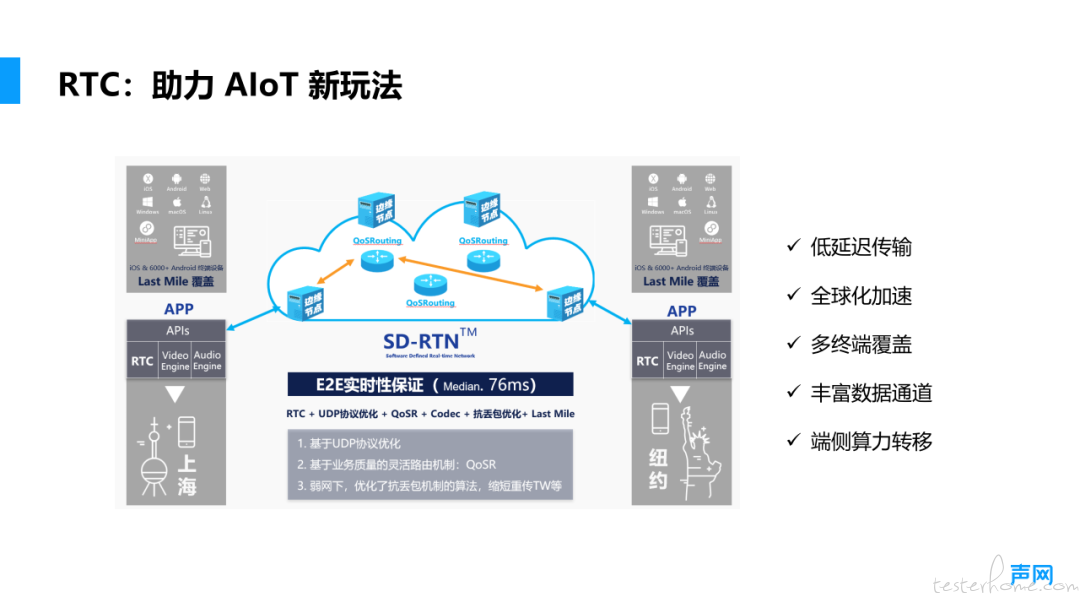
首先,RTC 技术具有 超低延迟 的特点,并且实现了 全球范围的广泛覆盖, 能够确保数据的快速传输。例如,从美国向中国传输数据时,延迟可以控制在几十毫秒以内。这种低延迟特性对需要实时响应的 AIoT 场景尤为重要。
其次,RTC 技术支持 多种类型的数据传输, 传输通道非常灵活。不仅适用于音频和视频数据,还能支持未来可能出现的结构化数据,如 3D Metadata 等。这种灵活性为 AIoT 场景下的多样化数据交互提供了可靠的技术保障。
此外,RTC 技术还能 有效转移端侧的计算压力。 例如,在音频 3A(回声消除、自动增益、噪声抑制)处理方面,传统端侧芯片的处理能力有限,难以实现理想效果。而 RTC 技术可以将这些任务转移到服务器端,利用服务器强大的算力对音频数据进行更精细、更高效的处理,从而显著提升音频质量,为用户提供更好的体验。
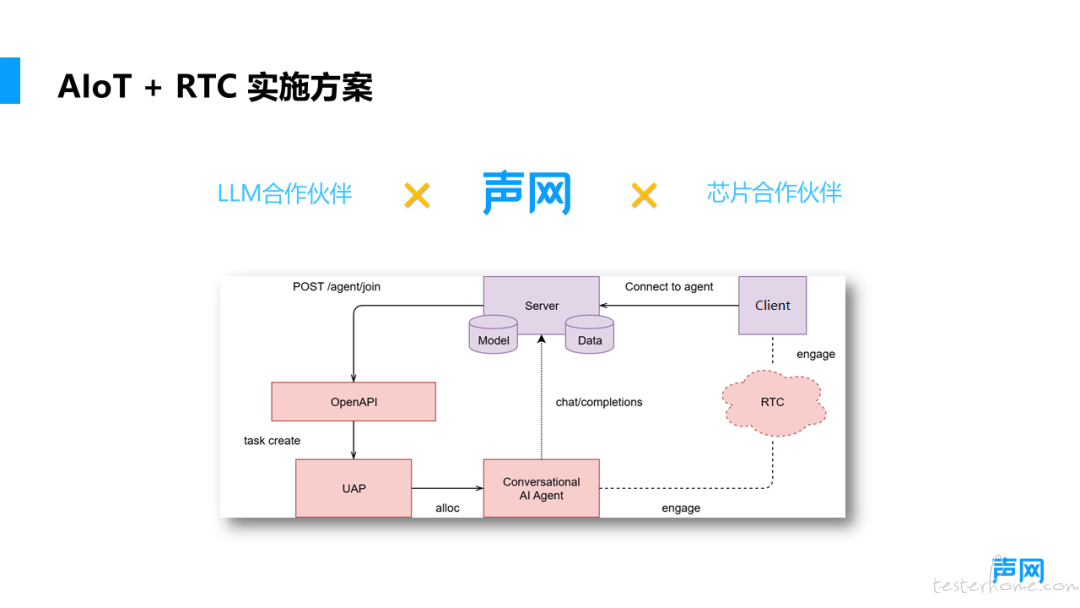
声网凭借在 RTC 领域多年的深厚技术沉淀,以及开放生态环境,推出了声网 AI Agent x IoT 智能硬件解决方案,该方案 能够在低功耗、低算力芯片上快速实现大模型的接入,具备低延时实时互动、低成本灵活适配的特性,通过丰富的功能在智能硬件场景中构建真实、自然的 AI 语音交互体验。
对于开发者而言,只需在端侧接入 RTC 技术,并将 Agent 能力部署于云端,Agent 的变动不会对端侧开发造成任何影响。在这套方案的服务架构中,设备端芯片会集成声网 RTC 端侧 SDK,该 SDK 能够将采集到的音视频数据高效传输至 Agent 服务器。服务器集成了 VAD、音频 3A 处理、TTS、ASR 等一系列核心功能。数据在服务器中经过上述功能模块的处理后,会与指定的大模型进行交互。大模型处理返回的结果,会进一步经过翻译转化为语音,最后通过优化后的传输通道回传至设备端。
这种设计大幅减轻了设备端的开发工作量。开发者 仅需专注于在 RTC 通道上进行音视频数据的传输, 其他所有的计算任务均由云端服务器来完成。声网始终致力于技术的持续优化与升级,不断提升人与设备之间基于 LLM 的互动体验。目前, 声网 AI Agent x IoT 智能硬件解决方案已经提供了包含大网实时传输,音频处理、语音识别、文本处理、视频处理等能力,可以支持智能管家、安防助手、虚拟陪伴、生活助理、实时翻译等应用场景。
尽管 IoT 经过多年发展,已经形成了较为成熟的产品体系,但 AI 的进步将为其带来更多创新场景和技术突破。
IoT 终端将在未来发挥更重要的作用。作为 AI 大模型的数据来源,IoT 终端将为 AI Agent 的进化提供支持,进一步加速其发展。
AI Agent 的发展方向将更加注重个性化。它能够深入洞察每位用户的需求和偏好,提供真正因人而异的差异化服务,满足更多元化的使用场景。
AI Agent 之间通过自然语言进行协同工作的可能性也越来越大。这将有助于打破 IoT 领域长期存在的数据不互通和协议不兼容问题,推动 IoT 生态朝着更加智能化和融合化的方向演进。
