AI测试 Hume 语音模型 OCTAVE:实现情感语音合成、声音克隆和多角色对话生成;通义开源多模态说话人识别项目 3D-Speaker

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。 我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
01 有话题的新闻
1、3D-Speaker:阿里通义开源的多模态说话人识别项目,支持说话人识别、语种识别、多模态识别、说话人重叠检测和日志记录
3D-Speaker 是阿里巴巴通义实验室语音团队推出的多模态开源项目,旨在通过结合声学、语义和视觉信息,实现高精度的说话人识别和语种识别。项目提供了工业级模型、训练和推理代码,以及大规模多设备、多距离、多方言的数据集,支持高挑战性的语音研究。
3D-Speaker 的最新更新增强了多说话人日志功能,提升了识别效率和准确性,适用于大规模对话数据的高效处理。
3D-Speaker 的主要功能
说话人日志: 将音频划分为属于不同说话人的多个段落,识别出每个说话人的开始和结束时间。
说话人识别: 确定音频中说话人的身份。
语种识别: 识别音频中说话人所使用的语言。
多模态识别: 结合声学、语义、视觉信息,增强识别能力,尤其是在复杂声学环境中。
重叠说话人检测: 能识别出音频中任意说话人重叠的区域。(@ 蚝油菜花)
2、百川智能发布金融大模型 Baichuan4-Finance
百川智能发布全链路领域增强大模型 Baichuan4-Finance。据介绍, 通过行业首创的领域自约束训练方案,Baichuan4-Finance 实现了金融能力和通用能力同步提升的效果,极大提高了金融场景的整体可用性。
据媒体报道,内部人士透露,其金融专业能力和场景应用能力大幅领先 GPT-4o,在中国人民大学财政金融学院新近发布的评测体系 FLAME 以及国内主流开源金融评测基准 FinancelQ 上均登上榜首。
根据评测数据显示,Baichuan4-Finance 的整体准确率高达 93.62%,在银行、保险、基金和证券等多个金融领域的准确率均突破了 95%,相较于 GPT-4o 高出近 20%。此外,在 FinanceIQ 等主流开源金融评测基准上,Baichuan4-Finance 的整体准确率也达到了 79.23%,领先 GPT-4o 近 13 个百分点。
值得一提的是,今年五月份,百川智能发布基座大模型 Baichuan4,相较 Baichuan3 在各项能力上均有极大提升,当时在国内权威大模型评测机构 SuperCLUE 的评测中,模型能力国内第一。(@AIbase 基地)
3、Adobe 推出新 AI 工具 可让声音设计师通过哼唱和模仿声音来创作音频
该系统会分析语音输入的三个关 键元素:响度、音色(决定声音的明亮程度)和音调。然后,系统会将这些特征与文本描述相结合,生成所需的声音。
Sketch2Sound 的有趣之处在于它能够理解上下文。例如,如果有人输入「森林氛围」并发出短促的声音,系统会自动识别出这些声音应该是鸟叫声 - 而无需特定指令。
同样的智能也适用于音乐。在创建鼓点模式时,用户可以输入「低音鼓、小军鼓」,然后使用低音和高音哼唱节奏。系统会自动将低音鼓放在低音上,将小军鼓放在高音上。
研究团队内置了特殊的过滤技术,让用户可以调整控制生成声音的精确度。声音设计师可以根据自己的需求选择精确、细致的控制或更轻松、近似的方法。
这种灵活性使得 Sketch2Sound 对于拟音师(为电影和电视节目制作音效的专业人士)来说特别有价值。他们无需操纵物理对象来发出声音,而是可以通过语音和文本描述更快地创建效果。
研究人员指出,输入录音的空间音频特性有时会以不想要的方式影响生成的声音,但他们正在努力解决这个问题。Adobe 尚未宣布 Sketch2Sound 何时或是否会成为商业产品。(@AIbase 基地)
4、Hume AI 发布全新语音模型 OCTAVE,实现即时语音克隆与个性化定制
核心技术亮点:
语音与个性同步生成: OCTAVE 不仅能根据文字描述生成声音,还能同时创建与之匹配的个性,包括语言风格、口音、表达方式、潜在性格等。用户可以通过描述性文本或录音指定声音的性别、年龄、情感语调、职业相关的说话风格等多种特征。例如,模型可以生成「像用热沥青漱口的沙哑男声」,或「温柔善解人意的治疗师的声音」。
即时语音克隆与个性提取: OCTAVE 仅需一段 5 秒的录音,即可提取说话者的清晰声音、口音和个性特征,并以此生成自然的对话。这使得用户可以快速复制和使用各种独特的声音。
实时互动与多角色对话: OCTAVE 支持实时互动,并且可以生成多个相互作用的 AI 角色,在对话中自由切换。这使得模拟复杂的对话场景成为可能。该模型对说话风格、表达方式和潜在性格的理解,使其在实时互动中产生的语言和声音更加自然真实。
3B 参数小模型: OCTAVE 在语言理解方面表现出色,其性能与同等规模的前沿大型语言模型(LLM)相当。所有示例均由 30 亿参数的 OCTAVE 3B 模型生成,展示了其最小模型的强大实力。
Hume AI 表示,目前 OCTAVE 仍处于改进阶段,已向部分合作伙伴提供有限版本,以评估其在各种应用环境中的安全性和有效性。预计未来几个月内将向更多用户开放。(@Hume Blog)
02 有亮点的产品
1、GenFuse AI:自动化各种业务流程的无代码平台
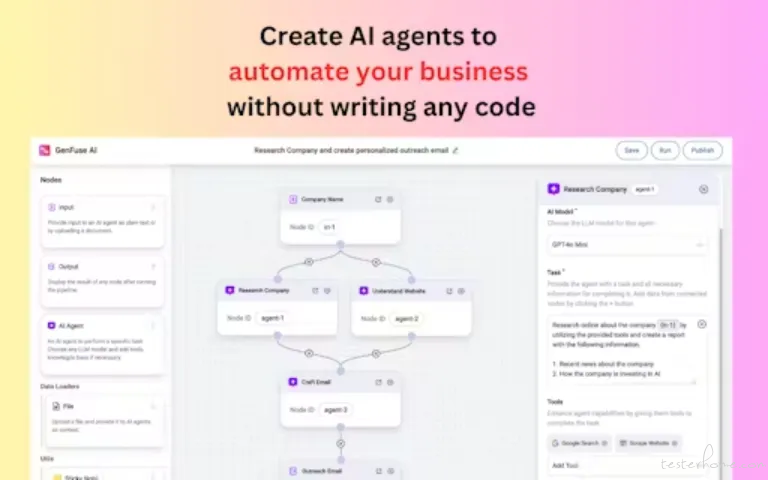
GenFuse AI 是一款创新的无代码工具,专注于帮助用户创建和管理 AI 代理,以自动化重复性任务。其核心价值主张在于通过直观的拖拽式编辑器,使任何人都能轻松构建多代理工作流程,而无需具备技术背景。目标用户包括希望提高工作效率的企业和个人,尤其是那些缺乏编程知识但希望利用 AI 技术简化流程的用户。GenFuse AI 解决了传统自动化工具复杂、难以使用的问题,为用户提供了一个友好的解决方案。(@Z potentials)
2、解决 AI 语音代理评估和管理痛点,Hamming.ai 获 380 万美元种子轮融资
随着 AI 语音代理在电话沟通中日益普及,其可靠性问题日益凸显。Hamming.ai 获得 380 万美元种子轮融资,旨在解决这一行业痛点。传统的人工测试效率低下,且难以覆盖所有场景,导致 AI 语音系统成本高昂,并存在潜在风险。
Hamming.ai 通过自动化测试、监控和管理 AI 语音代理,高效解决上述问题。他们利用自主研发的 AI 语音代理进行大规模测试,并为企业提供 LLM 提示管理、自动化红队测试以及通话分析等服务。据称,其测试速度比人工快 20 倍,成本降低 10 倍。
该公司由 Sumanyu Sharma 和 Marius Buleandra 联合创立,两人均拥有在构建信任和安全基础设施方面的丰富经验。Sharma 曾任 Citizen 数据主管,并曾在特斯拉负责 AI 驱动的销售项目;Buleandra 则在 Anduril、Square 和微软等公司积累了丰富的数据基础设施和 AI 工程经验。(@AIbase 基地)
03 有态度的观点
1、图灵奖得主:AI 将成为超级智能,堪比新的文艺复兴
近日,2018 年图灵奖得主杨立昆(Yann LeCun)受邀,在联合国进行了最新演讲,并且表示 AI 将成为超级智能,堪比新的文艺复兴,人类新的启蒙。
杨立昆认为,基础模型必须是自由和开源的,训练也必须以协作和分布式的方式在全球多个数据中心进行,这样才能才能让全球都能参与,避免少数公司控制。并且杨立昆表示,从历史上看,开源平台比专有平台更安全。
杨立昆预测, 未来的 AI 将具备推理、计划、和理解现实世界的能力,最终会匹配甚至超越人类智力。他表示,上述可能将在未来一、二十年内发生。同时他还指出,人工智能不仅可能带来一场新的工业革命,还可能带来一场新的文艺复兴,人类的一个新的启蒙时期。
最后,杨立昆建议国际合作方向,应该收集文化材料并建立分布式 AI 超算中心,统一监管,避免阻碍开源 AI 发展。(@APPSO)
2、前谷歌 CEO 谈中美 AI 竞争:中国凭借市场与制造优势恐在长期中赶超美国,国内至少有两三家 GPT-4 劲敌
前谷歌 CEO Eric Schmidt 在不久前与华盛顿邮报专栏作者 Bina Venkataraman 的对话中透露了对中美科技竞争以及 AI 发展的最新观点。
Schmidt 表示,中国在 AI 领域具备一些独特的优势,能够通过更低成本的硬件(例如来自中国的机器人和 AI 芯片)进行大规模的应用,而这些硬件在功能上与美国的高端产品相当,甚至在一些情况下更具灵活性和适应性。
他还提到,尽管美国在 AI 技术的基础研究上可能处于领先地位,但中国可能会通过快速的市场采用和大规模生产,在长期内赶超美国。(@ 有新 Newin)

更多 Voice Agent 学习笔记:
Gemini 2.0 来了,这些 Voice Agent 开发者早已开始探索……
帮助用户与 AI 实时练习口语,Speak 为何能估值 10 亿美元?丨 Voice Agent 学习笔记
2024 语音模型前沿研究整理,Voice Agent 开发者必读
从开发者工具转型 AI 呼叫中心,这家 Voice Agent 公司已服务 100+ 客户
WebRTC 创建者刚加入了 OpenAI,他是如何思考语音 AI 的未来?
人类级别语音 AI 路线图丨 Voice Agent 学习笔记
语音 AI 革命:未来,消费者更可能倾向于与 AI 沟通,而非人工客服
语音 AI 迎来爆发期,也仍然隐藏着被低估的机会丨 RTE2024 音频技术和 Voice AI 专场
下一代 AI 陪伴 | 平等关系、长久记忆与情境共享 | 播客《编码人声》
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻