
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。 我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
01 有话题的新闻
1、李飞飞团队统一动作与语言,新的多模态模型不仅超懂指令,还能读懂隐含情绪
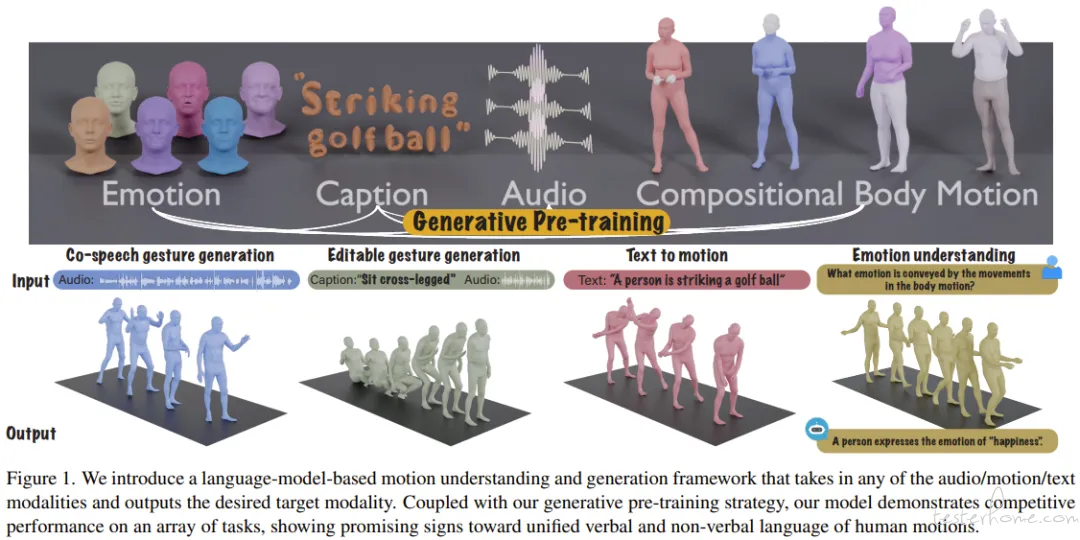
斯坦福大学李飞飞教授团队在人工智能领域取得了突破性进展,提出了一种能够统一理解和生成人类动作与语言的全新多模态语言模型。这项创新成果不仅技术上极具开创性,也为未来人机交互和动作识别技术的发展带来了新的可能性。
该团队认为,要实现对人类动作言语和非言语信息的统一理解,语言模型至关重要。他们巧妙地将动作转化为 token,并结合现有的文本和语音 token 化策略,使得任何模态的输入都能以 token 形式表示。 这个创新方法分为预训练和后训练两个阶段:预训练阶段通过身体组合动作对齐和音频 - 文本对齐来实现不同模态的对齐;后训练阶段则通过指令训练,使模型能够遵循各种任务指令。
实验结果显示,这种新方法的多模态语言模型在多个指标上都超越了当前最先进的模型,尤其在数据匮乏的情况下,预训练策略的优势更加显著。 值得一提的是,尽管在预训练阶段没有接触过语音 - 动作数据,该模型在数据相对较少的全新说话人上依然展现出极强的泛化能力和竞争力。
这项成果标志着人工智能在理解和生成人类动作方面迈出了关键一步。该模型不仅可以根据语音内容和文本指令生成全身动作,还能精细地控制不同身体部位的动作,并将其自然地组合。
这项技术在游戏、虚拟现实等领域拥有巨大的应用潜力,并将对未来人机交互技术的发展起到关键作用。 随着这一多模态模型的不断发展和应用,我们有望迎来更加自然流畅、智能化的人机交互体验。(@ 百朋 AI 学堂)
2、Genesis Project 震撼发布:颠覆性生成式物理引擎,构建 4D 动态真实世界
近日,备受瞩目的 Genesis Project 正式发布,这款全新的生成式物理引擎旨在以最高的真实感模拟整个物理世界,为虚拟领域带来前所未有的沉浸式体验。
Genesis Project 最大的亮点在于其卓越的性能。该引擎采用纯 Python 开发,模拟速度比现有 GPU 加速引擎(如 Isaac Gym、MJX)快 10-80 倍,甚至比实时快约 43 万倍。这意味着开发者可以更快速地进行物理模拟,大大缩短开发周期。
此外,Genesis Project 还展现了强大的训练能力。在单张 RTX4090 显卡上,该引擎仅需 26 秒即可完成可转移到真实世界的机器人运动策略训练,这无疑将极大提升机器人和物理 AI 领域的开发效率。
Genesis Project 是由 20 多个研究实验室经过 24 个月的大规模合作研发而成,这充分体现了其强大的技术实力和学术背景。该项目旨在构建一个统一的生成式物理世界模拟框架,该框架可以自动生成各种环境、机器人任务、奖励函数和交互式 3D 场景,从而推动机器人和物理 AI 领域的全面发展。
Genesis Project 支持模拟各种类型的物理现象,包括刚体、关节体、布料、液体、烟雾、可变形体、薄壳材料、弹性/塑性体以及机器人肌肉等。它还集成了各种先进的物理解算器(如 MPM、SPH、FEM、刚体、PBD 等),确保模拟结果的准确性和真实性。
此外,Genesis Project 还提供 3D 交互式场景生成功能,支持训练机器人技能,并可应用于超越机器人领域的数据生成,例如角色运动。(@AIbase 基地)
3、苹果与腾讯、字节洽谈 AI 合作 计划在中国市场整合本地 AI 模型
据路透社援引三位知情人士的消息,苹果公司正在与腾讯和字节跳动展开谈判,探讨将这两家中国公司的人工智能(AI)模型整合至中国市场销售的 iPhone 中。这一举措是苹果 AI 系统 Apple Intelligence 的一部分,而从本月开始,苹果已在全球市场的 iPhone 中整合了 ChatGPT 聊天机器人功能。
知情人士透露,苹果与腾讯和字节跳动的讨论主要涉及利用后两者的 AI 模型。这一谈判目前尚处于早期阶段,细节仍未敲定。
值得注意的是,此前有媒体曾报道,苹果曾与百度洽谈合作,希望整合百度的 AI 模型至 iPhone,但由于技术问题导致谈判受阻。双方在是否允许使用 iPhone 用户数据来训练 AI 模型上存在分歧,成为合作的主要障碍。(@AIbase 基地)
02 有亮点的产品
1、OpenAI 重磅推出电话服务

北京时间今天凌晨,在 OpenAI 第十场发布会上 ,重磅推出电话服务。
据官方介绍,即日起,美国用户可将 ChatGPT 添加到电话通讯录,然后用智能手机/座机/老人机拨打 1-800-242-8478,它就能回应你提出的问题,比如景点导览亦或者语言翻译等。并且 OpenAI 将向美国用户提供 15 分钟的免费通话时间。
直播中,OpenAI 首席产品官 Kevin Weil 表示:「我们的使命是让通用人工智能造福全人类,部分目标就是尽可能让它向更多人开放。今天,我们迈出了下一步,把 ChatGPT 带到你的电话中。」
与此同时,ChatGPT 也正式「入驻」WhatsApp。届时,GPT-4o mini 将为 WhatsApp 用户提供基础对话服务。虽然无需注册即可使用,但受限于使用额度,建议你还是转向 App 或网页版获取完整体验。
OpenAI 表示,正在为 WhatsApp 开发图像分析和网页搜索等更多功能,但暂未公布这些功能的上线时间。(@ APPSO)
2、AI 初创公司 Odyssey 推新工具 Explorer 将文字和图像转化为逼真 3D 世界

AI 初创公司 Odyssey 正在开发一款名为 Explorer 的工具,该工具利用人工智能技术,可以将文本或图像转化为 3D 渲染图。
该工具的工作原理类似于 DeepMind、World Labs 和以色列初创公司 Decart 最近展示的世界模型,用户只需输入如「日本花园,绿意盎然」的描述,Explorer 就能生成一个互动的实时场景。
Odyssey 表示,Explorer 工具特别适合创建逼真的场景,这是因为其背后的 AI 系统是基于公司自定义设计的 360 度背包相机系统所捕捉的真实世界风景进行训练的。用户可以将 Explorer 生成的任何场景导入到如 Unreal Engine、Blender 和 Adobe After Effects 等创意工具中进行后期编辑。Explorer 采用的是高斯斑点技术,这是一种成熟的体积渲染技术,能够重建出真实的场景,而这种技术在计算机图形工具中得到了广泛支持。
虽然 Explorer 仍处于早期阶段,但 Odyssey 对其所能达到的 3D 细节和真实感表示兴奋,认为其在现场电影、超逼真游戏和新型娱乐形式中的应用潜力巨大。不过,该公司也承认,目前 Explorer 存在一些限制,例如生成场景平均需要 10 分钟,且生成的场景分辨率较低,偶尔会出现视觉伪影等问题。
Odyssey 已将 Explorer 提供给了包括英国 Garden Studios 在内的多家制作公司和一群独立艺术家,感兴趣的用户可以在 Odyssey 的博客上申请测试。Odyssey 表示其致力于与创意专业人士合作,而不是取代他们。为此,该公司宣布皮克斯联合创始人及前华特迪士尼动画工作室总裁艾德・卡特穆尔已加入其董事会并进行了投资。
Odyssey 的创始人之一奥利弗・卡梅伦曾任 Cruise 的产品副总裁,而杰夫・霍克则是 Wayve 的创始研究员。迄今为止,Odyssey 已从包括 EQT Ventures、GV 和 Air Street Capital 在内的投资者那里筹集了 2700 万美元。(@AIbase 基地)
3、免费版 GitHub Copilot 上线,VS Code 每月补全 2000 次代码
微软旗下代码托管平台 GitHub 今天(12 月 19 日)发布博文,宣布 GitHub Copilot Free 免费订阅,开发者可以在 Visual Studio Code 代码编辑器中,免费使用 GitHub Copilot AI 服务。
开发者通过 GitHub Copilot Free 免费订阅,可以选择 Anthropic 的 Claude 3.5 Sonnet 或 OpenAI 的 GPT-4o 模型,每月可以调用 2000 次生成和补全代码,以及 50 次聊天信息,要求其回答编程问题、解释现有代码、排查代码 BUG、跨文件执行编辑等,此外还支持 Copilot 的第三方智能体。(@IT 之家)
4、前 Snap AI 科学家再创业,打造实时视频聊天机器人平台
曾被 Snap 收购以构建 My AI 聊天机器人的深度学习科学家,现筹集种子资金推出新创公司 eSelf。
该公司专注于开发和运营实时视频对话 AI 代理,其响应时间低于 1.7 秒,比 OpenAI 等公司的语音响应更快。
eSelf 已从隐身模式中走出,获得 450 万美元融资,将主要服务于教育、销售、金融服务等行业。目前客户包括 Christie’s 房地产和巴西银行 AGI。(@AI 知识共创)
5、ElevenLabs 推出 Flash ——一款用于对话式 AI 的超快速文本转语音模型
ElevenLabs 最新推出的文本转语音 (TTS) 模型 Flash,旨在为对话式应用带来前所未有的速度提升。Flash 生成语音仅需 75 毫秒(不包括应用和网络延迟),相比现有解决方案,可提供响应更迅速、更自然的听觉体验。
ElevenLabs 将 Flash 定位为构建低延迟对话语音代理的开发人员的理想之选。其速度优势使其尤其适用于实时交互场景,在这些场景中,最小化延迟是打造真正沉浸式用户体验的关键。
Flash 现已通过 ElevenLabs 的对话式 AI 平台以及其 API 直接开放使用,模型 ID 分别为 eleven_flash_v2(仅支持英语)和 eleven_flash_v2_5(支持 32 种语言)。两种版本的计费方式均为每 2 个字符消耗 1 个积分。
ElevenLabs 承认 Flash 在音质和情感深度方面与他们的 Turbo 模型相比略有逊色,但强调 Flash 的整体质量仍优于竞品模型。他们认为,对于许多对话场景而言,更低的延迟是值得的取舍。(@ ElevenLabs)
03 有态度的观点
1、李飞飞:世界是三维的,我们需要尊重这一事实
近日,李飞飞在 2024 NeurIPS 上发表了她的个人演讲,其主题为「攀登视觉智能的阶梯」。
李飞飞在演讲中阐述了对未来机器视觉的愿景。其中她提到,空间智能是视觉智能的发展方向。李飞飞认为,世界是三维的,一旦尊重了世界的三维性,很多事情就自然而然地发生了。李飞飞同时举出「篮球被投入一个场景中,只有三维能做到,2D 平面中篮球则无处可去」的例子来证明了三维空间事情发生的逻辑性。
最后,当被提问到「人工智能理解了三维世界所带来的好处」时,李飞飞回答出了具体使用场景。她觉得可以结合 AR 技术,在三维空间构建出用户所需要获取的内容,如通过视觉三维去解释周遭一切的实体信息。(@ APPSO)

更多 Voice Agent 学习笔记:
Gemini 2.0 来了,这些 Voice Agent 开发者早已开始探索……
帮助用户与 AI 实时练习口语,Speak 为何能估值 10 亿美元?丨 Voice Agent 学习笔记
2024 语音模型前沿研究整理,Voice Agent 开发者必读
从开发者工具转型 AI 呼叫中心,这家 Voice Agent 公司已服务 100+ 客户
WebRTC 创建者刚加入了 OpenAI,他是如何思考语音 AI 的未来?
人类级别语音 AI 路线图丨 Voice Agent 学习笔记
语音 AI 革命:未来,消费者更可能倾向于与 AI 沟通,而非人工客服
语音 AI 迎来爆发期,也仍然隐藏着被低估的机会丨 RTE2024 音频技术和 Voice AI 专场
下一代 AI 陪伴 | 平等关系、长久记忆与情境共享 | 播客《编码人声》
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻