AI测试 字节豆包发布新模型,AI 一句话 P 图;Google 正式推出 Vids,简单提示即可生成视频演示丨 RTE 开发者日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的会议」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
01 有话题的新闻
1、字节新模型 SeedEdit 开启测试:一句话轻松 P 图
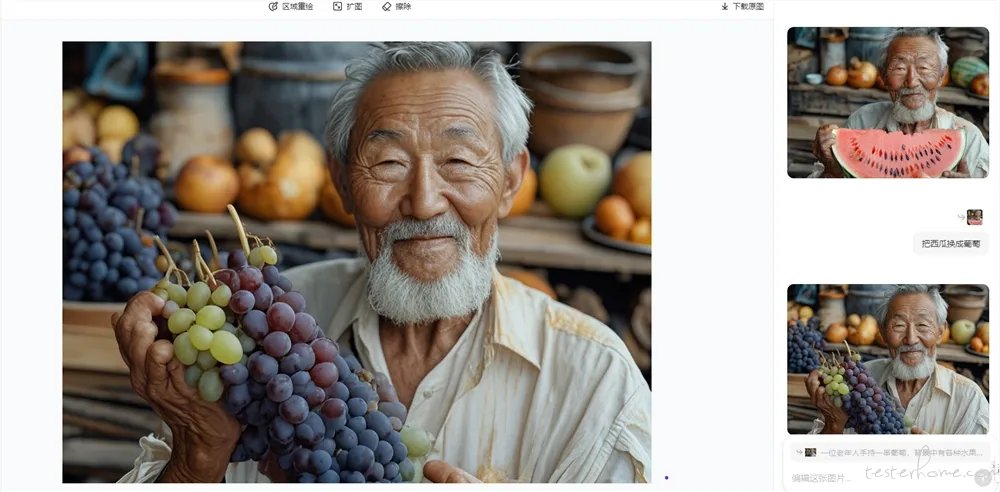
字节跳动于 11 月 11 日推出了其最新图像编辑模型 SeedEdit,成为国内首个产品化的通用图像编辑工具。用户只需输入一句简单的自然语言指令,即可实现对图片的背景更换、风格转换以及元素的增删替换,无需繁琐的描边和涂抹。
SeedEdit 在识别指令方面表现出色,能够精准理解中文和英文提示,包括成语及专有名词。例如,用户只需输入「把西瓜换成葡萄」,SeedEdit 便能快速完成上个与水果替换。
此外,模型在处理细节时也保持了原图的完整性,例如移除玻璃裂纹或改变图像中的特定元素。
作为一款通用图像编辑模型,SeedEdit 不仅支持单次编辑,还允许多轮创意操作。用户可以对同一图像进行连续编辑,创造出多样化的效果。
报告显示,SeedEdit 依然采用了 Diffusion 架构,但在不引入新参数的情况下将图像生成模型转换成了图像编辑模型。其秘诀是在保持原始图像和生成新内容之间寻找平衡,最终得以在图像编辑的通用性、可控性和高质量上实现新的突破。解决了传统 AI 图像编辑中存在的多个痛点。
据了解,SeedEdit 已在豆包 PC 端和即梦 AI 上线网页端开始测试,用户可以通过简单的指令实现高效的图像编辑。与 Dall・E3 和 Midjourney 等竞争对手相比,SeedEdit 在编辑的便捷性和响应精准度上更具优势。(@AIbase 基地)
2、Suno 发布 V4 音乐生成模型音频演示视频,音质和风格大提升
近日,Suno 公司发布了其最新的 v4 音乐生成模型的音频样本。这些演示音频展现了与之前版本相比,音质、音色多样性和一致性都有了显著提升。
Suno 的 v4 模型通过深度学习技术对大量音乐数据进行训练,旨在生成更自然、更丰富的音乐作品。与以往版本相比,v4 模型在音频合成方面的表现更为出色,能产生更具表现力的乐曲,增强了音乐的情感表达。听众在试听样本时,能够明显感受到音质的细腻程度和旋律的流畅性,给人以耳目一新的体验。
为了使这一新模型的功能更为全面,Suno 还对音乐的多样性进行了优化。通过对不同风格和流派的音乐数据进行学习,v4 模型能够生成多种风格的音乐,满足不同听众的需求。
此外,模型在保持音乐一致性方面也有所改进,无论是在旋律、节奏还是和声方面,v4 都能够保持高度的协调性。
这一系列的改进使得 Suno 的 v4 音乐生成模型不仅适用于个人创作,还可以被广泛应用于商业音乐制作、游戏音乐及其他需要背景音乐的场合。Suno 希望通过这一创新,能够推动 AI 音乐生成技术的进一步普及和应用。(@AIbase 基地)
3、X 正在测试 AI 聊天机器人 Grok 的免费版本
据 TechCruch 报道, X 一直将其 AI 聊天机器人 Grok 限制给高级付费用户使用。
不过,X 似乎正准备向免费用户开放聊天机器人。
上个周末,有部分应用研究人员和用户发布了有关聊天机器人 Grok 免费版将向特定地区用户开放的消息。据研究人员表示,目前免费的使用次数有限制:Grok-2 模型每两小时 10 次查询,Grok-2 mini 模型每两小时 20 次查询,每天三个图像分析问题。
报道指出,要免费使用 Grok,用户的帐户必须至少有七天的历史并且与其关联的电话号码。(@APPSO)
4、Google 正式推出 Gemini AI 驱动的视频演示应用 Vids, 通过简单提示即可生成视频演示
Google 正式推出了其 Gemini AI 驱动的视频演示应用程序 Vids,用户可以通过简单的提示生成视频演示。
Vids 集成了 Gemini 的生成式 AI 功能,用户只需提供提示或 Google Drive 中的文档,系统即可生成一个初始视频故事板,包括推荐的场景、脚本、背景音乐等。用户可以通过「Help me create」功能快速获取一个编辑草稿,大大简化了视频制作过程。
Vids 还支持语音旁白,可以选择 Gemini 的预设 AI 语音或录制自己的语音。系统还包含滚动式提词器,帮助用户在录制过程中自然流畅地呈现信息。此外,用户可以添加自己的视频、屏幕录制和音频录制,以便制作多样化的视频内容。
Vids 的主要功能包括自动插入素材视频、生成脚本、以及创建 AI 语音旁白,用户无需亲自录音。Google 表示该工具可用于将客户支持文章转化为视频、制作培训视频、发布公司公告、生成会议回顾等。(@ 小互 AI)
5、月之暗面创始人被前公司投资人提起仲裁,受理律师回应将提出抗辩
月之暗面创始人杨植麟、联合创始人兼 CTO 张宇韬被前公司循环智能时期的投资人在中国香港提起仲裁,相关电子仲裁申请书也已递交 HKIAC(香港国际仲裁中心)。
对此,铭德律师事务所资深合伙人 David Morrison 律师今日回应第一财经称:「本所已接受杨植麟先生、张宇韬先生委托,关注到相关仲裁事项。我们认为该事项既缺乏法律依据,也不具备事实基础,本所将依法提出抗辩。」
另据知情人士消息称,本次仲裁的申请方,来自循环智能以及循环智能 7 家投资方中的 5 家:金沙江创投、靖亚资本、博裕资本、华山资本和万物资本。
上述知情人士表示,此次仲裁申请可能缘起于,在尚未拿到来自循环智能的几个投资方(金沙江创投、万物资本、靖亚资本、华山资本和博裕资本)的同意豁免书之前,杨植麟和张宇韬等人就已启动融资并创立月之暗面。(@IT 之家)
02 有态度的观点
1、OpenAI 产品负责人:现在的模型受限于评估方法
OpenAI 的首席产品官 Kevin Weil 和 Anthropic 的首席产品官 Mike Krieger 共同探讨了人工智能领域的多个核心议题。
他们讨论了当前 AI 模型的局限性,强调这些局限更多地在于评估方法而非智能水平本身,指出产品经理的角色正在经历转变,从传统的角色向研究型产品经理演进,这要求他们掌握编写评估标准和模型微调等新技能。
两位产品负责人还展望了 AI 的未来,提出了「主动性」和「异步」作为 AI 发展的关键词,预测模型将变得更加主动,监控用户邮件、发现趋势、准备会议内容,同时也会更异步,可能需要时间来思考和回答。
此外,他们对用户适应 AI 的速度表示惊叹,预计 AI 将模仿人类思维,以指数级速度迭代升级,并以我们人类互动的所有方式进行互动,预示着全新的人机交互范式。(@APPSO)
2、OpenAI 联合创始人 Sutskever 预测大模型扩张时代或将终结
据路透社报道,主要 AI 实验室正面临困境。开发大型语言模型不仅需要投入数千万美元,还常常遭遇系统崩溃等技术难题,评估一个模型的性能往往需要持续数月之久。
这种发展瓶颈已经波及行业巨头。有报道称 OpenAI 的新型 Orion 模型相比 GPT-4 提升有限,谷歌的 Gemini2.0 也遇到类似困境。Anthropic 方面,其首席执行官 Dario Amodei 表示正在重新规划 Opus3.5 的开发路线。
OpenAI 前联合创始人、现 Safe Superintelligence(SSI)负责人 Ilya Sutskever 指出:「2010 年代是扩展的时代,现在我们进入了探索与发现的新阶段。」这一表态格外引人注目,因为 Sutskever 曾是「越大越好」理念的倡导者。
行业新方向指向「测试时计算」,即赋予 AI 模型更多时间来逐步思考和解决问题。这种方法着重培养 AI 系统的推理能力,使其能够生成多个解决方案并进行评估,而不是简单地快速作答。
这一转变也可能影响硬件市场格局。虽然 Nvidia 在传统 AI 训练硬件领域占据主导地位,但新的计算范式为 Groq 等其他芯片制造商带来了机遇。不过,业内预计未来可能会同时采用传统方法和新方法,以实现最优成本效益。
多位业内人士认为,虽然传统的语言模型开发仍将持续,但行业重心已经开始转移。这标志着 AI 发展进入了一个更注重质量和思维能力的新阶段。(@AIbase 基地)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻