AI测试 OpenAI 再发 Sora 新短片,传 Sora 两周内推出;李飞飞团队出品空间智能版 ImageNet 丨 RTE 开发者日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
01 有话题的新闻
1、OpenAI 再发 Sora 新短片,传 Sora 两周内推出
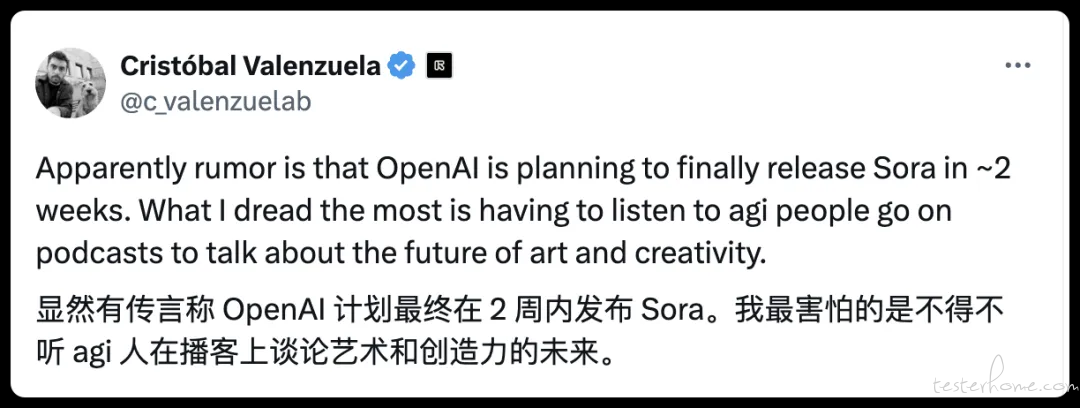
近日,伦敦艺术家 Jon Uriarte 与 OpenAI 联合创作了一支短片。Jon Uriarte 表示,Sora 的最强之处在于,能够找到「精确视觉」与意外惊喜之间的平衡。
「Sora 创造的视觉效果让我惊叹——那种照片级的质量,纹理细节。它生成的图像感觉非常自然,同时具有惊人的精确度。」
谈及 Sora 对创作过程的影响, Jon Uriarte 称:「我没想到构思一个想法的过程会如此顺畅。我对某些「画面」有清晰的构想,但在创作的过程中,新的想法也自然而然地浮现出来。对我来说,这就像写作或做白日梦一样。」另外,据 Runway 联合创始人 Cristóbal Valenzuela 在 X 平台引用传言称,OpenAI 计划在大约两周内发布 Sora。(@APPSO)
2、CogSound:为无声视频增加动人音效
CogSound 是智谱最新推出一款基于人工智能技术的音效生成模型,能够根据视频内容自动生成与画面匹配的音效,为无声视频添加逼真的音频体验。
CogSound 的生成能力涵盖了多种复杂音效,例如爆炸声、水流声以及交通工具的声音等,并通过先进的技术确保音视频的高度同步。
之所以能达到这种效果,是因为 CogSound 采用了一种叫做「分块时序对齐交叉注意力」的技术,简单来说就是把视频和音频分成一小块一小块,然后让它们互相「认识」一下,确保每个音效都能找到对应的画面,每个画面也都能找到对应的音效。这样一来,视频看起来就更加自然流畅,就像原声配音一样。
它还采用了「基于 Unet 的潜空间扩散」和「旋转位置编码」等技术,这些技术名字听起来很复杂,但其实原理很简单,就是为了让 CogSound 生成的声音更加逼真、更加连贯,避免出现「断断续续」或者「错位」的情况。
CogSound 将与智谱新推出的视频生成模型 CogVideoX v1.5 一起,成为「新清影」,提供更多特色的视频生成服务。(@AIbase 基地)
3、OpenAI 安全系统团队负责人宣布离职
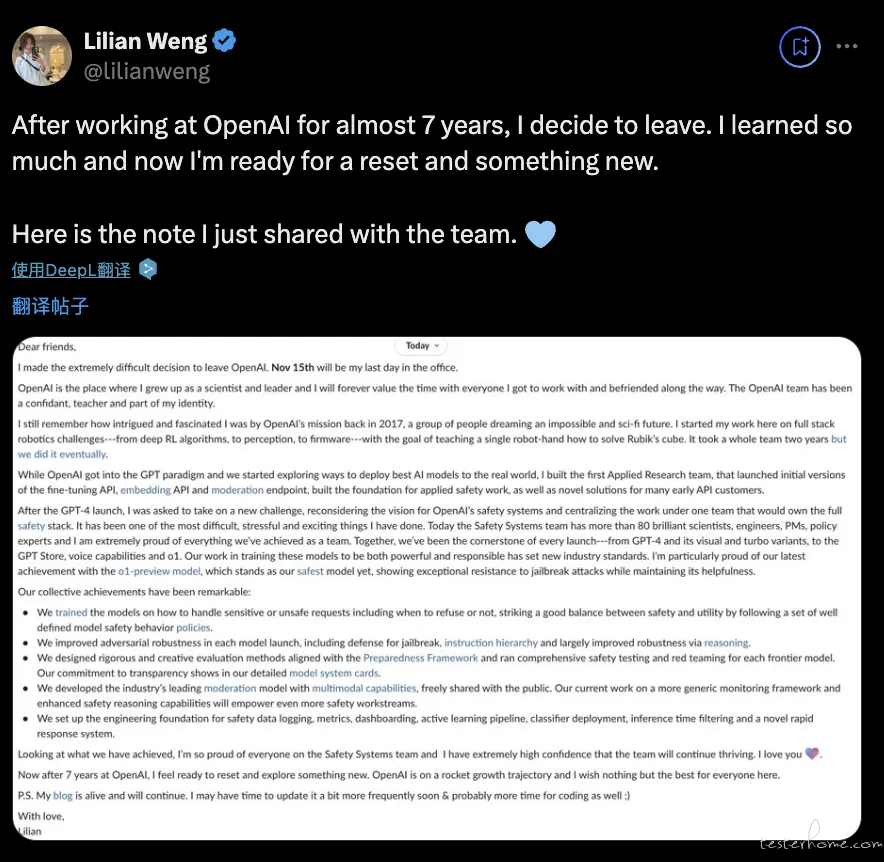
近期,OpenAI 安全系统团队负责人翁荔(Lilian Weng)在 X 平台宣布,她将于 11 月 15 日离职,结束在 OpenAI 长达七年的职业生涯。
在离职信中,她表示离开 OpenAI 是一个艰难的选择。在 OpenAI 任职期间,翁荔曾担任安全系统团队负责人和研究与安全副总裁等职位,同时还参与过 GPT-4 项目的预训练、强化学习 & 对齐等工作。
另外,据 TechCrunch 的报道,OpenAI 的高管和安全研究人员正在努力进行过渡,以接手翁荔的工作。OpenAI 发言人还在一份电子邮件声明中表示:「我们深深感谢 Lilian 对突破性安全研究和建立严格的技术保障所做的贡献。」(@APPSO)
4、古尔曼:Vision Pro 的第一个杀手级应用程序已经到来
在最新一期的《Power On》中,彭博社记者 Mark Gurman 表示,Apple Vision Pro 引入的虚拟曲面显示器功能,代表了 Vision Pro 的第一个真正的杀手级应用程序。
Apple Vision Pro 可作为 Mac 的外接显示屏使用,在 6 月的 WWDC 上,苹果也宣布将进一步完善该功能,将虚拟曲面显示器模式引入默认尺寸,并提供新的宽屏和超宽显示器选项。
Gurman 在报道中指出,苹果在上周发布了这些功能的测试版。在他看来,苹果这一举措相当于提供了一个高分辨率的 Mac 外接显示器,视觉上像是有无限大的屏幕空间一般。他还表示,在这一功能推出之后,他使用 Vision Pro 频率有了明显提升。
Mark Gurman 称,宽屏和超宽屏显示器选项,将作为 VisionOS 2.2 的一部分提供给所有 Vision Pro 用户,该版本预计将于 12 月初发布。(@APPSO)
5、空间智能版 ImageNet 来了!李飞飞吴佳俊团队出品
斯坦福李飞飞和吴佳俊团队发布了 HourVideo,这是一个新的视频基准数据集,旨在评估 AI 对长达一小时的理解能力。该数据集包含来自 Ego4D 的 500 个第一人称视角视频,时长视频在 20 到 120 分钟,涉及 77 种日常活动。与以往的数据集不同,一小时视频测试长视频理解中的多模式能力,任务包括总结、感知、视觉推理、导航等 18 个子任务。
HourVideo 的生成数据过程包括筛选视频、生成多选问题(MCQ)、模型优化、盲选和专家优化,确保问题需要长视频理解才能准确回答。测试显示,人类在该基准上的表现明显优于现有的多模态模型,其中准确率达到 85.0%,领先于最佳多模态模型 Gemini Pro 的 37.3%。人类实验还验证了分任务评估的有效性,大幅降低了计算成本。
HourVideo 团队计划扩展数据集,纳入更广泛的视频源和其他感官模式,同时强调开发过程中的隐私和伦理考量。项目的主要中断包括李飞飞和她的博士生 Agrim Gupta、Keshigeyan Chandrasegaran,以及景观助理教授吴佳俊。(@ 极客公园)
6、媒体爆料:发现新一代大模型「没有那么大飞跃」,OpenAI 已经改变策略
OpenAI 即将推出的新旗舰模型「Orion」,其进步幅度前两代有所改变,这挑战了 AI 领域的「缩放调整」。据 The Information 报道,「Orion」已完成 20% 的训练,尽管表现接近 GPT-4,但进步不如前两代飞跃。该模型在语言任务上表现出色,但在编码等任务上的表现或未超越前作。此外,其运行成本最高。
OpenAI 的员工指出,Orion 部分接受了 AI 生成的数据训练,这可能导致其性能与旧模型相似。随着大规模数据减少,计算成本增加,AI 公司在训练升级的改进上投入更多,探索新 OpenAI 专门构建团队优化训练数据应用,并通过复杂任务和人工评分提升模型能力。
然而,训练和运行 AI 模型的成本巨大,模型复杂度增加导致推理成本急剧下降。尽管如此,行业内领袖如 Sam Altman 和马克·财务扎克伯格仍然认为传统扩展法未到极限,OpenAI 等公司继续投资建设数据中心以增强计算能力。
但 OpenAI 研究员诺姆·布朗在 TEDAI 大会上表示,未来更先进的模型可能带来数百亿美元的开支,这对构成巨大的挑战。他质疑财务是否应投入如此高额的成本,暗示缩放范式可能难以长期维持。(@ 极客公园)
02 有态度的观点
1、英伟达 CEO 黄仁勋:AI 员工即将成为职场新常态
在最新的企业活动中,英伟达(Nvidia)首席执行官黄仁勋(Jensen Huang)表示,人工智能(AI)员工将很快成为现代职场的标准配置。他强调,随着技术的进步和应用的普及,AI 将在各个行业中扮演越来越重要的角色。
黄仁勋指出,AI 不仅能够提升工作,还能够承担一些性、繁琐的任务,解放人类员工的时间和精力。他提到,企业在利用 AI 技术的过程中,能够实现更高的力,并且降低运营成本。这一趋势将推动企业在智能化转型方面不断前行。
在谈到 AI 员工的未来时,黄仁勋充满信心。他预测,未来五到十年内,许多企业将会采用 AI 作为助理,帮助员工处理日常工作。这样的变化将使得员工能够更专注于创新和决策,而非耗费大量时间在机械性的工作上。
他还补充道,随着人工智能技术的不断成熟,AI 的学习和适应能力将显著提高。未来的 AI 将能够根据企业的具体需求进行个性化调整,成为每个团队中不可或缺的一部分。这样的发展不仅会改变员工的工作方式,也将重塑企业的运营模式。
黄仁勋在活动中还展示了英伟达在 AI 领域的最新技术和产品,强调了公司在推动这一趋势中的重要角色。他认为,AI 技术的进步是企业未来成功的关键,也是全球经济发展的新动力。(@AIbase 基地)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻