作者简介:
- 王文艳,来自货拉拉/技术中心/质量保障部,测试专家,主要负责货拉拉大数据领域的质量保障和效能建设工作。
- 窦婷,来自货拉拉/技术中心/质量保障部,资深测试工程师,主要负责货拉拉大数据领域的质量保障和效能建设工作。
- 董帅,来自货拉拉/技术中心/质量保障部,高级测试工程师,主要负责货拉拉大数据领域的质量保障和效能建设工作。
1. 背景与挑战
随着货拉拉业务的高速发展,大数据在用户行为分析、广告定向投放、风险控制、用户画像、为公司管理层和运营团队提供决策帮助等方面,得到了越来越广泛的应用。
大数据的源数据来源于业务数据、埋点数据等,每天有百亿级的数据交互,业务数据的复杂性和快速增长的数据量级,也对质量保障有了更高的要求。我们需要从高质量、高效率、高可用、高主动性 4 个方面来保证大数据的质量。对于大数据测试人员来说也是很大的挑战,以下图片从技能、数据特点、效率三个方面分析了传统测试与数据测试区别,总结了货拉拉数据测试的早期的问题及大数据测试的痛点。

1.1 技能方面
数据测试需要更高的技术要求。除了传统的黑盒、白盒、灰盒测试能力,数据测试还需要掌握以下几个方面的能力:
- 海量数据测试能力:数据测试需要掌握不同的数据库的 SQL 技能来处理大量的数据,能够有效地处理和分析这些数据,找出其中的问题。
- 数据仓库分层测试能力:数据仓库通常会分为多个层次,每个层次的数据都需要进行测试。测试人员需要理解每个层次的数据结构和业务逻辑的不同,才能进行有效的测试。
- 数据验收标准的灵活制定能力:数据测试的验收标准可能会根据业务需求和数据特性进行变化,测试人员需要能够灵活地制定和调整这些标准。
- 数据洞察能力:数据测试不仅仅是找出数据中的错误,更重要的是要有通过数据洞察业务的能力。这就需要测试人员具有一定的数据分析和业务理解能力。 因此,数据测试人员不仅需要具备传统的测试技能,还需要具备数据处理、数据分析和业务理解等多方面的能力。
1.2 数据方面
传统测试主要关注业务逻辑,数据量少,结构单一。大数据测试面临数据量大,结构复杂的挑战,同时对数据质量要求更高。大数据的源数据来源于业务数据,所以数据质量极易受到业务问题的影响,导致线上数据质量出现问题。想从海量数据中发现问题,犹如大海捞针,在早期,我们的数据测试手段是有限的,没有测试工具及平台来支撑,导致我们存在以下难点。
- 数据问题发现难:海量的数据量使得人工逐条检查几乎不可能,结构化数据和非结构化数据,使得数据问题的发现变得更加困难,大数据的质量问题可能包括数据的准确性、完整性、一致性、时效性等多个方面,结合不同的业务场景,使得测试场景即多又复杂。多种原因使得数据问题发现难。
- 数据质量保障难:数据质量保障是确保数据的准确性、完整性、一致性、可靠性和及时性的重要过程。这个过程包括数据校验、数据监控、数据治理和建立数据质量标准等关键步骤。为了实现数据质量保障,需要结合技术手段和管理手段,采用全面和系统的方法来进行。
1.3 效率方面
业务测试的标准是业务逻辑,对功能的测试结果是即时可见的。但数据测试的标准不仅是业务逻辑,还包括数据质量,数据质量的问题也会引发很大的问题。在早期,手工的数据测试、人员的紧缺、激增的数据业务需求,导致在测试效率方面存在很大的痛点。具体难点表现在如下:
- 测试用例管理难:同一表每次需求改动,由于业务数据的变化,还需重新计算结果,测试人员需要重新进行测试,由于缺少平台的支撑,测试用例无法进行有效沉淀及统一管理,导致测试用例复用率低。
- 回归效率低:最开始是手工进行测试,需要手动进行测试回归,回归耗时长,随着业务扩展,回归范围扩大,手工回归耗时耗力,不能满足项目需求,这些导致了整体的测试效率低。
2. 方案与目标
针对货拉拉大数据测试保障的重点和难点,我们采用了以下几种解决方案:
- 测试过程简单化:用例模型、模版、业务场景灵活可配置,平台自动生成对应脚本,无需测试人员手工编写,标准化用例编写流程的同时,也降低用例编写成本和门槛,提高测试效率。
- 数据测试自动化:支持根据场景灵活配置数据测试自动化用例和场景,同时可一键将测试用例转为自动化用例,降低数据测试自动化编写成本及回归测试成本,提高测试效率。
-
数据质量监控告警:建设定时线上巡检监控及异常告警的能力,从被动跟着暴露的数据质量问题走,转变为主动发现拦截问题。
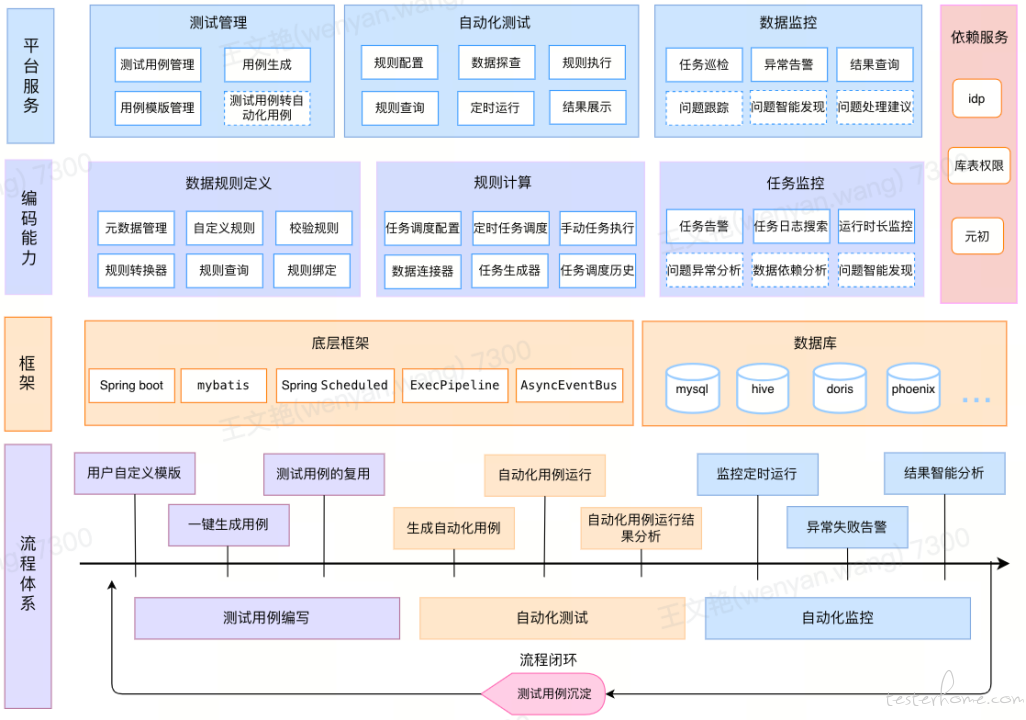 为了达成上述目标,我们打造了大数据测试平台,致力于数据测试过程中每个环节都可自动化,缩短测试周期,提高人效。做到仅需简单的操作,0 数据测试经验同学也能轻松上手,无需具备不同数据库复杂 SQL 编程能力,降低数据测试技术门槛。同时还提供了用例沉淀的能力,做到根据配置生成测试用例-->执行-->智能分析-->转换监控-->沉淀自动化的良性链路闭环。
为了达成上述目标,我们打造了大数据测试平台,致力于数据测试过程中每个环节都可自动化,缩短测试周期,提高人效。做到仅需简单的操作,0 数据测试经验同学也能轻松上手,无需具备不同数据库复杂 SQL 编程能力,降低数据测试技术门槛。同时还提供了用例沉淀的能力,做到根据配置生成测试用例-->执行-->智能分析-->转换监控-->沉淀自动化的良性链路闭环。
3. 能力建设
3.1 平台架构介绍
大数据测试平台基于 Spring Boot 构建,并依赖于混合引擎进行数据计算。它提供了一系列强大的功能,包括数据质量模型构建、数据质量模型执行、数据质量任务管理、异常数据发现保存以及告警功能等。此外,该平台还提供了数据质量模型资源隔离和权限隔离等特性,确保了数据的安全性和私密性。该平台具备高并发、高性能和高可用的大数据质量管理能力,能够有效地满足用户在大数据测试和管理方面的需求。
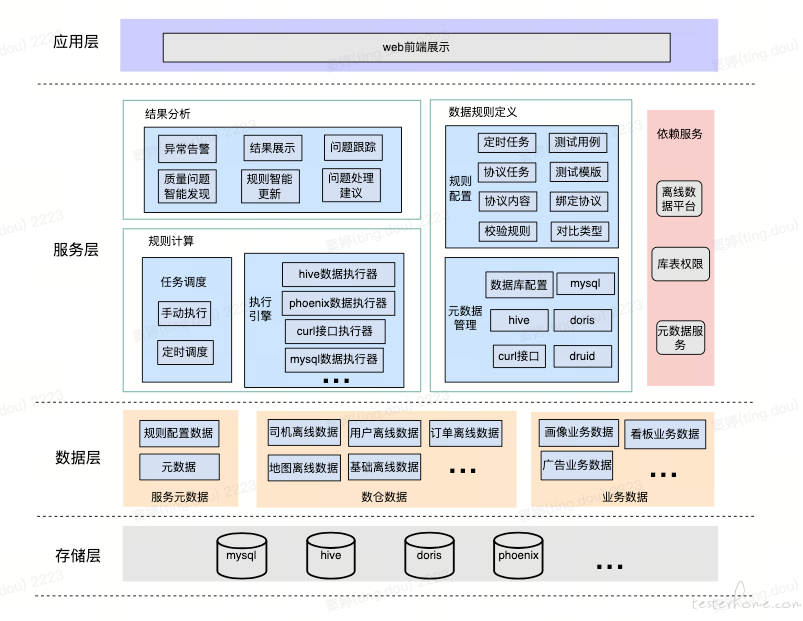
大数据测试平台的架构设计精细且全面,主要包括应用层、服务层、数据层和存储层。
- 应用层:是平台的入口,主要提供了模板管理、用例管理、协议管理和定时任务管理等功能。这些功能为用户提供了便捷的操作界面,使得数据测试过程更加高效和简便。
- 服务层:提供了平台的基础能力,包括规则计算、数据规则定义和结果分析等基本能力。这些能力为数据测试提供了强大的支持,确保了测试的准确性和有效性。
- 数据层:包含了大数据测试的来源数据和平台的元数据。大数据测试来源数据主要包括数据仓库的数据和业务数据等,这些数据是数据测试的基础和来源。
- 存储层:支持多种数据类型的存储,包括 mysql、hive、doris、phoenix、hbase 等。这些数据存储方式为数据的保存和管理提供了多样化的选择,满足了不同用户的需求。
3.2 平台核心能力
大数据测试平台主要涵盖四大核心功能:测试管理、规则执行、结果分析以及监控告警。在大数据测试流程中,我们有能力在平台上生成测试用例并沉淀这些测试用例,测试用例的生成是基于平台上配置的测试执行规则,这主要涉及到规则的定义。随后,我们会根据配置的测试规则进行计算。对于这些计算结果,我们将进行深度分析。此外,我们还可以设定任务定时运行,一旦运行失败或者结果未达到预期,平台将及时进行通知。接下来,我们将详细阐述这四大核心功能的特性和优势。
3.2.1 测试管理能力
大数据测试平台的测试管理能力主要由两大模块构成:用例模板模块和用例管理模块。
- 用例模板模块:负责管理和维护常用的用例模板,它支持管理用例模板,允许用户根据实际需求灵活自定义用例模板。这大大提高了用例模板的适用性和灵活性。用例模版支持单表模型、多表模型和自定义模型等多种模型,平台还预设了多种用例模版如空值检查、空白检查、数字检查、枚举检查等常见检查的数据质量校验模板,简化了数据质量模型的定义。
- 用例管理模块:包含了根据模板生成测试用例、保存和管理测试用例的功能。用例管理模块可以根据模板自动生成各种测试用例,从而节省了编写测试用例的时间。更进一步,它还可以将测试用例转化为自动化测试用例。 模版配置如 “字段空值率” 模版:
select
[count( case when {{emptyFields}} is null or {{emptyFields}} ='' then 1 end )/count(1) as {{emptyFields}}_rate $,;emptyFields$]
from {{tableName}}
where 1=1 and [{{partField}} = date_sub(current_date(),1) $and;partField$] ;
根据模版生成测试用例核心代码【代码已简化,只保留核心逻辑】:
//解析模版,转化成规则配置类
MonitorRuleTemple monitorRuleTemple = covertFromModule(config,MonitorAgreement.class);
//获取规则配置中的sql语句
String sql =monitorRuleTemple.getSql();
/*处理sql语句中带[]符号的部分,[]部分为循环部分,[表达式 $连接符号;循环变量$]
如下的表达式,
[{{partField}} = date_sub(current_date(),1) $and;partField$]
若partField的实际参数值为2个字段:dt、city_id时,根据如上表达式,生成的结果为:"dt ='2024-06-15' and city_id=1000"
*/
if(Objects.nonNull(sql)){
sql =sqlProcess(sql,paramsMap);
monitorRuleTemple.setSql(sql);
}
/*
处理sql语句中,除了[]之外的{{param}}参数。这里会根据实际参数替换表达式中的值,
如下表达式:{{param}},若param的值为:city_id时,则会将sql语句中所有的{{param}}都替换为city_id字段。
*/
ruleProcess(monitorRuleTemple,paramsMap);
return monitorRuleTemple;
3.2.2 规则执行能力
规则执行是大数据测试平台的核心能力,主要由规则配置、规则计算两个功能组成。
- 规则配置:是大数据测试过程的关键步骤,这里我们将根据业务的需求,将测试 SQL 代码及校验规则配置成待执行的配置,这个过程可以被抽象为规则配置。
- 规则计算:是对配置规则的执行和计算。我们的平台支持混合引擎能力,可以针对不同的数据源进行执行。目前已经支持的数据源包括 MYSQL、Hive、Doris、Phoniex 等数据库、以及 Curl,实现了跨库数据对比。 混合引擎执行核心代码如下【代码已简化,只保留核心逻辑】:
//货运规则配置中脚本中数据源的类型
DataSourceType sourceType = DataSourceType.findByTypeByte(dataSourceType);
//根据数据源的类型,获取不同的数据源客户端执行方法
switch (sourceType) {
case INTERFACE_CURL:
queryTask = curlClient;
break;
case INTERFACE_HTTP:
queryTask = httpClient;
break;
case HIVE:
queryTask = idpClient;
break;
case MYSQL:
queryTask = mySqlClient;
break;
case HBASE:
queryTask = hbaseClient;
break;
case PHOENIX:
queryTask = phoenixClient;
break;
default:
queryTask = null;
}
return queryTask;
3.2.3 结果分析能力
在大数据测试执行结果出来之后,我们就需要对其进行深入分析。在协议配置中,我们支持结果预设,且支持多种规则比较的类型如大于、大于等于、小于、小于等于、等于、不等于、同环比、范围比较等。除此之外,规则配置中还支持原始指标和转换指标,对于 SQL 的运行结果,我们可以对执行结果进行表达式再计算之后再进行规则比较。
规则比较核心代码【代码已简化,只保留核心逻辑】
//这里举其中一种比较规则的实现方式:范围的比较的实现方式
//首先检查输入的数据的类型,仅支持数值类型
RuleCheckTypeStrategy.checkNotSupportNonNumeric(ruleResultContext.getActualResult(), this);
//获取预期的范围
Double expectRange = Double.valueOf(ruleResultContext.getExpectRange());
//计算实际值的差值的范围
Double acutalRangeBoundary = RuleCheckTypeStrategy.computeThresholds(ruleResultContext.getActualResult(), this);
//若实际值的范围在预期范围内,则规则比较通过,否则不通过
boolean flag = true;
flag = compareRange(expectRange,acutalRangeBoundary);
return flag
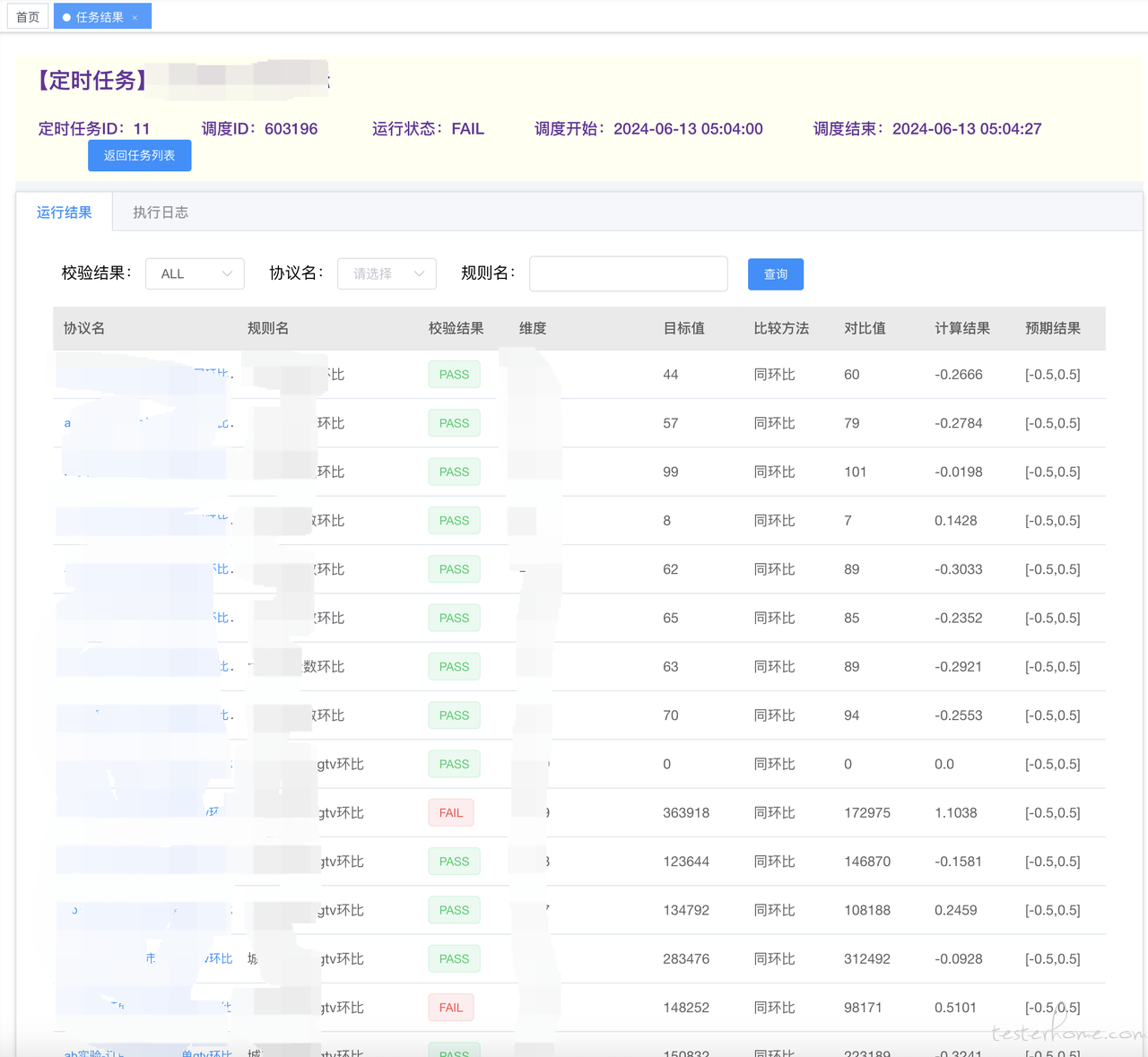
执行结果展示
3.2.4 监控告警能力
大数据测试平台还提供了定时调度、告警通知的能力,任务中支持定时运行的配置,定时配置是使用 corn 表达式方式,可以灵活支持用户的定时运行的需求。平台还提供了告警通知能力,任务配置中可以配置失败告警通知人或通知群,在配置的规则每天定时运行的结果出现问题时,我们可以及时收到告警通知。这些功能可以满足大数据测试的监控告警的需求。
4. 平台实践与成果
随着货拉拉大数据测试质量平台能力已经具备,接下来我们将从三个阶段介绍如何使用平台能力赋能货拉拉大数据质量全流程测试
4.1 平台实践
4.1.1 功能测试阶段
大数据测试时,我们会根据业务需求转换成规则配置,然后对规则做分析和预置,使用模版功能可以一键生成用例,并且支持一键执行用例。
- 配置数据模版并生成测试用例:我们根据数据需求选择不同的数据模版。根据选择的用例模版规则自动生成测试 SQL,一键生成测试用例。这些用例可以执行验证、执行冒烟用例或进行数据产品验收。
- 智能分析测试和数据探查:我们还会测试表关联的下游表,对下游表的关联字段进行精准的分析验证,进一步进行数据探查以发现可能出现的 bug。智能分析和数据探查工具为数据的高质量输出提供了保障。
- 结果分析判断和用例沉淀:通过配置中预置的预期结果,能够快速智能地判定用例执行结果。此外,还可以将测试用例沉淀成自动化用例,以进一步覆盖开发提测和测试回归场景下的数据质量。
4.1.2 自动化回归阶段
功能测试完成之后,我们可将一些用例一键沉淀成自动化用例,可用于需求的自动化回归测试。
- 自动化用例沉淀:筛选可复用的测试用例一键沉淀为自动化用例,加入到回归测试库中,需求改动之后,选沉淀的自动化用例进行回归测试,提高回归效率,持久保障数据质量。
- 自动化数据测试场景:自动化测试可应用于大数据平台数据流转、业务系统数据迁移、数据应用系统和回归测试等场景中,复用自动化测试用例及多任务并行运行自动化用例,极大缩短了测试时间,在这些数据场景测试中,测试时间可缩短约 70%。
4.1.3 线上监控阶段
无论实时或离线的大数据平台任务和库表数据,都需添加监控任务以便及时发现并解决问题。大数据测试平台已提供了一套完整的线上质量监控功能,实现全天候的数据质量保障。
我们已针对以下类型添加了监控告警:
| 监控类型 | 描述 |
|---|---|
| 数据指标监控 | 对字段级的监控,监控规则如:数据掉底、同环比、枚举值、数据范围、字段关系等 |
| 横向数据监控 | 大数据的产品和公司其他职能部门的同类产品指标的横向对比,如大数据和业务数据的实时横向对比等 |
| 竖向数据监控 | 大数据不同产品间的同类指标的对比,如实时数据和离线数据的对比,不同产品间履约类指标的对比等 |
| 业务逻辑异动监控 | 不同业务数据反映了该业务正常运营的情况,业务数据的异动同时也代表该业务有可能出现问题,如画像人群名称的监控,交易金额倒挂的监控等 |
| 数据应用链路监控 | 监控数据应用全流程的数据准确性、及时性、一致性 |
随着监控内容的丰富,线上质量得到了更好的保障。在配置监控告警时,我们可以设置不同的警告级别,并根据级别以不同方式通知负责人,如电话、短信、飞书等。
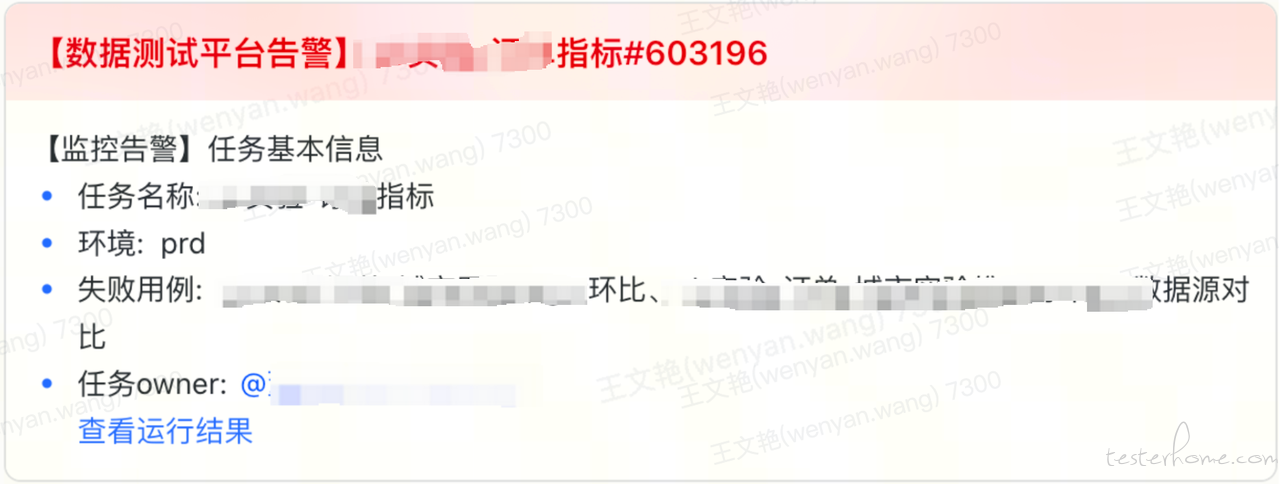
飞书告警示例:
4.2 成果展示
4.2.1 全流程提效
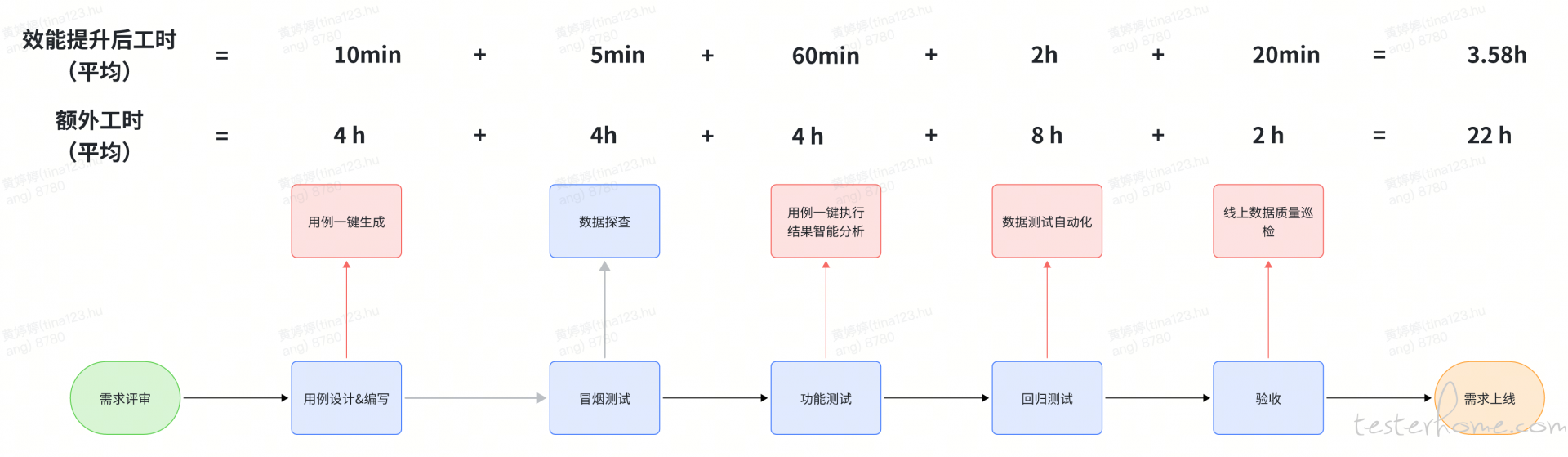
- 全流程提效:从用例一键生成一键执行到用例一键转成自动化再到线上数据质量巡检能力的实现和应用,使我们的数据测试周期从 5 天降低到 1.5 天,每个需求的额外工时也从 22 小时降低到 3.58 小时,也让我们有更丰富的手段和方法为 HLL 的数据质量保驾护航。
- 多场景应用:适用于大数据平台数据流转的测试场景、业务系统数据迁移的测试场景、数据标准落标的测试场景、监管报送类系统的测试场景、数据应用系统的测试场景、回归测试场景等,截止到当前,已支持 200+ 需求,1000+ 的执行次数,为我们节省 800+ 人日。
4.2.2 质量提升

- 质量数据:通过大数据测试平台,总计发现 300+ 问题,其中监控告警感知异常变动 1000+ 次,帮助数据测试发现 30+ 问题,及时发现因上游任务变更、业务异动、线上资源紧张等原因导致的异常,避免对线上造成更深的影响。
- 业务覆盖:3000+ 的自动化和监控用例,100% 覆盖核心表,数据应用链路 100% 覆盖,及时发现核心表的线上数据异动,以及数据应用的线上业务异常。
5. 未来展望
随着智能化的发展,未来我们希望大数据的测试能够更智能更高效,达到智能化一体化。
- 智能建模:数据测试场景建模 - 根据不同业务场景灵活进行数据测试场景建模:自适应订单、用户、司机、风控、营销、账单模型等。
- 智能诊断:利用大模型智能预测任务改动的影响范围和风险点,进行精准测试。
- 智能测试: 根据诊断结果,利用大模型的能力智能生成用例、自动化提及线上监控。