AI测试 YouTube 上线「用相机拍摄」标签为真实视频「验明正身」;美国被曝考虑限制向中东国家出口 AI 芯片丨 RTE 开发者日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
01 有话题的新闻
1、美国被曝考虑限制英伟达、AMD 等向中东国家出口 AI 芯片
外媒援引知情人士消息称,美国已讨论限制英伟达、AMD 等美国公司对某些国家人工智能芯片的出口许可证设定上限。这些限制将重点放在波斯湾国家,这些国家对人工智能数据中心的需求越来越大,限制的举措将影响一些国家的人工智能能力。(@ 腾讯科技)
2、扎克伯格:联想基于 Meta Llama 大模型构建个人 AI 智能体 AI Now

联想集团于当地时间 10 月 15 日在美国西雅图召开年度 Tech World 大会。联想 CEO 杨元庆在主题演讲中,与 Meta 创始人兼 CEO 马克・扎克伯格一道宣布,联想与 Meta 合作基于 Llama 大模型推出面向 PC 的个人 AI 智能体 ——AI Now。
扎克伯格通过视频在主题演讲上表示,联想与 Meta 已经合作多年,推出了许多卓越的创新成果,将突破性的 AI 和混合现实技术带给更多人,共同构建一个更加智能的未来。
联想最新的个人 AI 智能体 ——AI Now,它正是基于 Meta 的 Llama 模型进行构建,将 PC 转变为更具实用性和个性化的智能设备。而这也是 Meta 开源 Llama 的一个重要原因,像联想这样的公司可以对大型语言模型进行微调,优化其在特定使用场景中的表现。
近期,Meta 刚刚发布了 Llama 3.2,这是 Meta 的首个开源多模态模型。Meta 发布了 110 亿和 900 亿参数的模型,以及更小的、专为在设备上运行而优化的 10 亿和 30 亿参数的模型。
扎克伯格称,我们相信,开源是目前最具成本效益、最可定制化、最值得信赖且性能最优的选择。如今,Llama 已处于前沿地位,正逐渐成为 AI 领域的行业标准,就像「Linux」在操作系统领域的地位一样。通过与 Llama 合作,联想在我们达到这一转折点的过程中扮演了重要角色,并为消费者带来了令人印象深刻的体验。(@IT 之家)
3、YouTube 上线「用相机拍摄」标签,为真实视频「验明正身」

YouTube 正在推出新的「用相机拍摄」标签,以表明上传的视频是否来自真实相机拍摄,且具有未经修改的画面和声音。
数字内容认证服务 Trupic 上传了一段视频到其频道,展示了新的「用相机拍摄」标签的实际效果,该标签会在视频描述面板中显示。Trupic 表示,这是「YouTube 上第一个带有 C2PA 内容凭证的真实视频」。
YouTube 依靠内容来源与真实性联盟(C2PA)标准来检测上传视频的真实性,这意味着该功能仅适用于支持元数据的录制设备和工具。该网站在关于这一新功能的帮助页面中表示,该标签「意味着创作者使用了特定技术来验证其视频的来源,并确认其音频和视频没有被修改过」。此外,创作者必须专门使用 C2PA 2.1 或更高版本的工具,标签才会出现,所以用户可能在很长一段时间内都不会经常看到这个标签。像徕卡这样的公司去年开始在硬件中实施内容凭证,但目前还不清楚这些凭证是否会触发 YouTube 的标签。
谷歌还在其博客中解释了其在 YouTube 上增加人工智能生成内容透明度的目标,视频不一定需要未经编辑才能获得标签,只是整个过程的每一步都必须支持 C2PA,并且要避免以下情况:
一是破坏来源链的编辑,或者使视频无法追溯到其原始来源。例如,如果用带有 C2PA 元数据的相机拍摄图像,然后将其保存到不支持 C2PA 2.1 或更高版本的手机相册中,这可能会破坏来源链。
二是对视频的核心性质或内容进行重大修改,包括声音和视觉效果。
三是进行使视频与 C2PA 标准(2.1 及以上版本)不兼容的编辑。(@IT 之家)
4、Adobe 推出多款 AI 工具:可构建 3D 场景、消除路人、清洁镜头
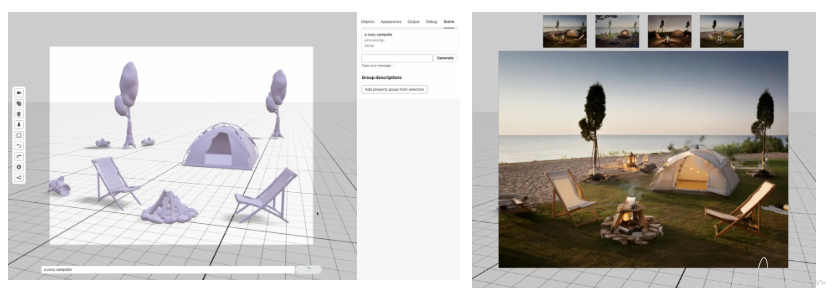
据 The Verge 今天凌晨报道,Adobe 近期展示了多款实验性的 AI 工具,可用于动画制作、图像生成、照片及视频的优化等领域,未来有望被整合到 Creative Cloud 中。
Project Scenic:该工具可让用户在使用 Firefly 模型生成图像时拥有更大的控制权。其能够生成一个完整的 3D 场景,用户可以自由添加、移动、调整场景中的物体大小,最终结果会根据 3D 场景生成相应的 2D 图像。
Project Motion:一款两步动画制作工具,用户无需动画经验即可给文本和基础图像添加动态效果。此外,用户也可以通过文本描述和参考图像,进一步为动画视频添加色彩、纹理和背景,从而实现更复杂的效果。
Project Clean Machine:一款专门用于清理图像和视频的工具,能够自动移除诸如相机闪光、路人等干扰元素。例如在移除下图背景烟花导致的过曝现象时,Clean Machine 会自动校正色彩和光线,保证画面一致性。
据报道,上述工具将作为「Sneaks」的一部分在 Adobe MAX 大会上首次亮相。Sneaks 是 Adobe 的一个展示新技术并收集用户反馈的项目,不少在 Photoshop、After Effects 等平台上提供的功能(如内容感知填充)都来源于此。(@IT 之家)
5、AsrTools,一款智能语音转文字工具

AsrTools 是一款智能语音转文字工具,旨在通过高效的批处理和用户友好的界面,将音频文件快速转换为精确的文字。该工具无需 GPU 支持,支持生成 SRT 和 TXT 格式的字幕文件,适合多种应用场景。其界面基于 PyQt5 和 qfluentwidgets,操作简单,适合各类用户使用。(@ 机器之心 SOTA 模型)
02 有态度的观点
1、普林斯顿教授 Arvind:构建大参数模型不再有效,数据正成为瓶颈;社会对 AI 过度恐惧
Arvind Narayanan 是普林斯顿大学的计算机科学教授,同时也是信息技术政策中心的主任。他是《AI Snake Oil》一书的合著者,并大力支持关于仅仅增加计算能力重要性的 AI 扩展迷思。
在一次采访中,Arvind 提到,数据量正成为大模型发展的瓶颈。从历史发展来看,计算资源提升模型性能的方式是通过构建更大的模型,从 GPT-3.5 到 GPT-4 之间最大的变化就是模型的规模。Arvind 认为这种趋势正在走向终结。现有的模型已经在几乎所有可获取的数据上进行了训练,数据量的增加可能不会像以前那样带来根本性的改变或新的能力。
对于合成数据,Arvind 认为其具有很大的局限性。合成数据在提升数据量方面可能并不总是有效的,因为它可能只是在牺牲数据质量,而没有提供新的学习内容。
Arvind 认为,小型化可能会成为 AI 模型的未来发展趋势,因为小型模型成本和隐私方面具有优势,并且随着技术进步,小型模型也能保持与大型模型相似的能力水平。
Arvind 提出,社会普遍对 AI 持有过度恐惧的态度,尤其是担心 AI 的自我意识和潜在威胁,但这种恐惧是没有根据的。AI 目前更多的是工具而非自主意识的实体。(@ Z potentials)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻