AI测试 Reflection 70B 遭质疑基模为 Llama 3;Replit Agent:编程 0 基础适用丨 RTE 开发者日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
01 有话题的新闻
1、Reflection 70B 遭质疑基模为 Llama 3,作者:重新训练
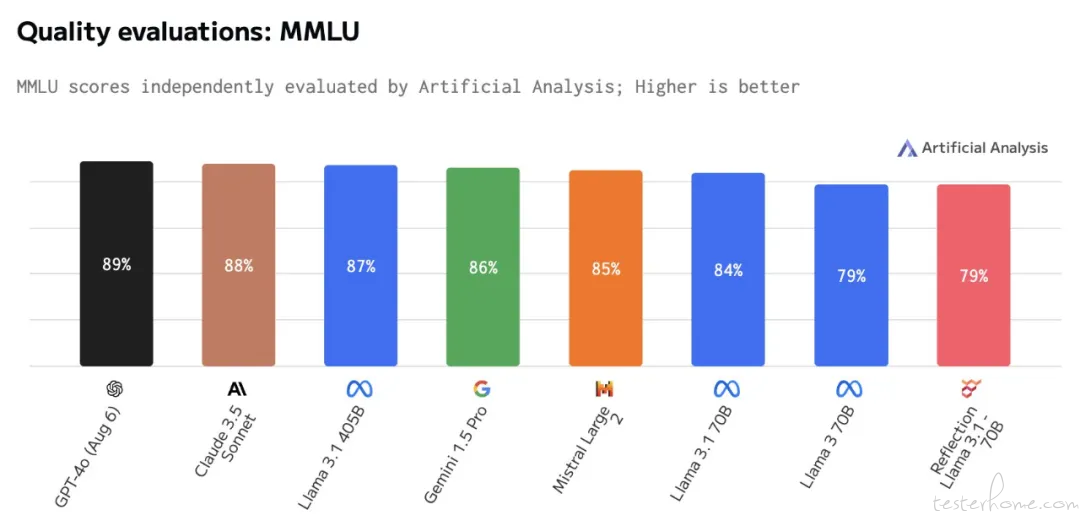
近期,开源大模型社区因 AI 初创公司 HyperWrite 推出的 Reflection 70B 模型引发热议。该模型基于 Meta 的 Llama 3.1 70B Instruct,使用 Llama chat 格式,确保了与现有工具和 pipeline 的兼容性。Reflection 70B 在多个基准测试(如 MMLU、MATH、IFEval、GSM8K)上表现超越 GPT-4,甚至超过了 Llama 3.1 405B,因而被誉为「开源大模型新王」。
Reflection 70B 由两位开发者(HyperWrite CEO Matt Shumer 和 Glaive AI 创始人 Sahil Chaudhary)仅用 3 周开发完成。然而,Artificial Analysis 的独立评估表明,该模型的 MMLU 得分仅与 Llama 3 70B 相同,并低于 Llama 3.1 70B。此外,科学推理与知识(GPQA)和定量推理(MATH)测试结果也未达到预期。
Reddit 上的讨论显示,Reflection 70B 可能是基于 Llama 3 而非 Llama 3.1,并使用了 LoRA(低秩近似)微调技术。部分用户通过代码分析验证了两者的权重差异,表明 Reflection 模型与 Llama 3 更为相似,尤其是在语言理解任务中反应不一致。此外,模型的权重问题也引发了社区质疑,开发者 Matt Shumer 解释称,Hugging Face 平台上传的模型权重出现问题,并计划重新训练模型。随着模型的更多测试结果曝光,社区对 Reflection 70B 的关注逐渐转向开发者的透明性和商业动机。开发者团队表示将尽快解决技术问题并重新上传训练后的模型,未来表现如何仍待观察。(@ 机器之心)
2、「国内首个端到端通用语音 AI 大模型」心辰 Lingo 发布,号称中文效果比 GPT-4o 更出色
西湖心辰于 9 月 5 日发布了心辰 Lingo 语音大模型,号称是「国内首个端到端通用语音大模型」。
官方表示,针对心辰 Lingo 端到端语音大模型的能力,在多个领域和中文上进行增强,使得心辰 Lingo 的中文语音效果,相较 GPT-4o 更为出色。心辰 Lingo 于 8 月 24 日开启内测,至今已经有超千家企业用户预约测试。
相比较传统 TTS,端到端语音大模型则是一种更为全面的技术,不仅可以语音识别,还集成了自然语言处理、意图识别、对话管理以及语音合成等多个环节,实现了从语音输入到语音反馈的完整交互过程。(@IT 之家)
3、特斯拉将获得 xAI 的 AI 模型授权并与其分享收入?马斯克回应称不准确
马斯克否认了《华尔街日报》报道特斯拉将获得 xAI 的 AI 模型授权,以帮助开发全自动驾驶(FSD)等技术,并且双方正在讨论未来收入的分享协议。
马斯克指出,尽管他没有完全阅读该报道及其所有观点,但报道的总体说法是不准确的。他承认特斯拉从与 xAI 工程师的讨论中学到了很多,但实际上并不需要从 xAI 那里获得任何授权。马斯克还解释说,xAI 的 AI 模型与特斯拉正在开发的模型之间存在巨大差异,xAI 的模型非常庞大,不适合在特斯拉的电动汽车上运行,而特斯拉的模型则具有非常密集的智能,因为它们专注于现实世界的驾驶。(@ 雷锋网)
4、国内首个 AI 大模型攻防赛启动,设立近 100 万元奖金池
9 月 6 日上午,在 2024 Inclusion・外滩大会「以 AI 守护 AI 大模型时代的攻守之道」论坛上,国内首个大模型攻防主题的科技赛事「全球 AI 攻防挑战赛」宣布正式启动。
这项赛事聚焦 AI 大模型产业实践,设计了攻、防双向赛道,邀请各路「白帽黑客」(IT 之家注:站在黑客立场攻击自己系统以进行安全漏洞排查的程序员)、技术人才分别进行针对文生图大模型「数据投毒」的攻防实战演练,以及金融场景大模型生成内容的防伪检测竞赛。
「攻击赛道」聚焦于文生图大模型的实际应用风险问题。参赛选手可通过目标劫持、情景带入、逻辑嵌套等多样化的动态攻击诱导技术,诱发大模型输出风险图像,以此激活大模型的潜在弱点和漏洞,增强大模型生图的安全免疫能力。
「防守赛道」则聚焦于 AI 核身中的金融场景凭证篡改检测,以应对日益严峻的 Deepfake 深度伪造及 AIGC 假证风险。大赛提供百万级凭证篡改数据训练集,参赛选手需要研发和训练模型,并利用对应的测试集评估模型有效性,给出数据伪造概率值。
该赛事由中国图像图形学会、蚂蚁集团、云安全联盟(CSA)大中华区联合主办,并得到了上海交通大学、浙江大学等 C9 高校及多家产学研组织的支持。
赛事设立了近 100 万元奖金池,并邀请了多位学术界和工业界的知名专家担任评委。
本次大赛于 9 月 6 日正式启动报名,11 月初完成赛事评审。即日起,选手可通过中国图象图形学学会官网、阿里云天池大数据众智平台官网等渠道报名。(@IT 之家)
5、Replit 发布 Replit Agent AI 应用开发助手,0 基础编程用户也能开发程序
Replit 发布了一款实验性产品:Replit Agent ,旨在帮助用户从零开始构建软件项目。它通过理解自然语言提示,使得任何技能水平的用户都能够更轻松地开发应用。
Replit AI Agent 可以帮助用户轻松开发应用程序。只需要用普通的语言描述你想要的应用,AI 就会帮你自动处理复杂的步骤,比如设置开发环境、编写代码、甚至部署到网上。即使你不会编程,也可以快速创建应用。
而且,你可以随时查看和修改 AI 生成的代码,学习编程的过程。它还支持手机使用,所以无论你在哪里,都可以继续你的开发工作。(@ 小互 AI)
02 有态度的观点
1、Anthropic 顶级提示工程师访谈:如何有效引导和控制大语言模型?
Anthropic 的一些提示工程专家——Amanda Askell(对齐微调)、Alex Albert(开发人员关系)、David Hershey(应用人工智能)和 Zack Witten(即时工程)——反思了提示工程的发展历程、实用技巧和想法随着人工智能能力的增长,提示可能会发生怎样的变化。
工程师们强调了「prompt engineering」,即通过与模型进行反复试验和迭代,设计有效的提示或指令来引导模型输出符合预期的结果。这类似于一个工程师不断试错的过程,旨在找到最佳解决方案。
「与模型的交流更像是与一个人的交谈,需要理解模型的心理以及它如何处理信息。这种沟通方式对于确保模型理解我们的意图至关重要。」
讨论还触及到是否应该向模型隐瞒真实意图或任务复杂性的问题。大多数观点认为,在构建评估数据集或指导模型执行特定任务时,诚实披露相关信息是更好的做法。为了帮助模型更好地理解和应对特定类型的信息,提供清晰且多样化的示例被视为关键策略。这些示例不仅能反映模型将遇到的真实世界情况,还能促使模型学习更广泛的推理能力。
通过询问模型为什么做出某种决策,试图解码模型的内部工作原理成为一种重要方法。这不仅有助于理解模型是如何运作的,还有助于识别哪些方面需要改进。
视频最后,讨论聚焦于未来,预测会有更多的交互式、个性化的提示技术出现,使用户能够更有效地与模型合作,共同完成任务。此次交流展示了如何通过精心设计的提示、真诚的交流方式及有效的示例,引导人工智能模型执行复杂的任务,并逐步提高其性能和普适性。(@ 雷锋网)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻