
现在,似乎所有的商用设备都在使用或尝试使用语音识别技术。从跨平台语音助手到转录服务和无障碍工具,再到最近的 LLMs- 听写功能已成为日常的用户界面。预计从 2023 年到 2028 年,语音用户界面 (VUI) 的市场规模将以 23.39% 的复合年增长率增长,我们可以预期会有更多技术先行的公司采用这种技术。但是,您对这项技术了解多少呢?
首先,让我们对实现语音识别的最常见技术进行剖析和定义。
语音识别的原理:它是如何工作的?
特征提取
在进行任何 “识别 “之前,机器必须将我们产生的声波转换成它们能够理解的格式。这一过程称为预处理和特征提取。最常见的两种特征提取技术是梅尔 - 频率倒频谱系数(MFCC)和感知线性预测系数(PLP)。
梅尔频率倒频谱系数(MFCCs)
MFCC 可捕捉音频信号的功率谱,从根本上识别出每种声音的独特之处。该技术首先会放大高频,以平衡信号并使其更加清晰。
然后,信号会被分成 20 至 40 毫秒的短帧或声音片段。然后对这些帧进行分析,以了解其频率成分。
通过应用一系列模仿人耳感知音频方式的滤波器,MFCC 可捕捉语音信号的关键、可识别特征。最后一步是将这些特征转换成声学模型可以使用的数据格式。
感知线性预测 (PLP) 系数
PLP 系数旨在尽可能模拟人类听觉系统的反应。与 MFCC 类似,PLP 对声音频率进行过滤,以模拟人耳。
经过滤波后,动态范围–样本的 “响度 “范围–被压缩,以反映我们的听觉对各种音量的不同反应。
在最后一步,PLP 估算 “频谱包络”,这是捕捉语音信号最基本特征的一种方法。这一过程提高了语音识别系统的可靠性,尤其是在嘈杂的环境中。
声学建模
声学建模是语音识别系统的核心。它形成了音频信号(声音)和语音单位(构成语言的不同声音)之间的统计关系。
最广泛使用的技术包括隐马尔可夫模型(HMM)和最近的深度神经网络(DNN)。
隐马尔可夫模型(HMM)
自 20 世纪 60 年代末以来,HMM 一直是模式识别工程的基石。由于 HMM 将口语分解成更小、更易于管理的部分(即音素),因此对语音处理特别有效。
提取的每个音素都与 HMM 中的一个状态相关联,模型计算从一个状态过渡到另一个状态的概率。
这种概率方法使系统能够从声音信号中推断出单词,即使在存在噪音和不同个体语音差异的情况下也是如此。
深度神经网络(DNN)
近年来,随着人工智能和机器学习的发展和人们对它们的兴趣日益浓厚,DNN 已成为自然语言处理(NLP)的首选。与依赖预定义状态和转换的 HMM 不同,DNN 直接从数据中学习。DNN 由多层相互连接的神经元组成,可逐步提取数据的高层表示。
通过关注上下文以及某些单词和声音之间的关系,DNN 可以捕捉语音中更为复杂的模式。
因此,与 HMM 相比,它们在准确性和鲁棒性方面表现得更好,而且还能通过额外的训练来适应口音、方言和说话风格–这在一个多语言日益普及的世界中是一个巨大的优势。
展望未来:挑战与创新
语音识别技术已经取得了长足的进步,但任何用户都会认识到,它还远未达到完美的程度。背景噪音、多人讲话、口音和延迟都是尚未解决的难题。
随着工程师们逐渐认识到网络模型的潜力,一种很有前途的创新是使用混合解决方案,充分利用 HMM 和 DNN 的优势。扩展人工智能研究的另一个好处是跨领域应用深度学习,传统上用于图像分析的卷积神经网络(CNN)在语音处理方面取得了可喜的成果。另一个令人兴奋的发展是迁移学习的使用,在迁移学习中,在大型数据集上训练的模型可以通过相对较小的伴生数据集针对特定任务和语言进行微调。
这就减少了为新应用开发高性能语音识别所需的时间和资源,从而以更环保的方式进行重复模型部署。
如何找到语音识别 API
幂简集成是国内领先的API 集成管理平台,专注于为开发者提供全面、高效、易用的 API 集成解决方案。幂简API 平台提供了多种维度发现 API 的功能:通过关键词搜索’ 语音识别 API’、从 API Hub 分类浏览 API AI 语音 - 语音识别、从 开放平台 分类浏览企业间接寻找 API 等。
语音识别 API 替代品
将一切融为一体:实际应用
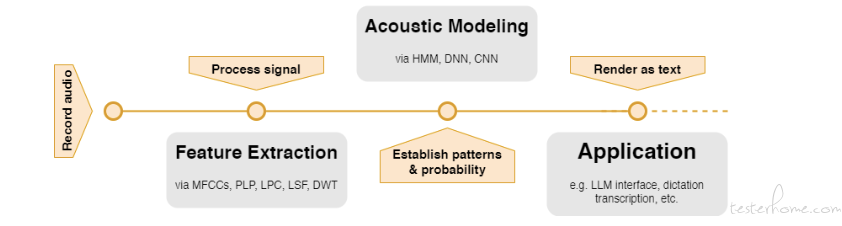
概括地说,特征提取和声学建模相互配合,形成了所谓的语音识别系统。这一过程首先是通过预处理和特征识别将声波转换为可管理的数据。
然后将这些数据点或特征输入声学模型,由声学模型进行解释并将输入转换成文本。在此基础上,其他应用程序就可以随时使用语音输入。
从最嘈杂、对时间最敏感的环境,如汽车界面,到个人设备上的无障碍替代品,我们正逐步信任这项技术,让它发挥更多关键功能。
作为一个深入参与改进这项技术的人,我认为了解这些机制不仅仅是学术性的,还应该激励技术人员欣赏这些工具,以及它们在改善用户体验的无障碍性、可用性和效率方面的潜力。
随着 VUI 越来越多地与大型语言模型(LLM )联系在一起,工程师和设计师应该熟悉这种可能成为生成式人工智能实际应用中最常见的界面。
原文链接:https://wpadmin.explinks.com/blog/an-inside-look-at-speech-recognition-algorithms/