以下文章来源于 XR 交互技术观察 ,作者 Eis4TY
前面的话:
推荐一篇来自 Rokid 产品经理 Eis4TY 的文章。文章探讨了眼手交互技术的原理、应用现状以及未来的发展趋势。作者提出:「在 XR 设备上,眼手交互不是最终答案,而是多模态混合交互的起点。」
也推荐你关注 Eis4TY 出品的「XR 交互技术观察」公众号,精选&解读巨头公司每周公开的 XR 人机交互相关专利。
Enjoy reading!
眼手交互能定义下一代人机交互范式吗?
作者:Eis4TY
随着科技的迅猛发展,人机交互方式正经历着前所未有的变革。从最初的键盘、鼠标到触摸屏,再到现在的语音识别、手势识别,每一次技术的跃迁都极大地提升了用户体验,拓宽了人与机器的交流边界。在众多创新技术中,眼手交互凭借其直观、自然的特点,正逐渐成为行业关注的焦点。
作为一家专注于人机交互技术的产品平台公司,Rokid 始终关注人机交互领域的前沿动态。近期,苹果公司在眼手交互技术方面的探索引起了业界的广泛关注。这一技术的出现,不仅为我们提供了全新的交互方式,更对未来人机交互范式的发展产生了深远的影响。
本文将深入探讨眼手交互技术的原理、应用现状以及未来的发展趋势。同时,我们也将分析眼手交互在这一领域的探索成果,并结合行业实际探讨其能否定义下一个人机交互范式。需要强调的是,本文旨在技术探讨,不涉及任何产品之间的比较和评价。我们希望通过本文,能够为广大用户带来有价值的信息和思考。
01 眼手交互, 完美的输入方式?
眼手交互被作为了 Apple Vision Pro 的基础交互方式。第一波使用过的人,也都对这种提升效率的新交互方式感到惊讶。尤其是对于那些之前没有接触过 XR 设备的用户来说,眼手交互无疑是一种全新的体验。而这种交互方式之所以高效,主要得益于以下几个方面:
1、焦点导航与注意力绑定:眼手交互将焦点导航和用户的注意力绑定,省去了移动控件使光标瞄准目标的步骤。
2、光标导航与操作分离:通过分离光标导航和操作指令,减少了手部的运动,降低了长时间使用的疲劳感。
3、避免空间海森堡效应 (Heisenberg Effect of Spatial Interaction):在传统的射线交互中,用户在确认操作时手部的微小抖动可能会导致射线偏移,而眼手交互有效避免了这一问题。
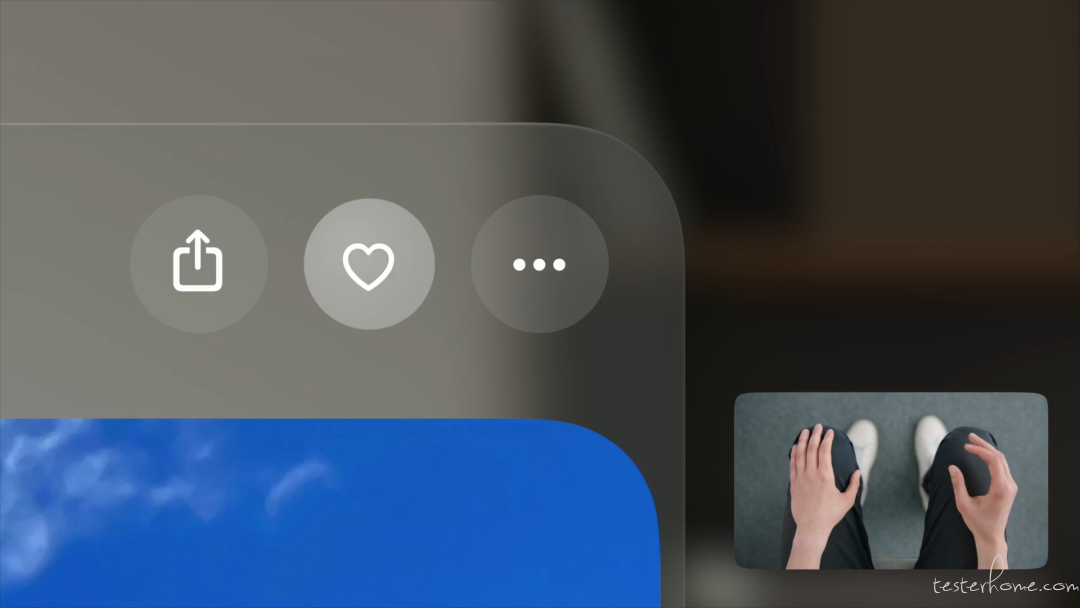
眼手交互
https://developer.apple.com/design/human-interface-guidelines/gestures
Vision Pro 眼手交互方案的大多数性能指标都令人感到满意,但是在移动拖拽物体时会有点累,因为需要活动肘关节,调动小臂和部分大臂的肌肉。相比之下,Quest 的手柄方案只需要用到手腕和手指。在 SIGCHI 2024 会议上,META 也展示了一篇用微手势代替物理摇杆的方案,就像用大拇指刷手机,几乎不会产生疲劳。
Vision Pro 暂时没有使用这种方案的原因可能是优先考虑更符合直觉的方式,尽量降低新用户的学习成本,毕竟眼手交互还不是我们的习惯。
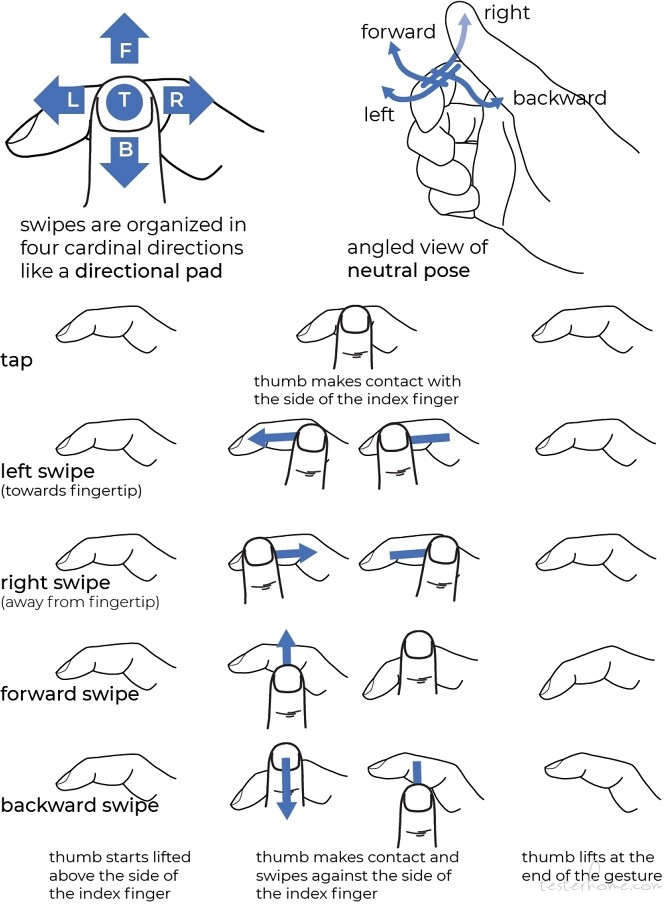
STMG 微手势集由针对食指桡侧执行的拇指动作组成。它们包括拇指点击和向左、向右、向前和向后四个方向的滑动。
眼动交互方面的专家 Ken Pfeuffer 在今年 2 月,也就是 Vision Pro 正式发售前,在 Arxiv 和 Medium 上发表了一篇论文,简短总结了他们团队过去的研究,也提出了眼手交互的设计原则和面临的挑战。
(参考链接:
https://medium.com/antaeus-ar/design-principles-issues-for-gaze-and-pinch-interaction-a95e251169ae)
随着 Vision Pro 的热度下降,行业里也出现了一些对苹果眼手交互质疑的声音。那么,这次苹果还能复制一次「多点触控」式的成功?能再次引领和定义新一代人机交互范式吗?
可以确定的是,眼手交互无法像多点触控之于手机那样覆盖设备的所有使用场景,甚至打字等最基础的交互体验都不能算顺畅。所以 Vision Pro 引入了手部直接交互作为代偿,好在对于用户来说,切换两种交互模式的方法足够直观好用。

手部近场交互
让我们来总结一下眼手交互目前遇到的挑战:
1、学习成本:眼手交互作为一种全新的交互方式,与以往的交互习惯截然不同,用户需要投入时间学习如何有效使用。
2、鲁棒性问题:眼手交互的精确度有待提高,目前误触的可能性较大。用户可能在不经意间将拇指靠近食指,而被系统误识别为操作指令。而在弱光环境或摄像头看不到的区域,又容易识别不到。
3、交互动作的局限性:目前支持的交互动作单一,仅支持由捏合动作(pinch)拓展的基本手势。
4、触觉反馈单一:现有的触觉反馈主要来自于用户自身的手部动作(指尖捏合时的触感),缺乏更丰富的触感体验。
5、眼手协调性:在执行捏合等动作之前,用户的注视点可能已经转移到下一个目标上,尤其是在进行打字等需要快速连续操作的任务时非常明显。一项对书法专家和新手在书写过程中的眼动路径研究发现,专家在书写时的注视点始终领先于笔尖的位置,这表明在熟练的技能操作中,视觉注意力的分配是高度策略性的。
那么是否存在更好的方法或设备可以解决这些问题,成为 XR 设备完美的输入方式?
02 手表、手环、戒指, 潜在的明星外设
未来最先可能接入 XR 系统的新外设是「手表/手环」类产品,业界各大厂商已经在此领域深耕多年,也展示过许多使用 demo。目前,技术方案主要分为两大流派:一是以苹果和 Double Point 为代表的 IMU 派,另一是以 Meta 为代表的 EMG 派。手表的优势在于不仅可以用于手势识别,同时也具备日常生活中的实用功能,如健康监测、消息提醒等。

Apple watch(左),META EMG 手环(右)
另一个被受瞩目的形态是「戒指/指环」。戒指可以更精准细致地识别用户手指末端的微手势,使用方式可以更省力,也能有效避免误触。
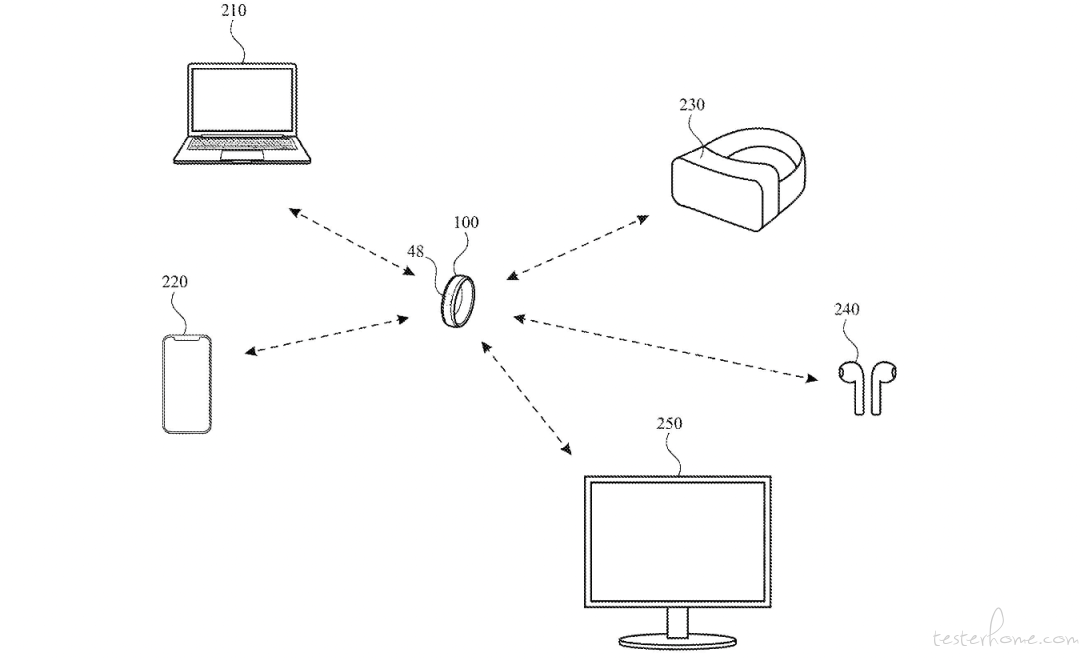
US20230350503A1
相比苹果目前的方案,手表和戒指这两类外设不用依赖摄像头。可以识别更多更细致的微手势,从而减少疲劳,提高输入效率和准确度。
但是在全天候的佩戴使用环境下,还是免不了会有误触的发生。比如在另一台电脑上打字时可能不小心触发手表的点击功能,或者在吃水果时误触戒指,造成不必要的干扰。此外,仅凭单一外设,还无法彻底解决文字输入的效率问题。
也有些人会期待更加激进的方式,比如通过脑机接口实现的意念输入。这种输入方式虽然能够实现低疲劳和低延迟,但这类设备能在多大程度上读取我们的思想,这点始终存疑。

迈向眼 - 脑-计算机接口:将凝视与刺激前的消极性相结合,以实现 XR 中的目标选择 doi.org/10.1145/3613904.3641925
考虑到电池续航、重量、体积等综合因素,目前还没有出现一种能够完美解决输入问题的理想外设。
现在让我们回到第一性原理。
人机交互的核心是让计算机快速准确的识别用户意图并提供反馈。
我们在操作设备时会面对两个心理鸿沟:一个是执行的鸿沟,我们首先需要清楚如何操作;另一个是评估的鸿沟,我们需要清楚操作的结果。
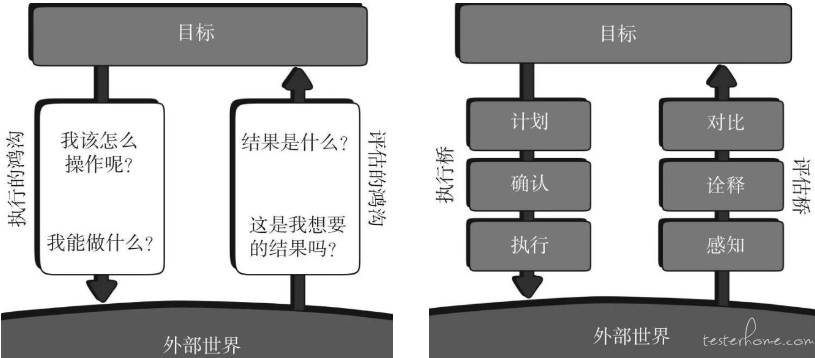
执行和评估的鸿沟
要弥合这两个鸿沟,关键在于建立双向的理解和一致性。就像专业的骑手与他的马能够心意相通,能够理解,甚至预测对方的每一个动作。
然而,我们普通人并不想深入了解计算机和系统的工作原理,也不愿意学习如何使用复杂的外设。所以压力就给到计算机这边,它需要更准确的识别用户意图,或者说更「智能」。
在缺乏用户明确输入指令的情况下,计算机只能尝试通过「排除法」来猜测用户的意图。但由于信息不足,计算机往往难以做出正确的判断,「误触」就这样发生了。
那么,如果给计算机提供更多的信息,是否就能增强其理解能力,从而更准确地识别用户意图呢?
香农将信息定义为「不确定性的减少」。在信息论中,信息熵表示系统的初始不确定性。通过提供更多的用户数据,计算机能够减少对用户意图的条件熵,增加互信息,从而更准确地识别用户意图,提升系统的理解能力。更多的信息能够显著降低系统的不确定性,使得计算机对用户行为的预测更加精确。
但这也要求计算机系统具备强大的数据处理能力和先进的算法,以应对复杂的信息。
03 人机交互离不开 多模态交互方式
多模态交互(Multimodal Interaction)是指在人机交互过程中,同时使用多种感官和输入方式进行交流和控制的技术。这种交互方式模仿了人类在自然环境中的交流方式,因为人类在交流时会同时使用视觉、听觉、触觉、手势等多种感官和行为。
Vision Pro 的眼手交互就是一个典型的多模态交互方式。眼手交互起源于 1981 MIT Media Lab 的一项多模态交互研究。Ken Pfeuffer 在他的博客里介绍了眼手交互的发展历史。
(参考链接:
https://medium.com/@ken.pfeuffer/history-of-eyes-and-hands-for-computer-control-fd3a62b56aa1)
我们灵活的双手除了用来「pinch」还可以传达更多的信息,比如手语。在多种文化中,人们在交谈时通常会伴随丰富的肢体动作,这不仅有助于消除语言交流中的歧义,也能增强系统对用户意图的理解。特别是在识别用户情绪和压力水平方面,肢体语言提供了重要的线索。

《奇美拉 La Chimera》(2023)剧照
Yuhan Luo 等人的研究发现,人们使用手势表达情感时,手指指向方向和手势强度与情感的情感和兴奋水平有关。这表明手势不仅是情感表达的工具,也是情感强度的指标。此外,他们的研究还指出,手势的使用受到社会和文化背景的影响,这说明在设计多模态交互系统时,需要考虑不同文化背景下用户的手势习惯。
(参考链接:
https://dl.acm.org/doi/10.1145/3613904.3642255)
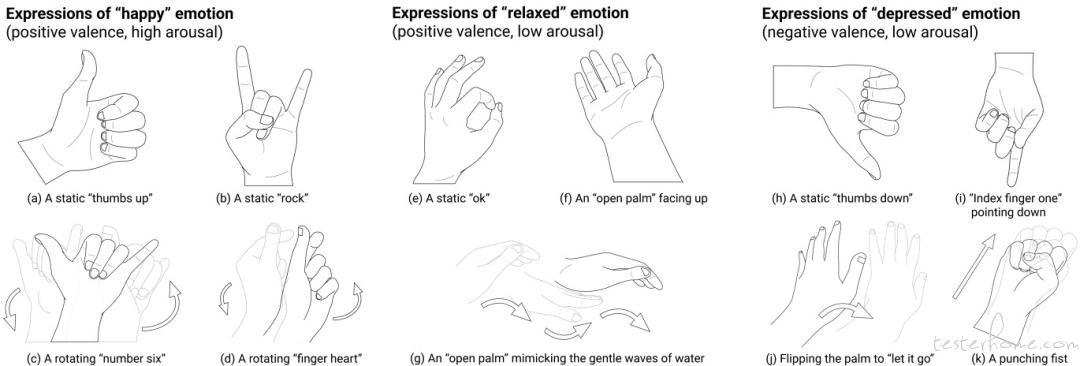
单手手势的表达潜力:一种情绪可以通过不同的手指方向、手掌方向、动作和力量来表达不同的方式。
除了眼手,在 Vision OS 中,用户还可以结合视觉和听觉模态进行交互。例如,在某些输入框中,用户可以通过注视选择文本框,然后使用语音输入文字,有效地结合了视觉的定位功能和语音的快捷输入。
Ismo Rakkolainen 等人曾系统的总结了针对基于 XR 设备的多模态交互技术,并对基于人类感官的模态接口进行了分类。
(参考链接:
https://www.mdpi.com/2414-4088/5/12/81)
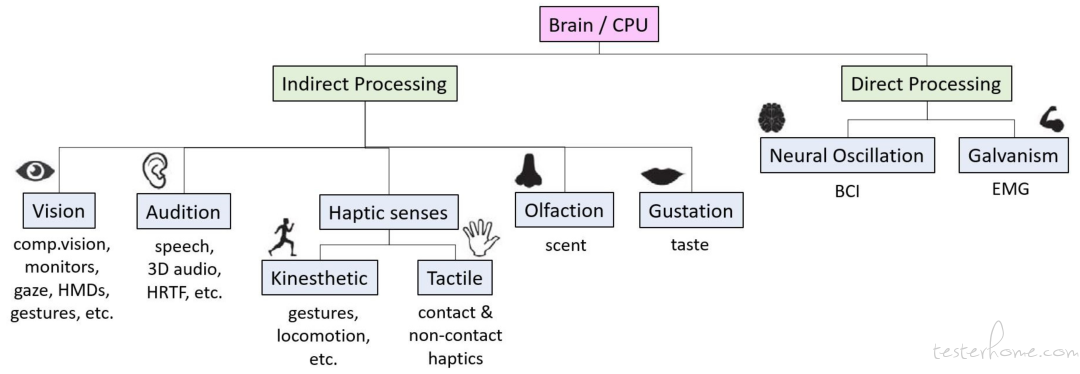
恰巧 XR 设备的一大特色就是支持集成丰富的传感器,且这些传感器距离我们自身的五官很近。
增加了输入源,计算机能获取的信息量就能增加许多,多个通道的联合输入就可以让计算机做 "排除法" 的时候正确率更高。
Jaewook Lee 等人在 SIGCHI 2024 会议上发表的 GazePointAR 多模态交互技术利用眼睛注视、指向手势和对话历史记录来消除语音查询的歧义。用户可以通过注视或指向来提问。如下图,当用户询问「这是什么?」时,GazePointAR 会自动将「这」替换为「带有 Orion Pocachip Original 文字的包装物品」,然后将其发送到大型语言模型进行处理和响应。处理后的结果会由文本转语音引擎读取,并以语音形式回答用户的问题。
(参考链接:
https://dl.acm.org/doi/10.1145/3613904.3642230)

与 GazePointAR 交互的示例
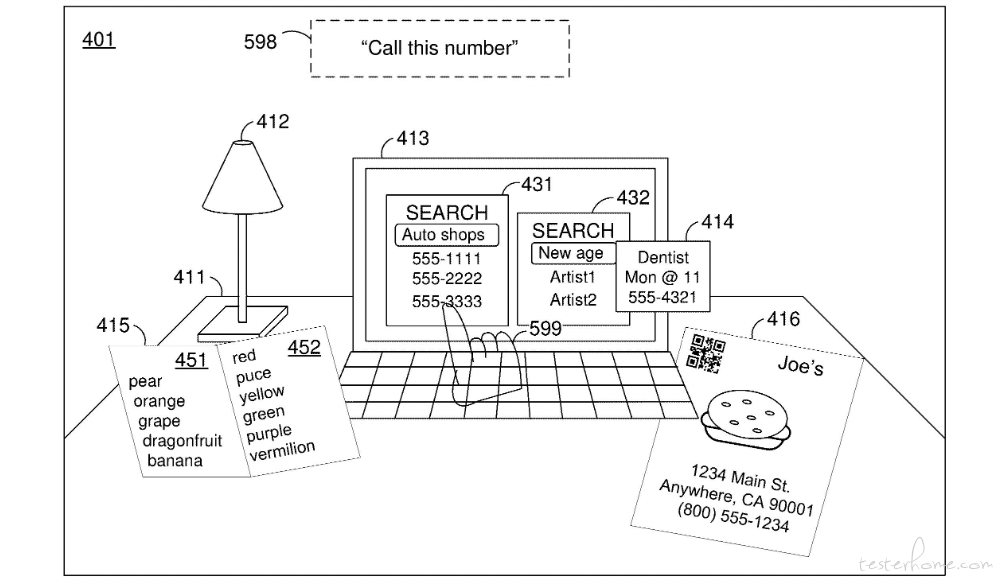
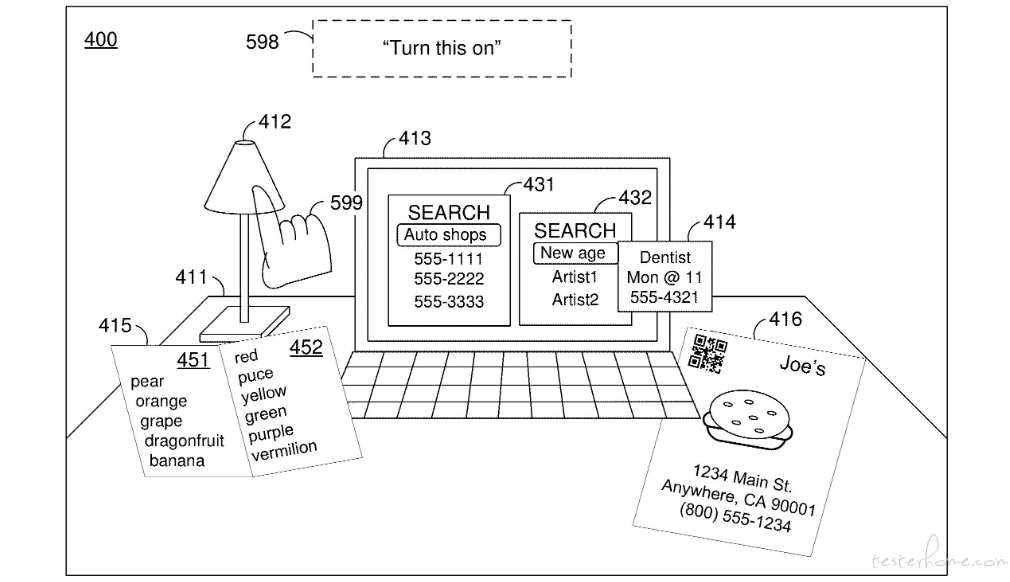
苹果也在其专利 US20230409122A1《基于手势控制的智能设备操作技术》中描述了一项技术,允许用户通过特定的手势和语音命令与智能设备进行交互。例如,当用户指向一个电话号码并说出「呼叫这个号码」,如下图,系统会识别手势指向的对象和语音命令,然后自动拨打电话。也可以控制台灯的开关,或者调节亮度。
在完成相同任务时,如果用户可以使用多模态输入,控制会更加灵活。每种模态都有其独特的特性和优势,Vijay Rajanna 等人在一项打字输入研究中发现,眼睛并不能像传统的焦点导航器(如鼠标)那样长时间稳定地保持在一点上。长时间刻意的控制眼睛盯着一个地方会很快导致疲惫。所以眼动只能用来做焦点导航,而其他比如单击、激活等操作则需要额外的控制方式。多模态可以在执行任务时形成优势的互补。眼动和手势的组合输入时,就可以完全放松的将手放在腿上或自然下垂。
04 多模态交互, 可灵活切换是关键
在实际使用时,多模态的灵活切换同样重要。Vision Pro 目前提供的远近场交互模式的切换也是个很好的例子,它允许用户根据任务的需要和环境的变化,直观的选择合适的交互方式。
Rokid 自研的 AR 空间操作系统 YodaOS-Master 则支持 3 种焦点导航交互方式 (手部追踪近场交互、射线远场交互和 Touchpad 光标间接交互)。在不同的使用场景下,用户可以根据需要灵活切换。比如在游戏中使用射线可以提供最快速度的灵活响应。而在使用 2D 应用办公时,Touchpad 光标能提供更稳定和精确的操作体验,也更符合我们在电脑上办公的操作习惯。
然而,多模态交互有时也会增加用户的认知负荷。例如,组织语言进行说话是一个非常消耗大脑资源的活动,许多人在说话时不得不暂停手头上的其他工作,无法一心多用。这可能是由于大脑用于说话和聆听的部分也是用于解决问题的部分。
(参考链接:
https://dl.acm.org/doi/fullHtml/10.1145/348941.348990)
这也可能是语音输入迟迟没有流行的原因之一。
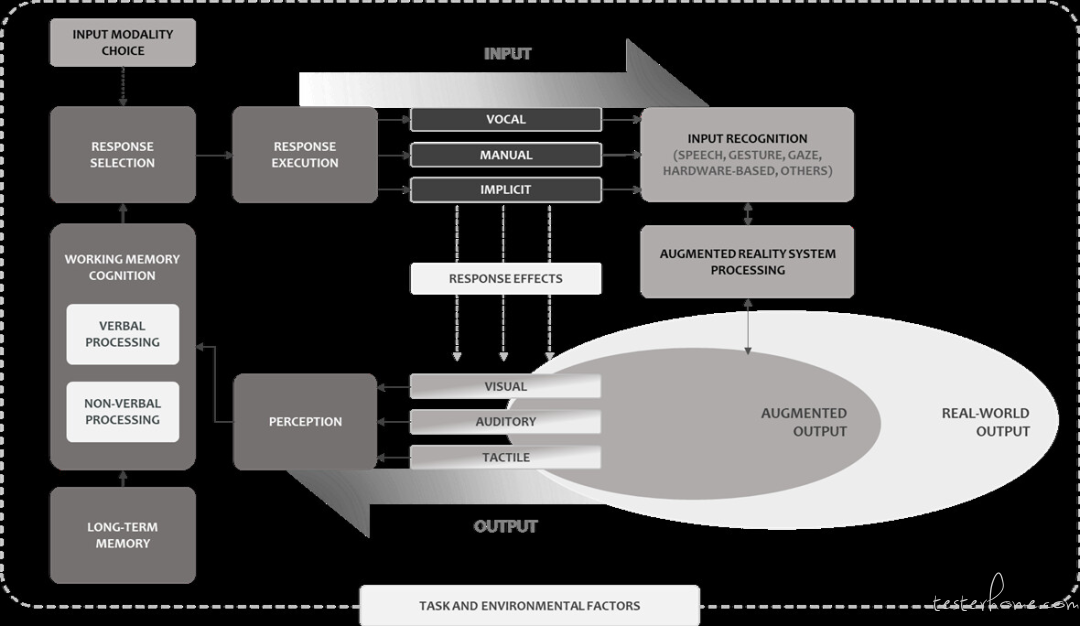
AR 中 MMI 的拟议框架
所以多模态交互的复杂度非常高。为了方便系统性的研究,韩国 CX Insight Team 的研究人员提出了一个在 AR 环境中的多模态交互框架,该框架考虑了人类信息处理的各个阶段,以及输入和输出模态如何协同工作。研究还强调了组合不同的交互模态可能对任务效率和用户性能产生的影响,并讨论了如何在 AR 系统设计中实施这些理论。
(参考链接:
https://dl.acm.org/doi/10.1145/3613905.3650874#d1e597)
以上的案例主要用到了视觉、听觉和运动觉模态。但多模态交互并不仅限于此,XR 设备不仅能通过传感器建立与我们自身的连接,还可以建立与我们所处的环境之间的连接。
通过传感器实时采集环境音、摄像头等环境数据。从而理解用户当前所处的环境和用户的需求、行为和情感。从而更好的和用户「对齐」,提供更好的服务和反馈。比如 Google IO 2024 上发布的 Astra,宣传片中女主问 Astra 她的眼镜放在哪了,Astra 就通过回溯刚才摄像头扫过的影像,告诉女主她的眼镜放在桌角。

谷歌 AI:Project Astra 宣传演示
在苹果的专利 US20240005921A1《基于环境上下文的语音命令识别系统》也描述了这类使用场景:在智能家居设备中,用户的语音命令可能存在多种解释,比如家里可能有多个智能灯具,当用户说「关灯」时,系统是无法确定用户要关哪个灯的。但如果系统可以获取环境上下文信息,当用户在卧室发出「关灯」命令,系统就能将模糊的指令识别为关闭卧室的灯。
05 如需必要,勿增实体
触觉反馈则对于提高用户操作时自信很重要,尤其是在执行精细操作时。但我们不想随身携带一堆需要充电的外设。如果能随手拿起身边的物体临时当作有形控制器(Tangible User Interfaces)就太好了。这类「万物皆备于我」的概念被称为机会型界面。
机会型界面 (Oportunistic interface) 机会型是指主动发掘环境中的各种机会 (比如物体、资源等),并将其临时转化为交互的媒介或方式,提高系统对环境的响应性。
META 研究团队曾提出 ATUI:自适应可触用户界面(Adaptive Tangible User Interfaces)的愿景:不需要专门设计的硬件,而是通过识别环境中的物体及其特征,将这些物体临时转化为输入设备或控制器,从而为用户提供触觉反馈和物理操作感。比如我想旋转 3D 模型,只需用手旋转附近的杯子即可。

ATUI 示例
Camille Dupré 等人也在 SIGCHI 2024 会议上展示了他们的 TriPad 技术,仅通过手部跟踪将任意普通表面转化为触控板,其工作原理是通过 3 个指尖与表面接触来创建平面。之后,用户可以随意使用这个表面进行触摸输入。

(1) 所有手指都停留在目标表面上:在拇指、中指和小指定义的平面上出现一个灰色圆圈。(2-3) 通过整只手进行快速点击,创建触摸平面。(4) 表面现在可以用于触摸输入。
这样都是很好的尝试。进一步想,我们也可以在空白的桌子上创建一个任意大小的虚拟键盘,虽然没有键程,但桌子的表面可以在打字时给手指敲击时的反馈。
06 XR 设备的发展与挑战
虽然目前我们在多模态交互领域的研究和应用仍然非常早期。但近年来 AI 技术的井喷,让多模态交互技术站在了一个充满无限可能的新起点上。比如 AI 大模型的流式视频流输入这样的 "科幻电影技术" 也在前些天由 openAI 和 Google 同时实现了。
AI 的进步极大地推动了对来自不同模态的复杂数据的理解和处理能力,为多模态交互系统的设计和实现提供了强有力的技术支撑。
所以眼手交互最多只是 "版本答案",在多模交互的路上不会止步于此。以目前 AI 进化的速度,甚至我们可能很快就能走到 Licklider 所畅想的那个未来:
迈向自然、共生的关系 我的梦想是在不久的将来,人脑和电脑能密切协作,进行人脑想象不到的思考。
——李克莱德(J.C.R.Licklider),「人与电脑共生理论」(Man-Computer Symbiosis),1960
然而,在技术进步的另外一面,我们也不能忽视隐私和安全方面的挑战。
多模态交互系统需要实时采集和分析大量用户的个人数据,包括语音、面部表情、眼动轨迹以及环境影像等敏感信息。
随着计算机系统变得更加智能化,它们对用户意图的解读能力也在不断提高。然而,这种智能化也需要是可控的。如果系统过度解读用户意图,可能会引起用户的不适或误解,甚至导致信任危机,就像 HAL 9000 或 MOSS 的故事。因此,在设计多模态交互系统时,设计者也要充分考虑用户的接受程度和舒适度,避免系统对用户行为的过度干预或控制。
总的来说,在 XR 设备上,眼手交互不是最终答案,而是多模态混合交互的起点。
