混沌工程 前端自动化混沌测试实践
- 综合编译|TesterHome 社区
- 作者|Joaquim Verges
- 来源|Twitch Engineering
本文为亚马逊旗下流媒体平台 Twitch 工程师 Joaquim Verges 的技术经验总结分享,供大家参考。
以下为作者观点:
作为前端开发人员,我们并不经常听说混沌测试(注:作者当时的语境)。一个与 Twitch 前端可用性相关的项目,让我们开始研究由 Netflix 首创的令人兴奋的混沌工程领域。
混沌工程(Chaos engineering)是一门通过模拟故障并测量这些故障对系统的影响来优化软件系统弹性的科学。这些模拟有助于在实际问题发生之前对其进行预测,并确保我们的系统能够正常降级。这种做法通常用于后端和分布式系统,并且该领域正在开发越来越多的工具。
然而,在前端,我们还没有观察到来自网络或移动社区的太多讨论或活动,以确保我们的客户具有应有的弹性。
我们的最终目标是能够回答这个问题:“如果我们整个系统的这一部分(例如后端服务、第三方 API)出现故障,我们的前端会如何表现以及我们的最终用户会看到什么?”
模拟系统故障
在 Twitch,我们的数据由不断增长的相互依赖的微服务集合(在撰写本文时有数百个)提供服务。这些服务通过单个 GraphQL API 从我们的前端客户端(网站、移动应用程序、控制台应用程序、桌面)中抽象出来。
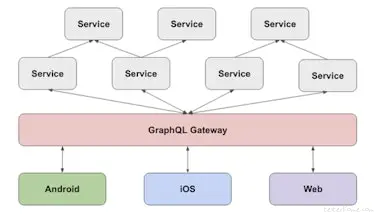
在像我们这样的系统中发生的最常见的故障是我们的微服务错误之一并且无法提供其部分数据。在这种情况下,如果配置正确,GraphQL 可以很好地将部分数据转发到客户端。从那里开始,客户端的工作就是处理这部分数据并提供尽可能最佳的降级体验。
考虑到这个常见的用例,我们的目标是找到一种可扩展的方法来测试这些场景并观察每个客户端的行为。
让混沌工程开始吧!首先,我们需要一种可靠地模拟故障的方法。
第一个考虑的选项是拦截并更改收到的网络响应。混沌拦截器(chaos interceptor)将添加在 GraphQL 响应中注入错误的能力。这些错误可以是预先确定的,也可以是随机注入的。
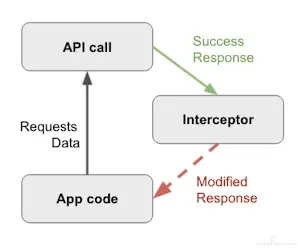

在探索此选项时,我们意识到,由于绝大多数 API 调用都通过 GraphQL,因此我们可能会通过 GraphQL 调用传递特殊指令,以模拟 GraphQL 解析器端的某些故障。幸运的是,事实证明这一功能已经在我们的一个黑客周期间实现,并恰当地命名为 “混沌模式”。
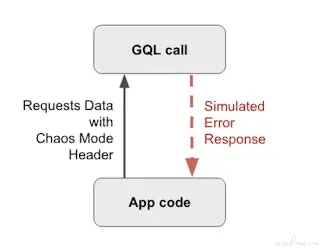
混沌模式添加了向我们的暂存 GraphQL 调用传递额外标头的功能。在该标头中,我们可以传递我们希望模拟故障的一个或多个服务的名称。我们的临时 GraphQL 解析器读取此标头并短路对这些服务的任何内部调用。

自动混沌测试
一旦我们找到了模拟故障的方法,下一步就是使该过程自动化。在 Twitch,我们大量使用自动化来测试我们的前端用户流程。这些脚本化测试,可以模拟用户操作我们的网站或应用程序,验证一切是否按预期显示。
我们意识到,通过使用特殊的混沌模式标头集运行我们的核心测试,可以非常容易地实现故障模拟自动化。这种设置可以告诉我们特定的服务故障是否会破坏这些核心流程,这已经非常接近我们的目标了!
在 Android 上运行快速原型后,我们发现缺少一些东西来使其可扩展:
由于功能和服务会随着时间的推移而变化,因此我们的测试套件需要一种方法来 “发现” 我们应该强制失败的服务。手动映射不可维护且无法很好地扩展。
看到测试结果是一个很好的开始,但我们应该能够从这些运行中提取更多有用的信息。例如哪个服务导致了故障、哪些特定的 API 调用受到了影响,甚至还包括用于可视化用户体验的故障屏幕截图。
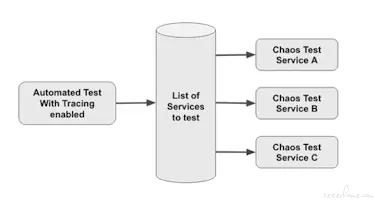
为了解决第一点,我们需要一种方法来 “跟踪” 来自客户端的 GraphQL 调用并记录特定用户流访问了哪些内部服务。我们通过在 GraphQL 调用中使用另一个调试标头(debug header)解决了这个问题,该标头支持在 GraphQL 解析器层进行跟踪。然后,解析器记录对其内部服务依赖项执行的任何方法调用,并在同一 GraphQL 调用中将信息发送回客户端。从那里,客户端可以提取一组 GraphQL 调用中涉及的服务名称,并将其用作混沌测试套件的输入。
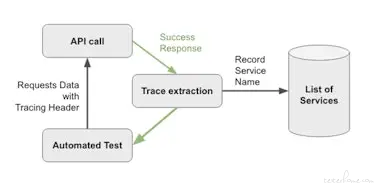
我们现在有一个两步过程:
在启用跟踪的情况下运行端到端测试,并记录每个测试涉及的所有服务。
使用此服务列表,我们可以通过强制每个服务一一失败来运行混沌模式测试。
通过此设置,我们现在拥有一种自动方式来发现服务,然后强制它们以一致、可重现的方式失败。然后我们可以将其扩展到任意数量的自动化测试。
仪表板和可视化
有了这个系统,我们继续提取并记录有趣的信息,这些信息将描述这些强制故障期间的用户体验。
我们使用运行 n 次(每次服务故障一次)的单个用户流(即导航到屏幕/页面、观看流、发送聊天消息等)的测试结果,并使用它们来计算弹性分数对于那个特定的测试。一个简单的百分比数字,表示尽管持续出现服务故障,但用户流成功的次数。然后为客户计算全局弹性分数,从而高度概述每个客户对故障的敏感程度。
我们可以使用这些分数来跟踪用户流随时间变化的弹性,衡量我们对代码所做的改进,并确保我们不会意外倒退。我们将这些分数和其他有用信息打包并上传到服务器,以便我们可以在网络仪表板中将其可视化。
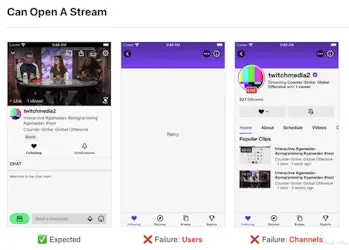
在测试过程中,我们捕获 API 调用,提取有用的信息,例如哪个特定 GraphQL 有错误、该查询中的哪个字段导致了错误,并且我们还捕获了预期状态和错误状态的屏幕截图。所有这些信息都有助于诊断给定故障下客户端到底发生了什么。
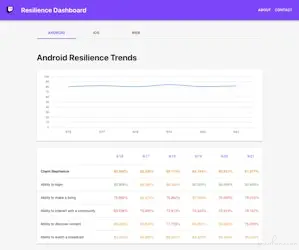
使用此仪表板,我们发现 Android 和 iOS 弹性分数之间存在很大差距。
Android 的总体得分为 82%,而 iOS 的得分仅为 64%。使用提供的调试信息,iOS 团队确定了根本原因:对网络堆栈深处的 GraphQL 错误的过度防御性处理。该团队能够通过重新运行自动化混沌测试来测试他们的修复,并验证该修复显着提高了弹性,将 iOS 弹性得分提高到 84%。
下一步
现在,我们每天晚上在 Android、iOS 和 Web 客户端上运行这个工具。这使我们能够深入了解当前前端对后端服务故障的恢复能力。我们现在可以跟踪我们的弹性分数如何随时间变化,并轻松测试过去难以测试的故障场景。
我们计划通过在我们的自动化测试中添加更多超出核心流程的用户流程来扩大覆盖范围。在系统中添加新测试就像为平台编写任何自动化测试一样简单,我们目前正在努力添加移动网络作为目标平台之一。
我们还计划改进混沌模式和跟踪服务调用的能力,以解决当前的限制。最高优先级是跟踪和失败辅助服务调用(服务到服务交互)的能力。我们正在考虑的其他功能是能够使单个服务调用失败以及同时使多个服务失败。
混沌工程的学科可能是为后端分布式系统建立的,但感觉前端还有很多东西需要探索!令人惊奇的是,这些工具将来自不同领域的工程师聚集在一起,进行协作,并使他们能够更深入地了解我们的系统端到端。(原文链接:https://blog.twitch.tv/en/2022/01/10/automated-chaos-testing-on-the-front-end/)