二、使用了 BERT 模型和指代消解算法:
加入 BERT 语言预处理模型,获取到高质量动态词向量。
融入指代消解算法,根据指代词找出符合要求的子串/短语。
【2】融入指代消解算法,根据指代词找出符合要求的子串/短语
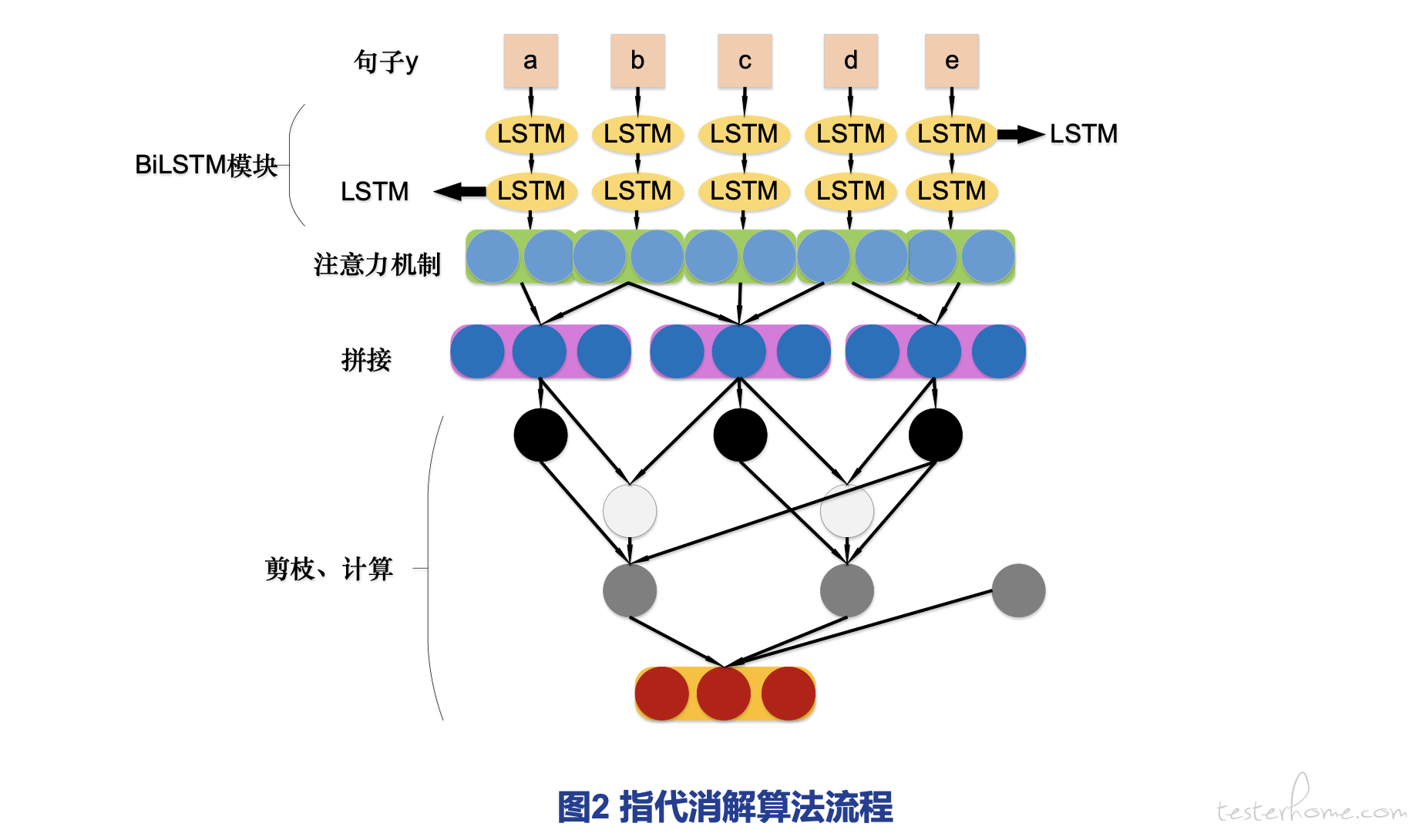
指代消解算法如图 2 所示,简单来说,就是考虑文档中子串/短语以及学习子串/短语的可能指代。通过分词器将句子 y 分割为 a~e 五个字,将其作为输入传给模型中的 BiLSTM 模块,然后提取实体识别所需的特征,进行注意力机制任务,将得到的结果进行拼接、剪枝处理,得到可能性最大的指代的子串/短语,进而优化目标。
这里的指代消解算法是在使用启发式 Max-Margin 损失函数的基础上,利用增强策略梯度算法工作的。每个行为 a=(c,m) 的概率定义如公式 (1) 所示, 损失函数定义如公式 (2) 所示。


为使获得奖励值最大,采用梯度上升法进行参数更新,由于梯度值计算困难,现采用一种梯度估值,定义如公式 (3)、(4),进行原文替换。
调研发现,此处可以引入一个语义匹配层及网页语义知识,来弥补知识库不全覆盖的问题。在此基础上,本文找到一种基于小文本的 BERT-NER 的中文指代消解框架,它可以获得更高的准确率和更好的效果,同时实现主语补齐的功能,功能实现如图 3 所示。
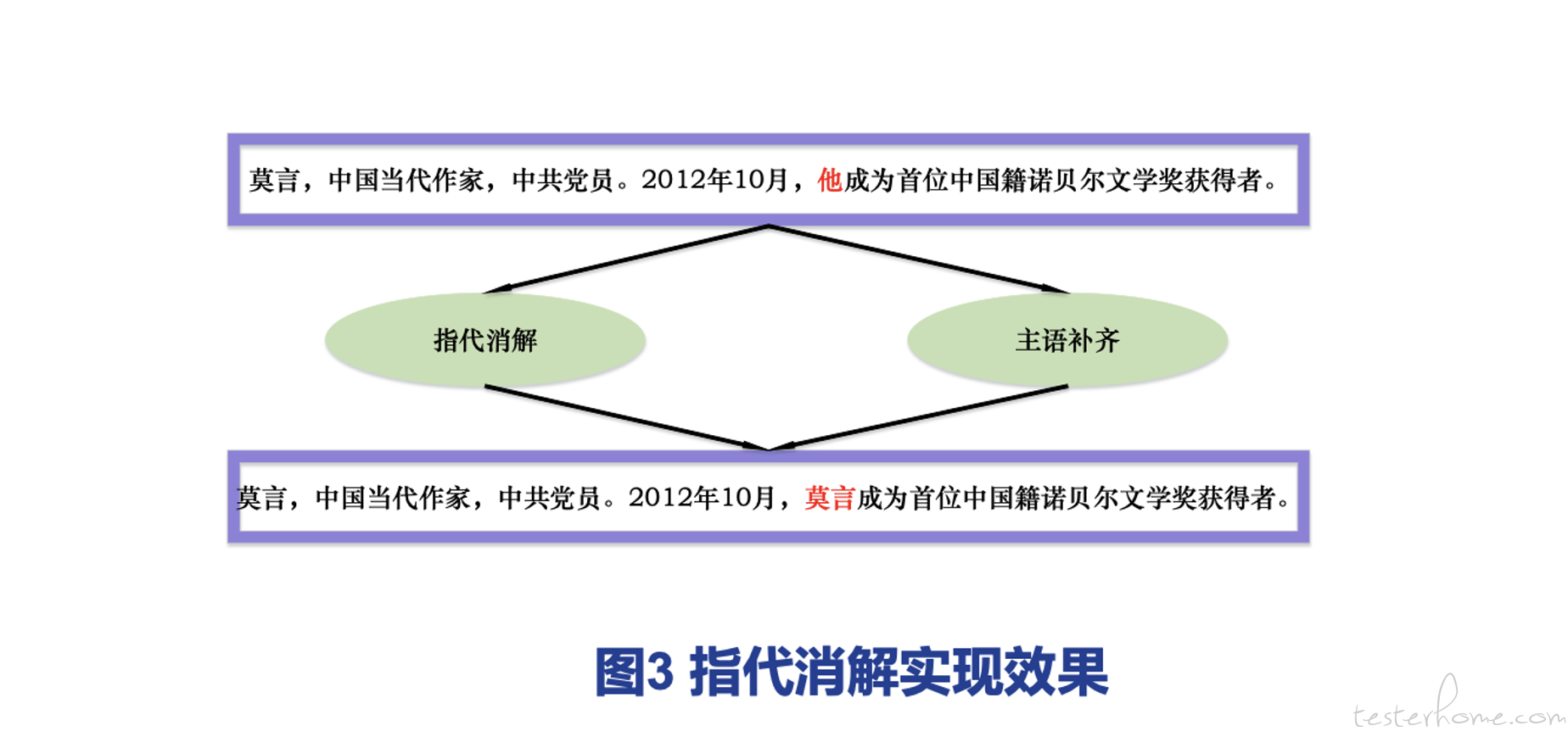
由于数据中包含人名指代词的文本在海量数据中占比较少,所以本文可进行小文本的模型训练。加入指代消解算法后,将消解前后的舆情公告数据文本进行比较,测验效果见图 4。

【3】融入的指代消解算法,比加入外部语料和字符级特征更通用有效
当下与本文类似的提高人名识别效率的研究中,多特征 BiLSTM-CRF 模型(后续简写为多特征模型)识别方法具有代表性,该模型改善了影评中称谓不明等问题,在电影行业上取得了显著效果。
本文为了体现融合指代消解的序列标注方法更胜一筹,利用人民日报数据集和上市公告数据集,比较融合指代消解的序列标注的方法和加入外部人名语料和特定字符级特征的序列标注的方法,得出融入指代消解的人名识别方法要比加入外部人名语料和特定字符级特征的模型的效果更好。
所以在一般情况下,融合指代消解的序列标注方法会比其他形式,诸如加入外部人名语料和特定字符级特征的序列标注方法更能改进人名识别的准确率。
在公共数据集和舆情公告数据集上,融合指代消解的序列标注方法和加入外部人名语料和特定字符级特征方法的比较,前者效果更好。
总结
本文提出的融合指代消解序列标注方法,在以下四个方面有较强的创新性
数据预处理阶段,根据职务变更等有效信息进行数据增强
加入 BERT 语言预处理模型,获取到高质量动态词向量
融入指代消解算法,根据指代词找出符合要求的子串/短语
融入的指代消解算法,比加入外部语料和字符级特征更通用有效
该算法未来将拓展至机构名、地名以及其他所有以名称为标识的实体,能更好的服务于京东小程序客户体验中的寄收件地址的文本识别中,提高相关识别的准确率。