背景
百川专项是指物流统一打造企业级能力平台,战略上聚焦纯配、仓配类业务主线,以提升前台业务整体交付吞吐率为核心目标,支撑物流开放领域解决方案和标准产品的快速交付实施。计划以 “百川” 专项项目为契机,加速推动 BP 团队将 ECLP 中各自业务的单据和履约职能整理下沉到订单中心和各自业务的履约层中,以实现业务闭环。业务系统交互图如下:
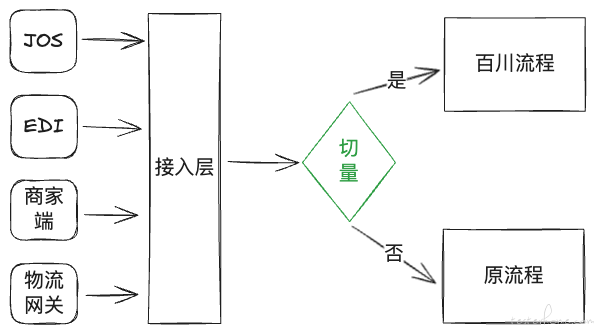
图中绿色部分就是判断是否切量,从交互可以看出是否走百川完全取决于切量结果的判断。那么如何精准灵活的控制流量成为切量系统的关键。
下面让我们随着切量接口的发展引出一些遇到问题,并在最后的设计中给出解答。
小树刚发芽
针对仓配的架构升级专项重点是重构原有的 eclp-isv、eclp-so、eclp-bd 等系统,将原来职责混乱、代码难以维护的老系统,分成接入层、订单中心、履约层三层结构。各系统职责分明、流程清晰,且在各层支持不同业务的横向扩展。这里好处就不在这里班门弄斧了。说回老系统,eclp-isv 作为之前的接单入口,承接了多种业务的仓配接单场景。在针对这个入口的切量过程中,目前是以中小件业务作为先头部队打造三层标准能力,也是 2022 年切量的重点。所以,针对中小件业务,需要专项上上下下逐步赋能,逐步切量。
切量初始阶段,项目组能看清的是我想要什么流量,比如第一次切量,产品和研发确定其中一个事业部的单子百川可以承接。所以只需要按照事业部白名单切量就可以了。下面展示从 ISV 下单时切量判断的系统交互时序图。
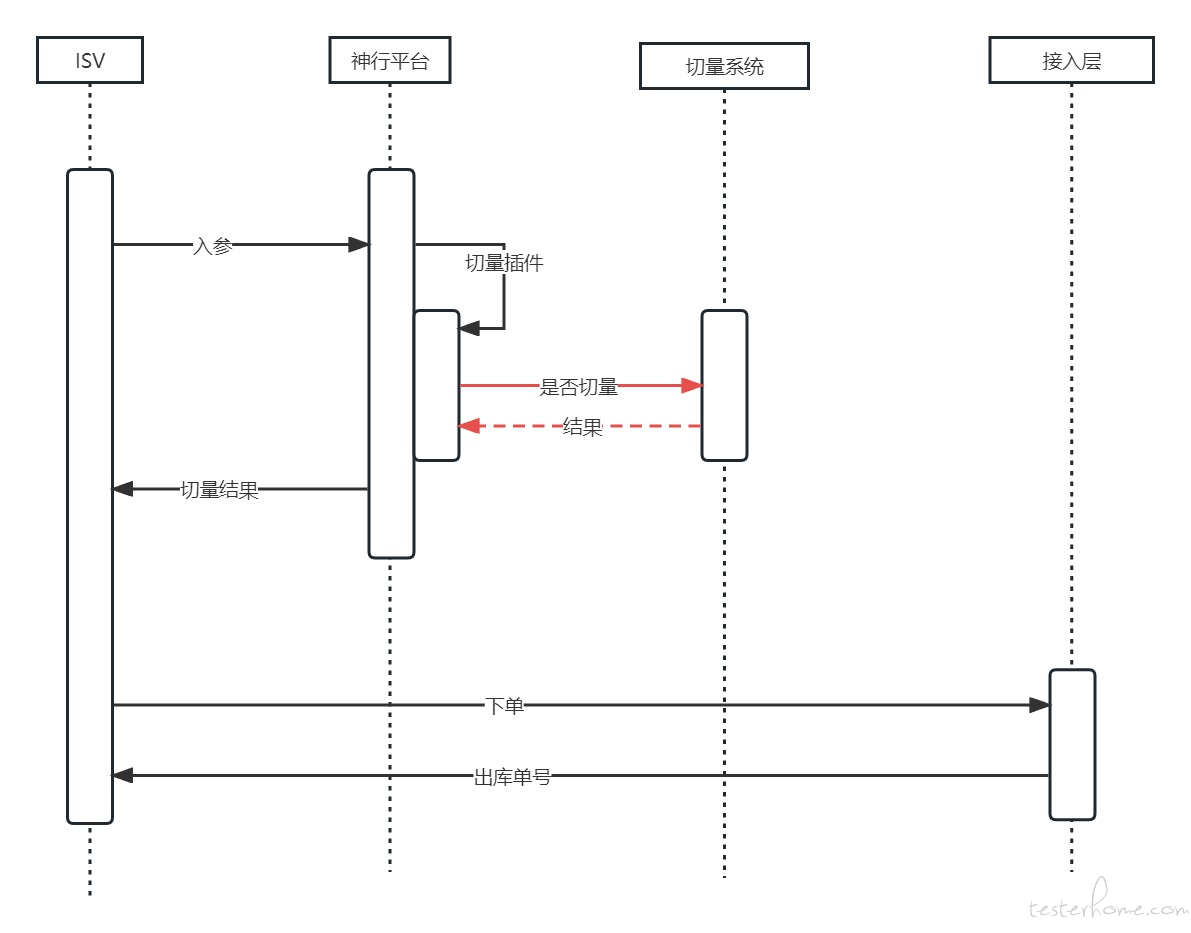
PS: 这里使用到的神行平台作为切量配置平台,感兴趣的可以了解下。图中红色部分就是切量接口交互过程。接口定义其实很简单,就是传入下单参数,返回布尔值。
快速成长
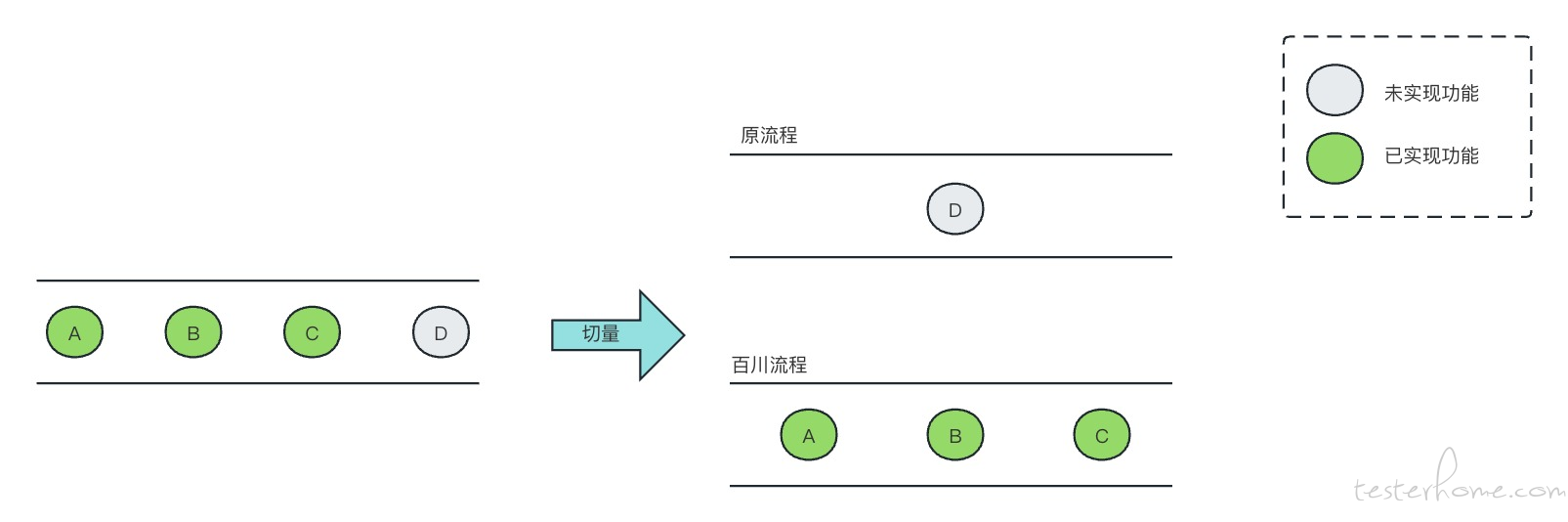
随着标准能力不断完善,事业部切入的越来越多。也带来新的问题,单量较大的事业部可能覆盖的功能较多,如上图的 A、B、C、D 四个功能项。有的能力具备(图中绿色部分),而个别能力还在补齐中(图中灰色部分)。怎么切量才能筛选出我们可以承接的量呢?
很容易想到就是在切量接口里加规则,根据下单参数中某个标位或某几个参数组合去剔除那些明确接收不了的量,让它们走原流程下单。就这样不断迭代中,切量接口中从一个事业部白名单判断到几十种规则匹配,接口的代码量也膨胀到上千行。
程序迭代的过程中,必然会带来的维护成本提高。而作为流量入口,规则可能是几天一更新,也可能是一天更新好几次。如何在一个方法上千行里做到一天几次迭代,且要保证没有问题。一旦出问题,将承接不了的流量引入,三层可能就需要花费一周甚至数周时间去修复,相信所有人都会头疼。
随着切量进展更加深入,对于功能的开发周期经过了逻辑梳理、产品规划、开发、测试、AB 比对、uat 验证、上线。为了保证上线的切量平稳,就需要线上灰度验证,但是百川是多层结构,从上到下都搭建起灰度环境工作量较大,如何进行灰度,既能较少工作量又能保证稳定呢?
开枝散叶
2023 年专项的目标已经从中小件业务扩展到大件、冷链、国际等业务线全面接入百川,而接单的入口都是 eclp-isv,也就是所有业务公用一个切量接口。中小件切量积累的切量规则肯定跟其他业务线切量规则会冲突,如何将切量接口进行重构才能支持多业务线不同的切量规则呢?
上面提到的背景都是基于线上环境的。还有个不可忽视的重要手段,那就是 AB 环境。专项通常投入大量的人力物力在 AB 比对,就是为了保证在人工无法梳理到场景,通过 AB 环境录制线上流量的方式进行比对,反向输出需求,进而达到功能全覆盖。
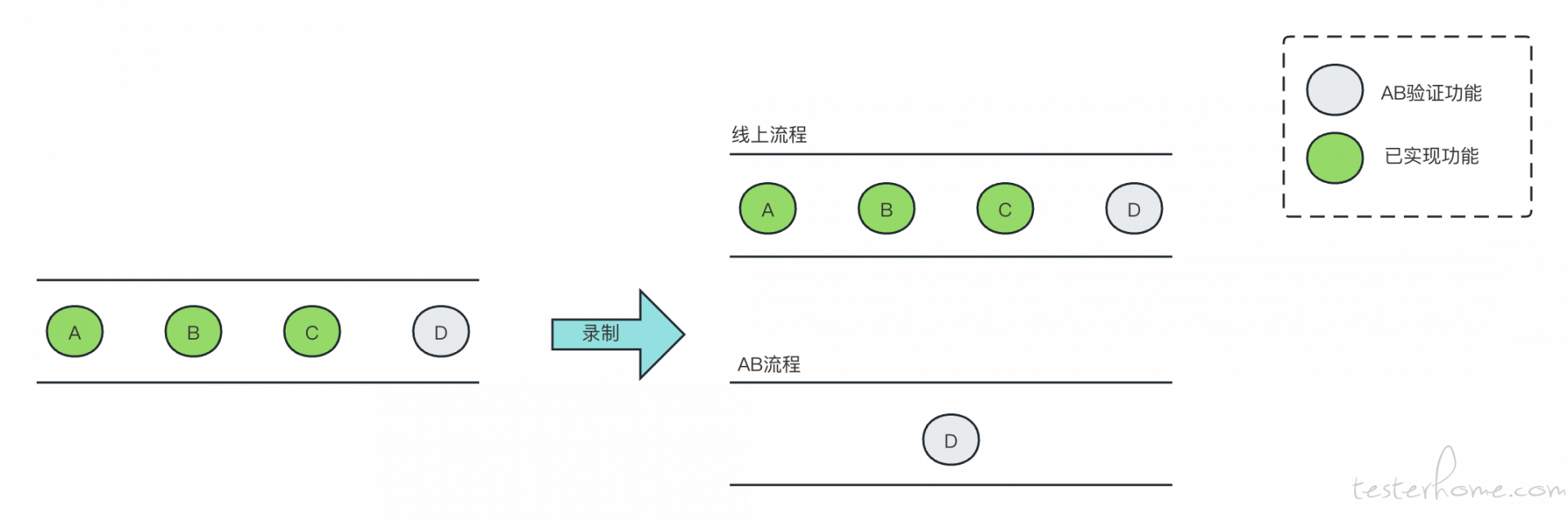
AB 环境需要的流量本质上是以线上规则为基础,删除或修改某一个规则,组合成完整的 AB 录制规则。例如上图中 D 流量的录制。
AB 录制规则有以下几个特征:
•基于线上规则,只有部分改动
•更新频率比线上规则更加频繁
•每次规则调整到线上同步改动周期不确定,可能 1 天也可能一两周甚至一两个月。
基于以上的特点,那么我们改如何设计 AB 录制规则合理呢,毕竟 AB 分支和线上分支切量方法有一千多行,合并起来总让人头疼。
梳理
说了这么多背景,相信大家对一个小小的切量接口是如何成长,又面临那些困境有了一些了解。那么审题之后,我们来梳理下有哪些痛点。
•单方法内容过多,难以维护
•方法在不同环境单独实现逻辑,合并分支困难
•切量方法不支持横向扩展,多业务线无法做到规则隔离
•新功能切到百川缺少灰度验证
设计
我一直相信:针对痛点做出的设计才是合理的。
那么针对上诉的痛点,我们一一思考如何通过设计来解决。
单方法内容过多
从根本上来看方法的职责,就是通过下单入参来匹配一串规则,规则都满足就进行切量,否则不切量。那么内容过多就需要进行拆分。将大方法拆成一个个小方法,依次执行,任意规则不匹配就中断。这里最关键的是如何拆分合理。那就要看方法内容的核心,在观察和整理所有规则后,提炼出了场景的概念。可以将所有规则按相似含义归类成一个个场景,比如事业部、承运商、加密、合同物流等等。这样用场景命名每个规则,做到直观清晰且语义明确,每个规则都高内聚低耦合。
下面就是定义每个切量规则的接口如下:
public interface RuleMatchPoint {
/**
* 切量规则
* @param shuntContext 下单报文上下文
* @return 切量规则结果
*/
boolean match(ShuntContext shuntContext);
}
然后通过责任链模式依次串联起所有切量规则,通常最简单的方式就是利用 Spring 框架自动将 RuleMatchPoint 接口注入到一个 List 中,然后循环调用 match 方法。

PS:这里只是展示,并非全部规则。
不同环境隔离
基于上面分析,AB 环境的录制规则其实就是基于线上切量规则,然后在某个场景做放开流量调整,得到想要的线上流量。而通过场景拆分,切量规则已经不在臃肿,所以合并线上更新只会在某个场景出现代码冲突。所以我们核心解决两个问题:
•怎么复用线上切量规则
•怎么实现 AB 环境个性化切量规则。
这两个问题围绕着解决切量规则的 “复用” 与 “个性化” 问题,那么我们其实就可以将所有规则进行细分:
1.线上切量规则(个性)
2.AB 切量规则(个性)
3.通用规则(复用)
而不同环境就用所属的个性规则 + 通用规则组成完整的切量规则集合。
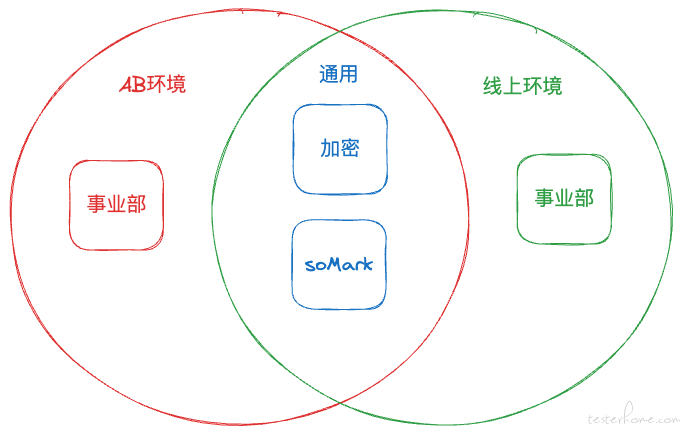
而实现方案 Spring 提供的@Profile注解可以完美支持,这里需要额外约定将 AB 环境的规则类命名要加 AB 前缀,与线上规则类区分开。
不支持多业务线规则隔离
目前切量工作分为系统入口和业务两种维度,其实有些业务还包含标准和 KA 更细力度。这里就大范围划分如下图。
ISV
POP
中小件
ISV 中小件切量规则
POP 中小件规则
冷链
ISV 冷链切量规则
POP 冷链切量规则
PS:横向为接单系统入口维度,纵向为业务维度。
我们约定一个名词:业务身份,业务身份=入口 + 业务。那么一个业务身份对应一套切量规则,就类似一个业务身份对应一个流程编排。要做到根据业务隔离就要针对不同的业务身份定制不同的切量规则,说简单就是给切量规则打标。
根据上面的表我们定义两种维度的注解:
@ISV
ISV 中小件切量规则
POP 中小件规则
ISV 冷链切量规则
POP 冷链切量规则
不同业务身份所属的规则集合就找满足注解的切量规则即可。例如想要执行 ISV 中小件切量规则就找所有带有@ISV+@Small的 RuleMatchPoint 接口集合。
当流量从某种切量入口进入后就需要经历两个过程。
1.业务身份确认,如何确认需要业务测提供规则。
2.使用属于当前业务身份的切量规则集合去判断是否切量。
按照这两点,业务切量模板就定义成:
public interface ShuntStrategy {
/**
* 业务身份匹配
* @param shuntContext 切量上下文
* @return 业务身份是否匹配 true-匹配 false-不匹配
*/
boolean businessIdentityMatch(ShuntContext shuntContext);
/**
* 业务规则匹配
* @param shuntContext 切量上下文
* @return 业务规则是否匹配 true-匹配 false-不匹配
*/
boolean businessRuleMatch(ShuntContext shuntContext);
}
抽象出这两个过程后,我们以 ISV 入口为例,其中包含中小件和冷链两个业务,流程如下:
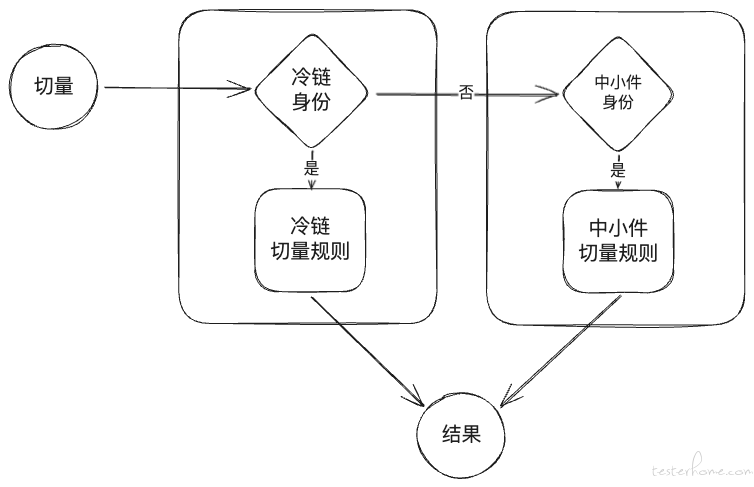
按照这种结构规划后,每个流量只要从某个入口进入后依次进行业务身份判断,直到找到合适业务身份,然后进行规则匹配,最终返回是否切量结果,如果没有匹配的业务身份则不切量。
•如何控制模板顺序?
其实业务模板其实是需要顺序的,顺序的控制可以使用 Spring 框架的@Order注解或 XML 配置都是合理的。至于哪个业务线在前哪个在后就要综合业务流量规模和业务线其他属性共同决定了。
如此设计后,将单一的业务线的规则集合就扩展到支持业务线维度的横向扩展。而且新流程接入和某个业务线切量规则调整不会影响其他业务线。
我们还是设计了切量规则支持扩展功能。这是因为在各个业务线切量周期、节奏都不相同。我们第一步是完成中小件业务承接,所以规则集合写在切量应用中。而冷链、国际等其他业务线,将对应业务的流量是否切量的权限下发给各个业务线。这种权限下放,可以让业务灵活控制切量,而避免多方协同出错或协同延时问题。
缺少灰度验证
这里的灰度验证实际上是指找到线上符合验证条件的流量,控制其中一小部分走到新流程中验证功能正确性,其他流量还走原流程。分析这个需求可以提炼出两点:
1.找到符合条件的流量
2.控制多少量允许进入新流程
找到符合条件流量容易,只要能说出条件就能写出规则。那么功能的重点就在如何实现控制流量,也就是限流。
通常限流采用 redis,设置带有过期时间的 key,获取 key 的值是否超过上限,超过限流,否则自增。这个用于灰度验证的场景也很合适,那么就需要考虑如何定义 key 合理。
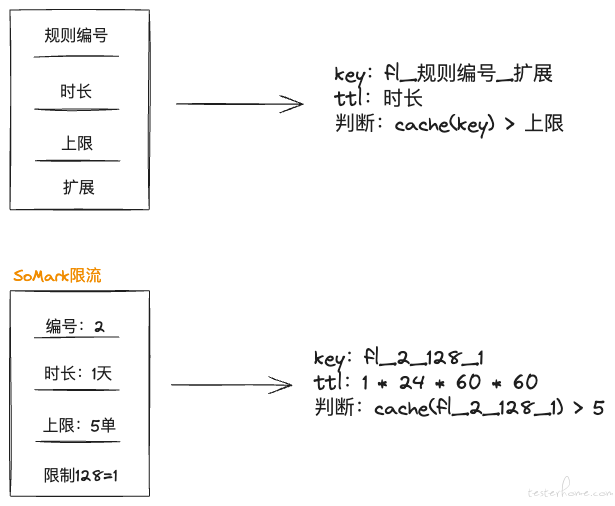
限流配置比较简单,这里就不赘述了。
截止到目前,有实现的限流规则有 30 多个。将所有限流规则打包成一个切量规则,然后集成到切量规则责任链的最后一个节点即可完成限流集成。那么切量规则已经支持按照业务身份分组了,限流规则是否需要也要分组呢?以图中 SoMark 限流为例,无论哪种业务都可能存在 SoMark 限流诉求,只不过限流的配置不同。所以设计要做到逻辑通用、配置根据业务身份独立两点。
•逻辑通用:在切量规则注解中扩展一个@Common注解,每个业务都集成这个注解的切量规则。
•配置独立:当限流读取配置时,根据所属的业务身份取不同的限流配置。
除了上面提到四个痛点的设计之前还有包括幂等设计、数据统计设计等等,篇幅有限就不一一展示了。
全景展示
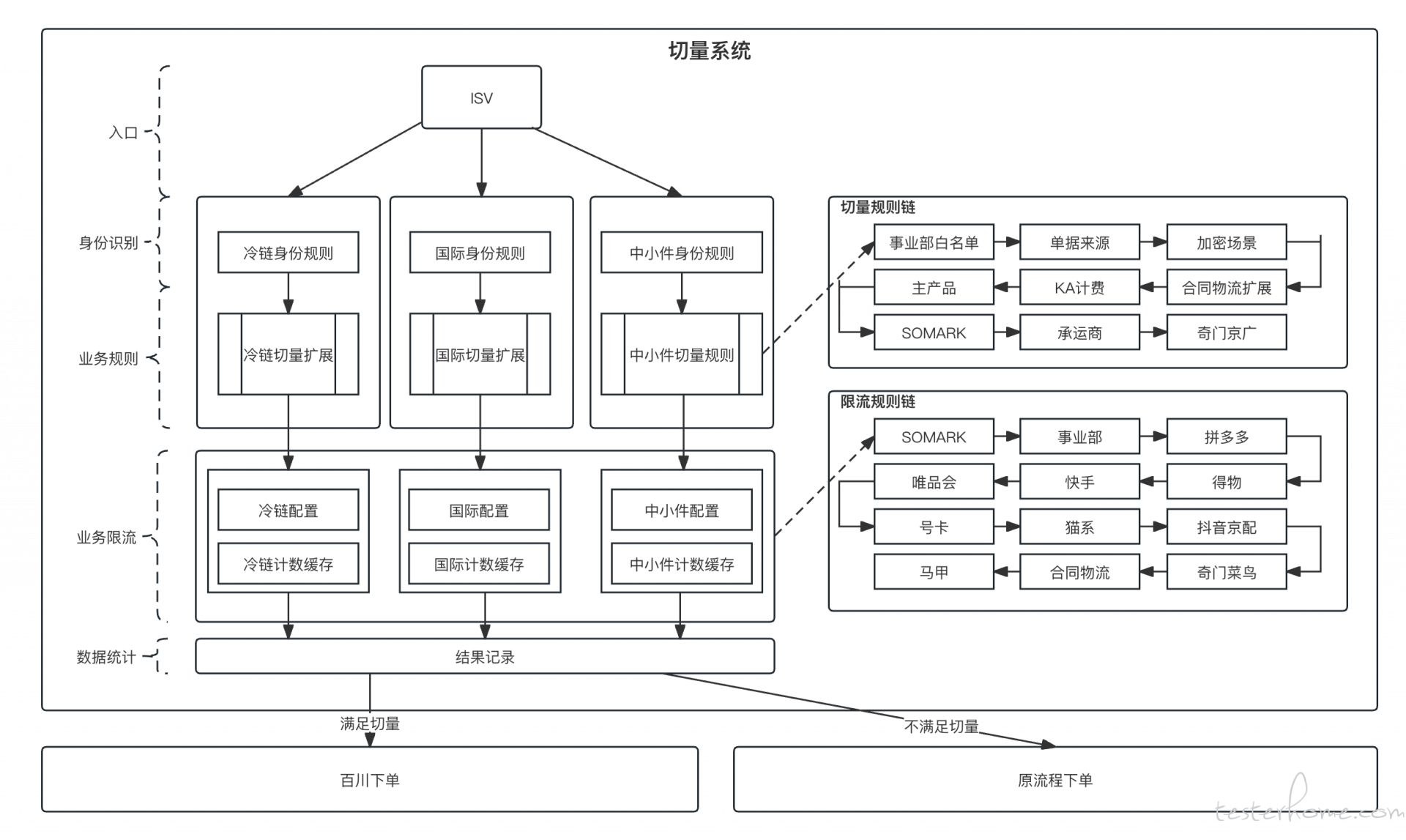
最终落地的结构如下图所示:
总结
从一个小小的接口演变成如此支持业务扩展、入口扩展、环境扩展的 “3D” 接口。也是我从参与专项一路摸爬滚打至今的缩影吧。欢迎大家一起探讨,有考虑不周的也欢迎指出。
其实我觉得,大到系统间规划小到接口重构,相对于重要战略落地、紧急需求上线来说,属于重要不紧急的那一类。但不应该等等再说,而应该未雨绸缪,随机应变。
感谢观看。