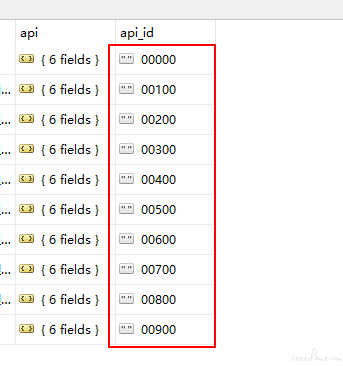
给大家看下我现在的 ID 设计:既是 ID,又是排序的序号。 我的用例因为有前后关联关系,所以得按照顺序从序号小到大执行。 最后加了两位 0,是为了插用例时使用,比如 00100 和 00200 之间新增一条用例的话就是 00150。 总感觉我这样的 ID 设计不够科学,大家是怎么设计的呢?
我想的也不一定科学 将 id 和执行序号分开,执行序号可以修改 或者增加一个下一个执行用例的 id,执行完这个执行下一个
我们的做法:id 使用 bigint 作为主键,由雪花算法生成,提供 order 字段用于排序,初始值 65535,下一个是 2*65535,以此类推,用例调整顺序,新顺序的 order 值=(前一个用例的 order+ 后一个用例的 order)/2,这样在较大的有限次移动顺序内,不会把 order 值耗尽,之后,每晚凌晨三点,对 order 字段重排序,重新按照 65535,2*65535 等等重新排序,以确保给之后的操作留出空间
我这因为测试结果没有入库,所以直接就是 AtomicLong