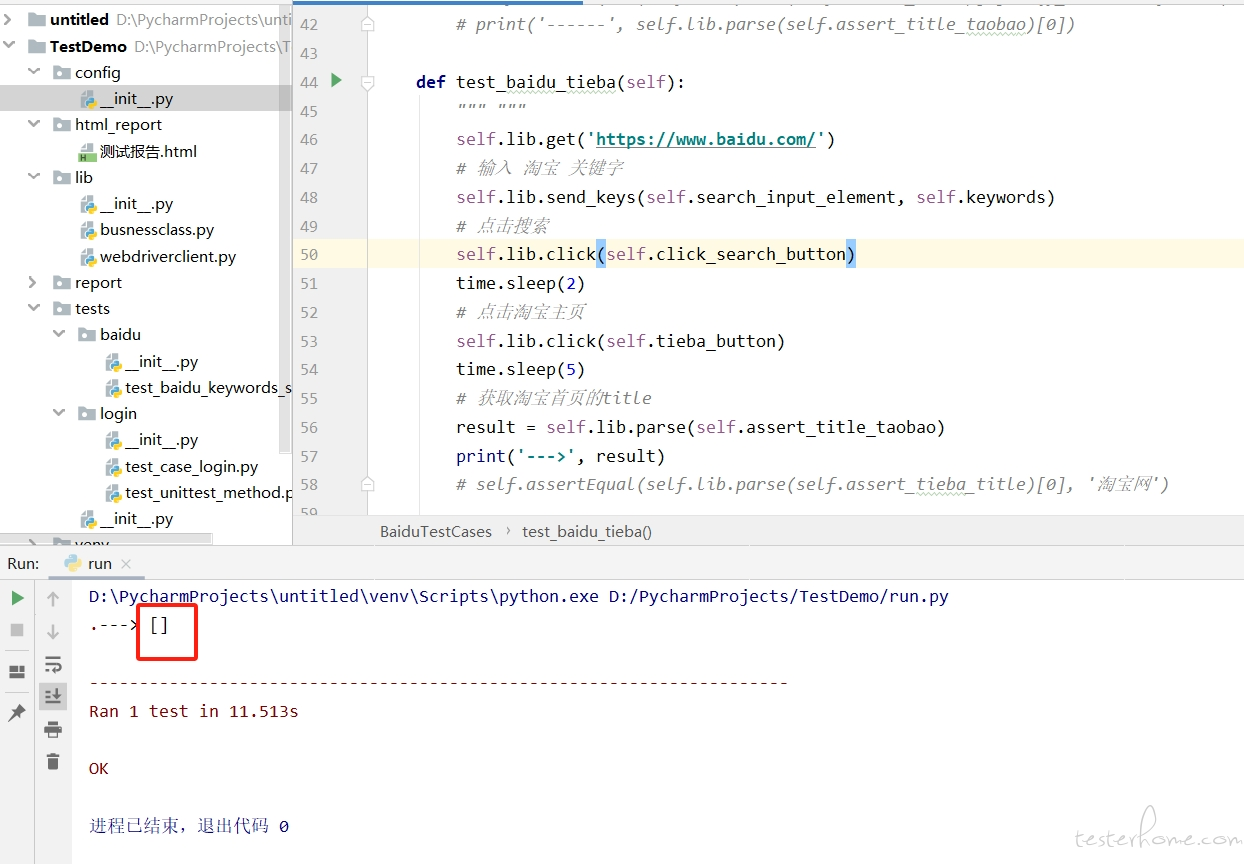
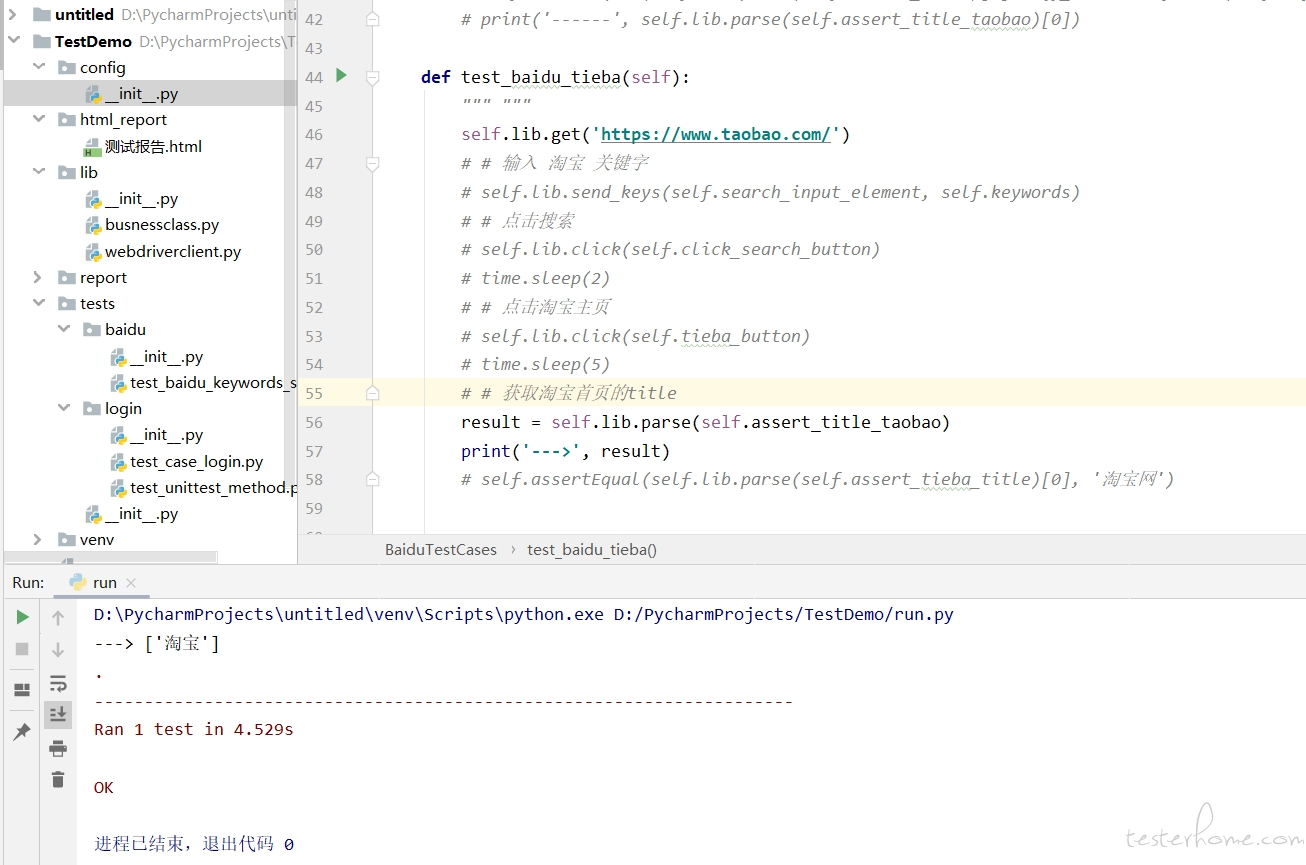
请问大家,为什么直接打开淘宝首页,用 xpath 就可以解析出来数据;而通过百度搜索 “淘宝” 关键字,再点击淘宝首页,打开淘宝首页,就解析不出来数据了呢,都是用的同一个 xpath,其他代码也都是一样的。
搜索和直接进去,域名一样么?页面的 dom 树结构一样么?
域名是一样的,dom 树结构不知道怎么看= =
关注下浏览器的地址栏,URL 是否完全一致?不一致的话,页面可能呈现的也不同。 dom 树可以通过浏览器开发者工具,一般 F12 或者右键菜单可以查看,dom 树相关知识建议还是学一学,要不然写 web 类的 UI 自动化会很痛苦的
你这问题描述略粗糙了,assert title taobao 是怎么写的也需要一并发出来。
感谢大家的热心回答 是没切换窗口句柄的原因,自己粗心了