0.背景
在近期的项目中,系统涉及到针对系统的业务操作日志统计功能,由于本系统位于业务链路的中心环节,负责接收上游系统的数据,并将基于用户操作产生的数据传递至下游系统,鉴于业务链路的复杂性和操作场景的多样性,我们计划通过对核心业务数据进行全生命周期的日志记录来提升问题解决的效率,并为用户提供更多的工具支持。

0.1 收益
业务操作日志给我们带来的收益有哪些呢?区别于传统的系统日志,业务操作日志是软件系统中用于记录和跟踪用户对业务数据执行的操作的日志。这些日志提供了对系统活动的见解,有助于审计、监控、分析和重构业务流程。
1.审计和合规性:
◦审计跟踪: 审计操作日志可以帮助追踪数据的变化历史,了解谁在何时对系统进行了何种操作。
2.安全性:
◦入侵检测: 通过分析操作日志,可以检测到潜在的不当行为或未经授权的访问尝试。
◦事后分析: 在发生安全事件时,操作日志可以用来确定攻击的范围和影响,帮助在未来加强安全性。
3.错误诊断和系统监控:
◦故障排除: 当系统出现故障时,操作日志可以提供关键信息,帮助快速定位和修复问题。
◦性能监控: 日志可以帮助分析系统的性能,如响应时间和资源消耗情况。
4.用户行为分析:
◦业务洞察: 通过分析用户的操作模式,企业可以获得有价值的业务洞察,指导产品改进和市场策略。
◦客户服务: 操作日志可以帮助客服人员了解用户遇到的问题,提供更有针对性的帮助。
5.数据恢复:
◦备份和恢复: 在发生数据丢失或损坏时,操作日志可以辅助数据的恢复工作。
6.业务规则和流程改进:
◦流程优化: 日志数据可以用来分析和优化业务流程,提高效率。
0.2 目标
增强数据的可追踪性和透明度,确保业务流程的顺畅和可监控。系统侧效果最终实现如下:

👉👉👉要解决的核心问题:「谁」在「什么时间」对「什么」做了「什么事」
1.方案 1.0:AOP 切面 + 注解
作为一名对 Spring 重度使用者😎😎,基于上面的需求目标马上想到了基于 AOP 切面 + 注解的传统方案,AOP 切面和注解来设计业务操作日志是一种非常自然和高效的方法,我们基于 AOP 切面和注解的方法来实现我们系统中的业务操作日志记录,这种方案允许我们以最小的侵入性来捕获核心业务操作,并在执行前后自动记录相关数据。通过定义注解,我们可以轻松地标记那些需要记录日志的业务方法。万能的 AOP 一定可以实现!😏
让我们开始编码:👇
1.1 定义日志注解
首先,你需要定义一个或多个注解,用于标记哪些方法需要记录业务操作日志。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Loggable {
String value() default "";
// 可以添加更多的配置属性,如操作类型、级别等
}
1.2 创建 AOP 切面
接下来,创建一个切面类来处理带有@Loggable注解的方法。
@Aspect
@Component
public class LoggingAspect {
@Around("@annotation(loggable)")
public Object logExecutionTime(ProceedingJoinPoint joinPoint, Loggable loggable) throws Throwable {
long start = System.currentTimeMillis();
Object proceed = joinPoint.proceed(); // 执行目标方法
long executionTime = System.currentTimeMillis() - start;
// 记录日志的逻辑
logger.info(joinPoint.getSignature() + " executed in " + executionTime + "ms");
return proceed;
}
}
1.3 配置 Spring AOP+ 标记注解
@Configuration
@EnableAspectJAutoProxy
public class AopConfig {
// 可能还需要其他的配置或Bean定义
}
public class SomeService {
@Loggable
public void someBusinessMethod(Object someParam) {
// 业务逻辑
}
}
1.4 定义日志记录逻辑
在切面中,我们就可以自定义日志记录逻辑,可以记录更多的上下文信息,如方法参数、返回值、执行时间、异常信息等。
@Autowired
private Logger logger; // 例如,通过SLF4J获取的Logger
@Around("@annotation(loggable)")
public Object logBusinessOperation(ProceedingJoinPoint joinPoint, Loggable loggable) throws Throwable {
// 方法执行前的逻辑,例如记录开始时间、方法参数等
long start = System.currentTimeMillis();
try {
Object result = joinPoint.proceed(); // 执行目标方法
// 方法执行后的逻辑,例如记录结束时间、返回值等
return result;
} catch (Exception e) {
// 异常处理逻辑,如记录异常信息
throw e;
} finally {
long executionTime = System.currentTimeMillis() - start;
// 构建日志信息并记录
logger.info("{} executed in {} ms", joinPoint.getSignature(), executionTime);
}
}
1.5 方案总结
至此,实现的大框架已经编码实现,下面就是上线后坐等用户操作日志入库了!😎😎
这时我们发现方案 1.0 确实略显粗糙,主要是它很难实现以下几点:
•日志粒度和详细度:切面虽然拦截了我们目标方法,但其中能拿到的信息上下文有限,无法构成一条操作日志所需的数据信息;
•业务操作场景划分:切面的定义和使用都是非业务化的,所以无法感知到新的业务操作范围和业务的定义划分边界是如何处理;
•级联操作断档:当业务操作是设计多表或者多个服务间的调用串联时,切面只能单独记录每个服务方法级别的数据信息,无法对调用链的部分进行业务串联;
那以上问题有什么好的解决办法吗?我们来升级方案!😎
2.方案升级 2.0:AOP 切面 +SpEL
通过方案 1,我们发现记录到的日志数据都是固定的模板数据,如:XXX 修改了项目,XXX 新建了问题数据,XXX 删除了风险问题,因为我们无法通过每个切面对具体参数内容和业务场景进行捕获。那么如果我们想要在日志内容中添加更多的业务上下文信息,如:XXX 修改了项目 ID=001 的数据,XXX 删除了产品 ID=002 的数据,这时候就可以通过使用 AOP + SpEL 表达式来实现。
2.1 SpEL 表达式
首先简单介绍下 SpEL,并是不很复杂的一种新技术,我们在日常的开发中其实大家都隐形的在使用 SpEL。
官方的定义:SpEL(Spring Expression Language)是 Spring 中的表达式语言,用于在运行时评估和处理表达式。它提供了一种灵活的方式来访问和操作对象的属性、方法和其他表达式。SpEL 可以用于配置文件、注解、XML 配置等多种场景。
举个例子就是我们日常项目中最熟悉的@Value注解,在注解中使用是支持常见的表达式操作的,如算术运算、逻辑运算、条件判断、集合操作等,并且可以与 Spring 框架的其他功能整合使用。
@Value("#{mq.topic}")
public String mqTopic;
@Value("#{T(java.lang.Math).random() * 100.0}")
private double randomNumber;
我们先来了解下他的一些核心概念:
// 解析器
ExpressionParser parser = new SpelExpressionParser();
// 使用解析器,解析 SpEL 表达式
// 该表达式中定义了字符串 'Hello ' 常量,并且调用它的 .concat 方法,参数是一个引用变量
Expression expression = parser.parseExpression("'Hello '.concat(#param)"); // 在表达式中,使用 #param 访问上下文中的参数
// 在上下文中执行表达式,获取 String 类型的结果
String result = expression.getValue(context, String.class);
通过对 SpEL 的了解我们发现,可以在方案 1 的注解基础上,我们对注解的内容进行扩展,扩展后就可以通过标记注解的方法对方法的全部上下文信息进行获取了!这样就可以弥补方案 1 中注解捕获到信息量小且无法自定义的不足,那么具体该如何使用呢?
2.2 表达式定义
首先对方案 1 中的注解内容进行扩展,把我们业务场景所需要涉及的操作类型,数据内容等信息进行定义:
@Repeatable(LogRecords.class)
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface LogRecord {
String success();
String fail() default "";
String operator() default ""; //业务操作场景人
String type(); // 业务场景 模块范围
String subType() default ""; //业务子场景,主要是模块下的功能范围
String bizNo(); //业务场景的业务编号,
String extra() default "";//一些操作的扩展操作
String actionType(); //业务操作类型,比如编辑、新增、删除
}
然后我们基于注解进行定义 SpEL 的解析器来对注解中的字段进行解析和使用:
import org.springframework.expression.Expression;
import org.springframework.expression.ExpressionParser;
import org.springframework.expression.TypeResolutionContext;
import java.lang.reflect.Annotation;
import java.util.Map;
public class LogRecordParser {
public static Map<String, Object> parseLogRecord(Annotation logRecordAnnotation) {
Map<String, Object> result = new HashMap<>();
ExpressionParser parser = new ExpressionParser(new SpelFunction("parseLogRecord", LogRecordParser.class, "parseLogRecord"));
for (String attribute : logRecordAnnotation.getAttributeNames()) {
Object value = logRecordAnnotation.getAttribute(attribute);
Expression expression = parser.parseExpression(attribute);
TypeResolutionContext typeResolutionContext = new TypeResolutionContext();
typeResolutionContext.setMethod(new Method(null, null, null));
Object parsedValue = expression.getValue(typeResolutionContext);
result.put(attribute, parsedValue);
}
return result;
}
}
当面的解析部分只是比较核心的数据解析部分,具体解析后的业务处理逻辑大家可按需处理。那么基于上面的 AOP+SpEL 的方式,我们就可以手动在我们需要标记的业务进行注解的使用了。
2.3 表达式使用
下图是系统中实际业务操作的使用场景,大家可以看到我们标记后在注解的内容中填充了很多业务操作场景的数据,如果需要涉及操作前后数据的内容记录,我们还可以再次进行扩充 SpEL 的字段及解析逻辑,可以说是有了它,我们可以做的更多了!(但是注解也越来越长了)
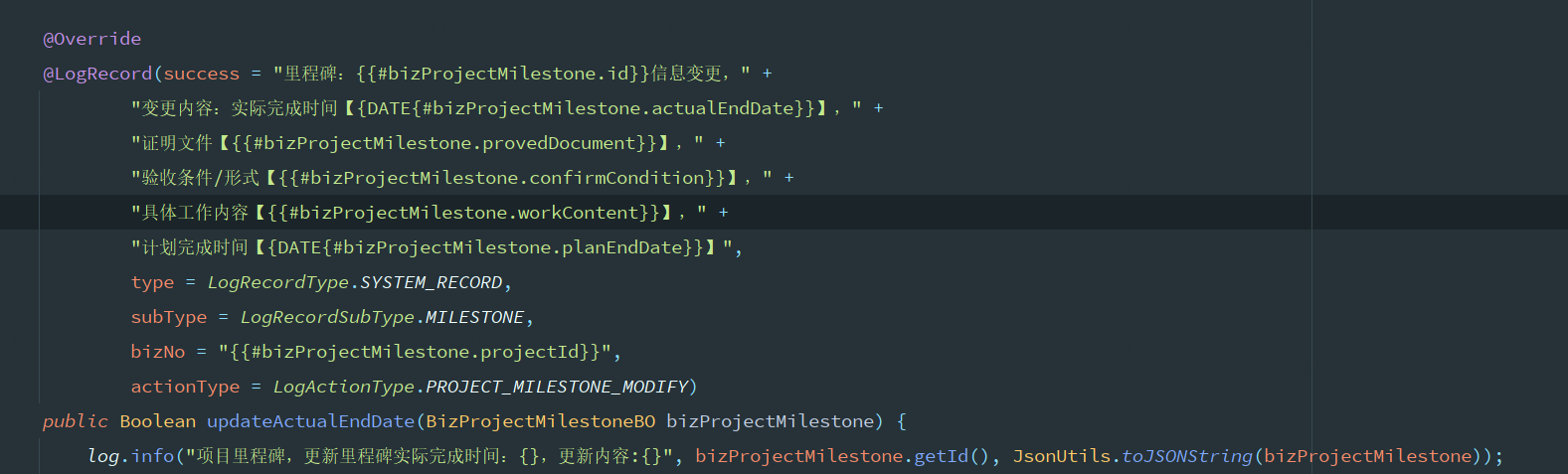
2.4 方案总结
•缺点:解决了方案 1 中冗余重复代码层面的侵入,但会出现大量注解定义的出现,也带有一定的侵入性
•缺点:日志内容还是需要系统自身根据上报场景进行封装,需要从产品的业务定义到研发编码达成统一共识
•优点:与方案 1 相比简化了一部分代码集成的复杂度,只需编写自定义注解即可
•优点:与方案 1 相比扩展了对操作的业务数据广度,数据范围大大增加,而且还可根据自身业务定义无限扩展
本方案在落地效果来看确实解决了业务操作日志的一个收集问题,能够清晰的记录各类操作场景、动作、数据前后的内容等,但总还是觉得不够优雅,还能有更好的方案解决方案 2 的缺点吗?
=======================✍️思考的分割线✍️========================
思考:我们一直在想怎么从应用层对操作场景、数据进行抓包、处理逻辑、保存,所以复杂度都会集中到应用层。既然是这样我们能不能直接基于底层的 MySQL 本身来处理这件事儿呢?它对数据的变化感知比我们要敏锐呢?
3.方案升级 3.0:Binlog+ 时间窗口
3.1 Binlog
Binlog 大家都不陌生,是数据库中二进制格式的文件,用于记录用户对数据库更新的 SQL 语句信息,例如更改数据库表和更改内容的 SQL 语句都会记录到 binlog 里。那么 Binlog 能用来记录业务层面的数据变化内容吗?
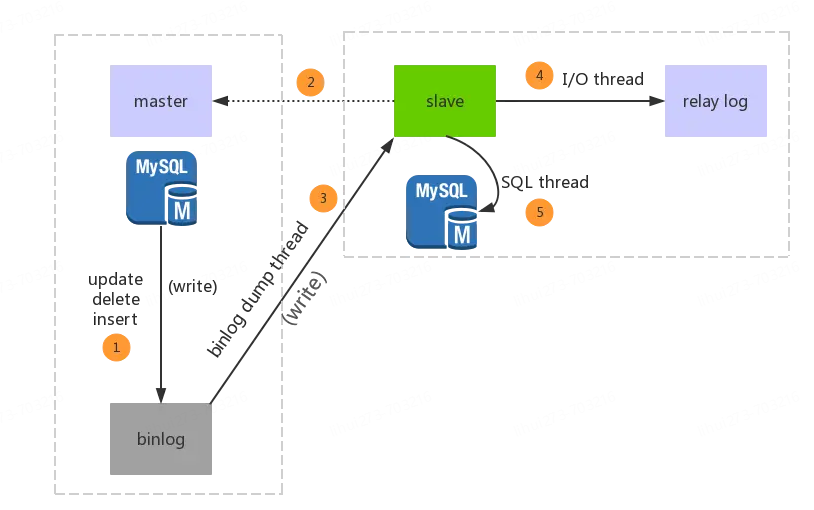
《引用:MySQL 主从及 binlog 日志同步结构》
3.2 方案问题及思路
问题:
•问题 1:无法对多表存在级联保存和更新的数据进行非常好的兼容支持,因为本身 binlog 数据是无序的,并且如果上游数据的操作不是包裹在一个事务中,也很难处理
•问题 2:关于更新人的问题,系统进行更新时如果未手动更新对应操作人,则系统无法识别,需要上游做对应场景的统一改造,但从系统承接来看,本身系统的操作人就是要跟着业务操作一起进行联动的
方案:
解决问题 1:由于本身 binlog 的无序性,所以无法对大量 binlog 进行有序组合,如果本身是一个事务提交的还可以根据事务 KEY 进行组合,如果不是呢?这里可以考虑借鉴 Flink 的时间窗口机制:滚动的时间窗口将每个元素指定给指定窗口大小的窗口,滚动窗口具有固定大小,且不重叠。
例如,我们指定一个大小为 1 分钟的滚动窗口,在这种情况下,我们将每隔 1 分钟开启一个新的窗口,其中每一条数都会划分到唯一一个 1 分钟的窗口中,如下图所示:

基于以上的窗口机制,我们就可以对数据先进行范围的框定,通过窗口的滑动机制和补偿机制对窗口中的数据进行关联处理。但光靠时间窗口还是无法对 binlog 进行关联,那我们就从关联数据本身下手,这类数据关联复杂主要是涉及表之间的引用关系,那我们在进行定义 binlog 解析时就把前后数据 + 表之间的引用字段都进行指定,这样在窗口中进行滑动关联时,就可以进行子表的引用字段关联了!这样关联字段补偿更新的机制就可以解决问题 1 了。部分的 binlog 数据变动结构的 RowChange 定义如下:
@Data
public static class RowChange {
private int tableId;
private List<RowDatas> rowDatas;
private String eventType;
private boolean isDdl;
}
@Data
public static class RowDatas {
private List<DataColumn> afterColumns;
private List<DataColumn> beforeColumns;
}
@Data
public static class DataColumn {
private int sqlType;
private boolean isNull;
private String mysqlType;
private String name;
private boolean isKey;
private int index;
private boolean updated;
private String value;
}
解决问题 2:关于更新人的问题其实是各系统需要自己排除解决的问题,因为本身业务在进行数据操作时就是需要留痕更新人信息,比较统一的方案就是基于底层的 ORM 框架来统一进行拦截处理,大家可以自行 GPT。
3.3 方案架构
思路和问题都清晰了,那我们来画一画整体的方案架构:

3.4 方案总结
整体方案设计完后,有一种非常轻快的感觉,它! 优! 雅! 了! 确实需要应用层做的不多了,而且本身架构还可以复用到其他系统,实现日志收集的中心化管理。那么它完美了吗?还是有缺陷。
•基于 binlog 后,我们对底层的数据变动感知更明显了,但是 binlog 的数据来源除了系统应用层还有很多其他来源,比如我们的数据库工单,日常跑批刷数等场景,这类的数据变动范围可能较大,而且感知较弱。
•方案 3 的设计把方案 2 中的业务场景(也就是 actiontype subtype 等)弱化了,所以并不能很好的感知到很细颗粒度
•其他欢迎大家补充....
4.写在最后
通过以上的业务背景及实现落地过程,我感受到其实在日常业务需求对接和实现过程中,会伴随着各种各样的问题出现,会有很多因素让你对某技术方案进行舍弃,但是舍弃了 A 可能单来了 B C D 等一连串的问题,我们在做系统架构时,其实也是一个慢慢演进的过程,对技术实现的思路和方案要拥抱变化,摒弃自己的一些 “技术极致” 追求,做好兜底方案,完美的方案可能是少数,努力适配自己的技术架构和方案才是我们长期要做的。
技术并不是银弹,我们的思考过程才是,感谢您的阅读!😋
作者:京东科技 李辉
来源:京东云开发者社区 转载请注明来源