文章暂未进行审核
Selenium Selenium+python 针对百度首页的各种新闻链接点击访问实例
本实例主要是通过 Selenium 实现百度首页的新闻链接操作,供初学者参考
具体的实现步骤
1.导入需要用到的 python 包和方法
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
2.创建驱动对象并打开百度主页
wb=webdriver.Chrome(service=Service(r'D:\Chromedriver\chromedriver119\chromedriver.exe')) #Service方法中传的是你的Chrome驱动所放置的具体路径
wb.get("http://www.baidu.com/")
sleep(5)
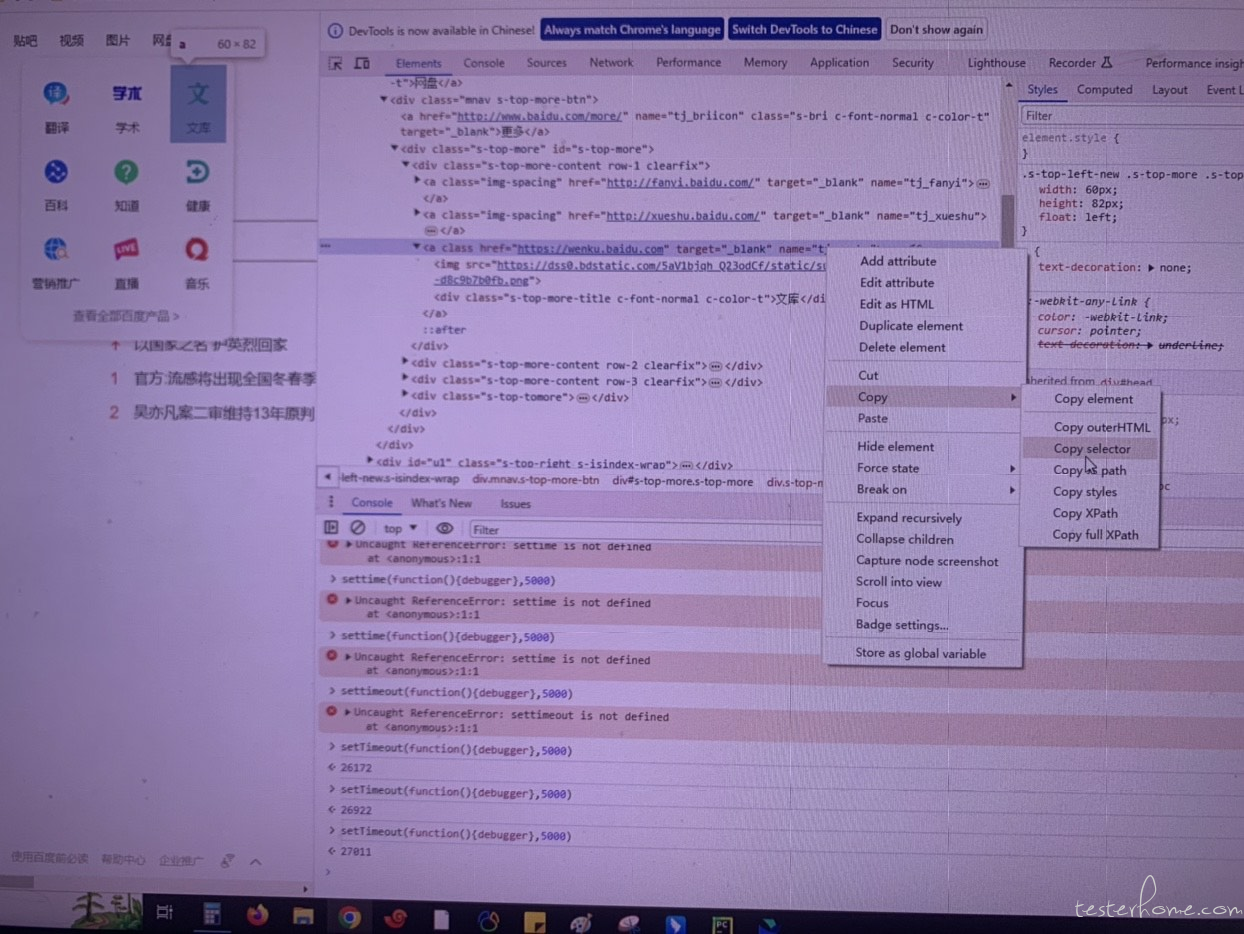
3.打开百度首页左上角的新闻链接
#通过Link_text定位到百度首页的“新闻”超链接,其他的几个链接也可以使用相同的方法
wb.find_element(By.LINK_TEXT,'新闻').click()
sleep(2)
4.切换回最初打开的百度主页
#最开始打开的页面句柄id=0,最新打开的页面句柄id=-1,倒数第二打开的句柄id=-2,依次类推
wb.switch_to.window(wb.window_handles[0])
print("切换到最开始打开的百度主页")
sleep(2)
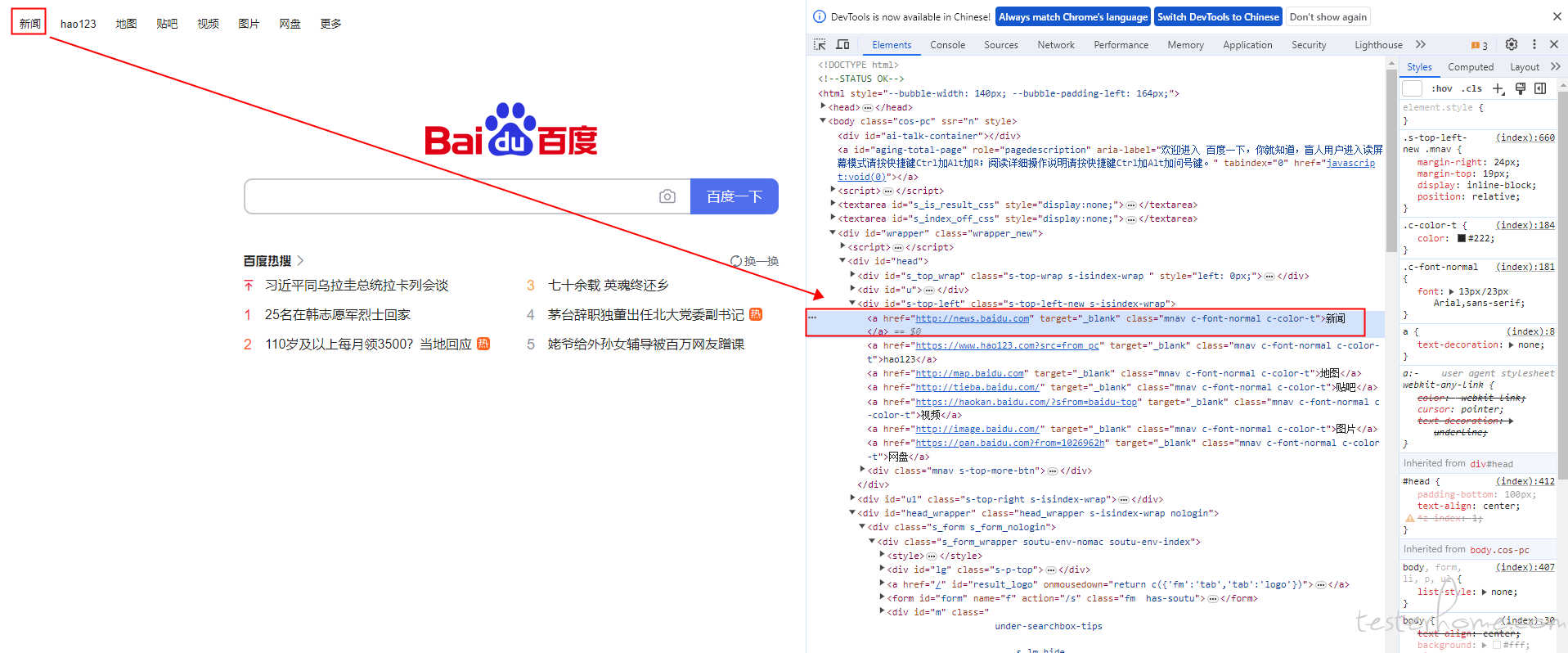
5.尝试依次点击百度热搜的新闻链接
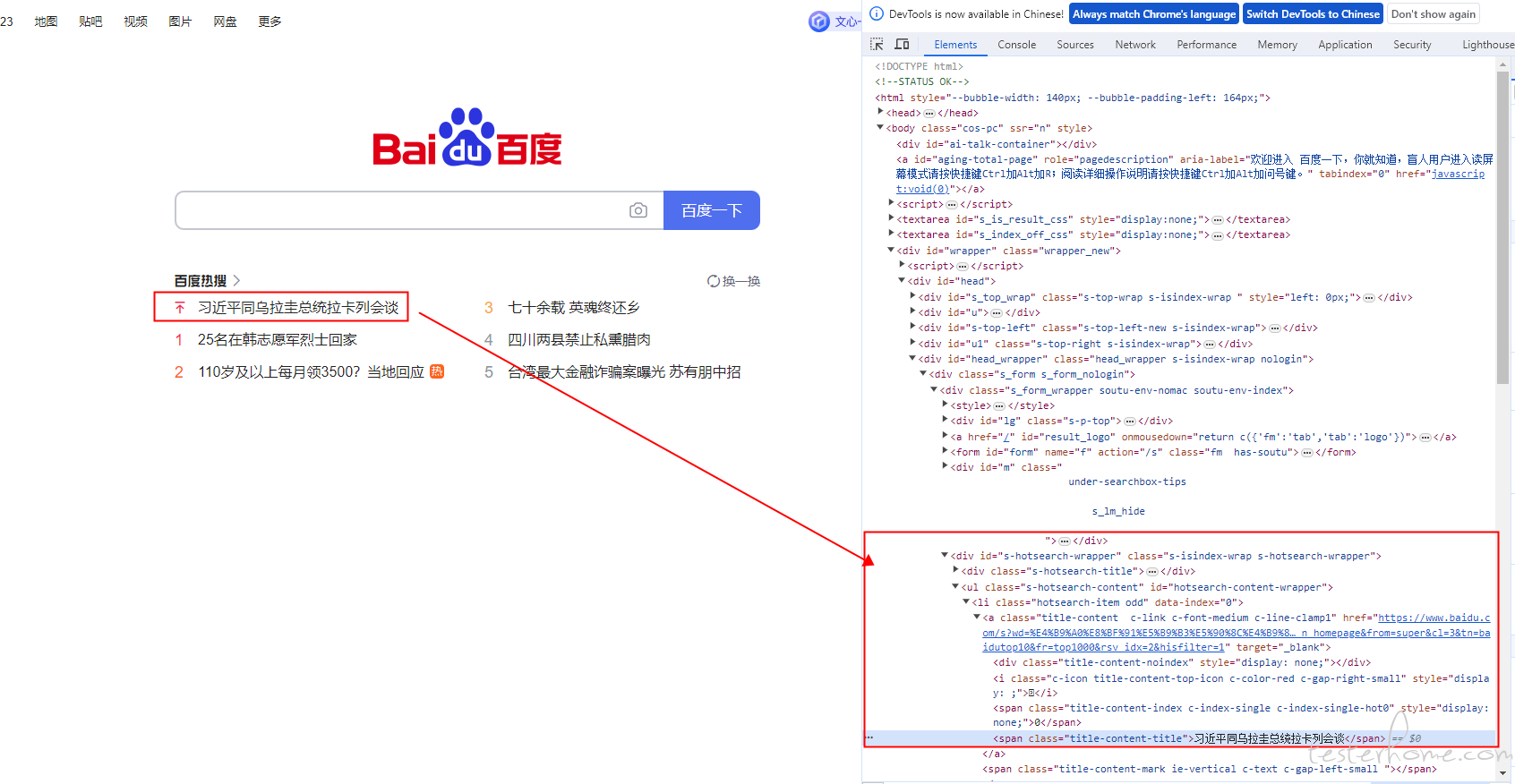
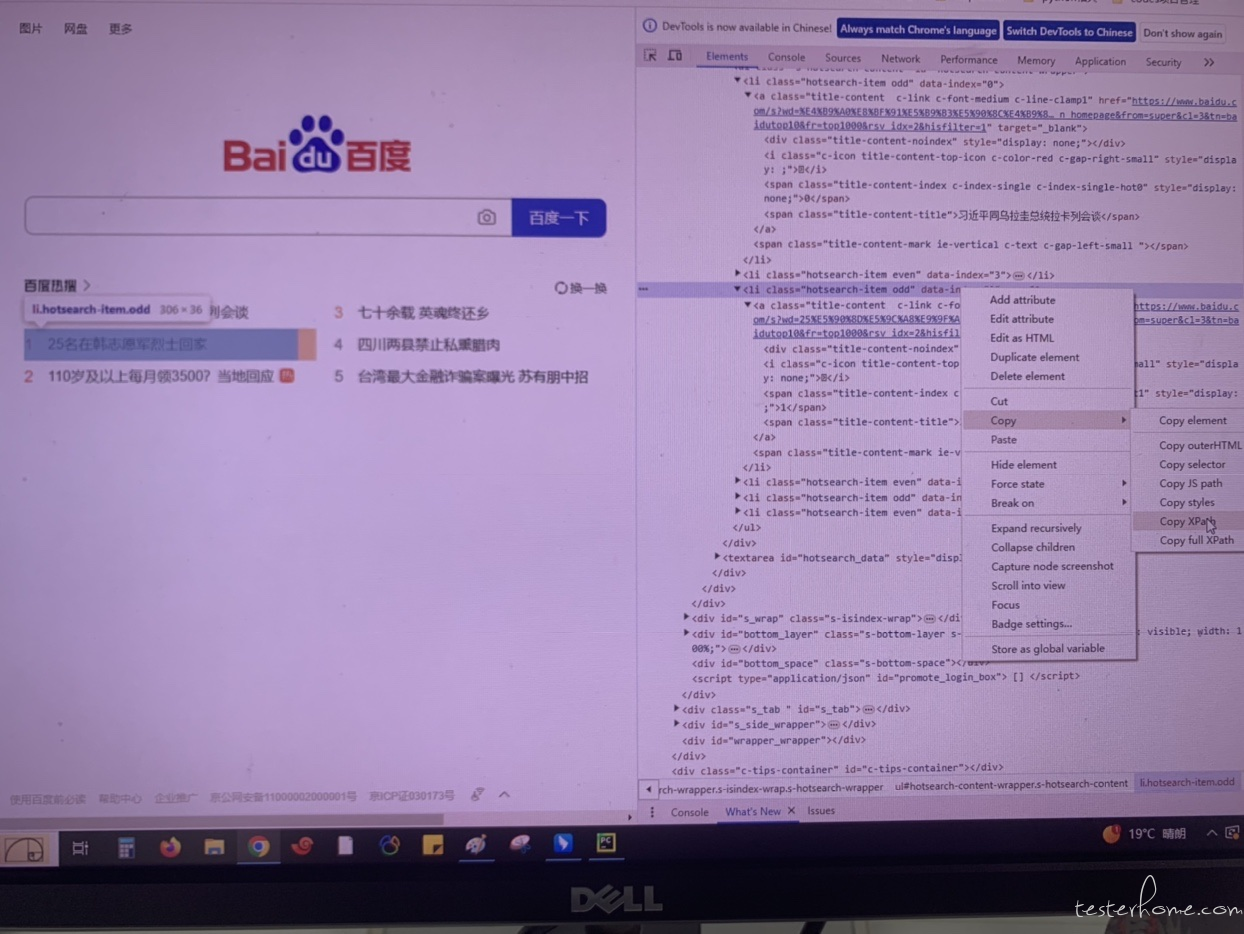
当时定位这个区域的链接的时候,试了好多种方法,都没找到合适的定位。因为这个区域有好几条新闻,然后新闻的内容是会刷新的,根据名字或者内容定位肯定是不现实。后来尝试了通过 Xpath 方式可以依次精准定位到,我看到这几条新闻都有一个索引值。
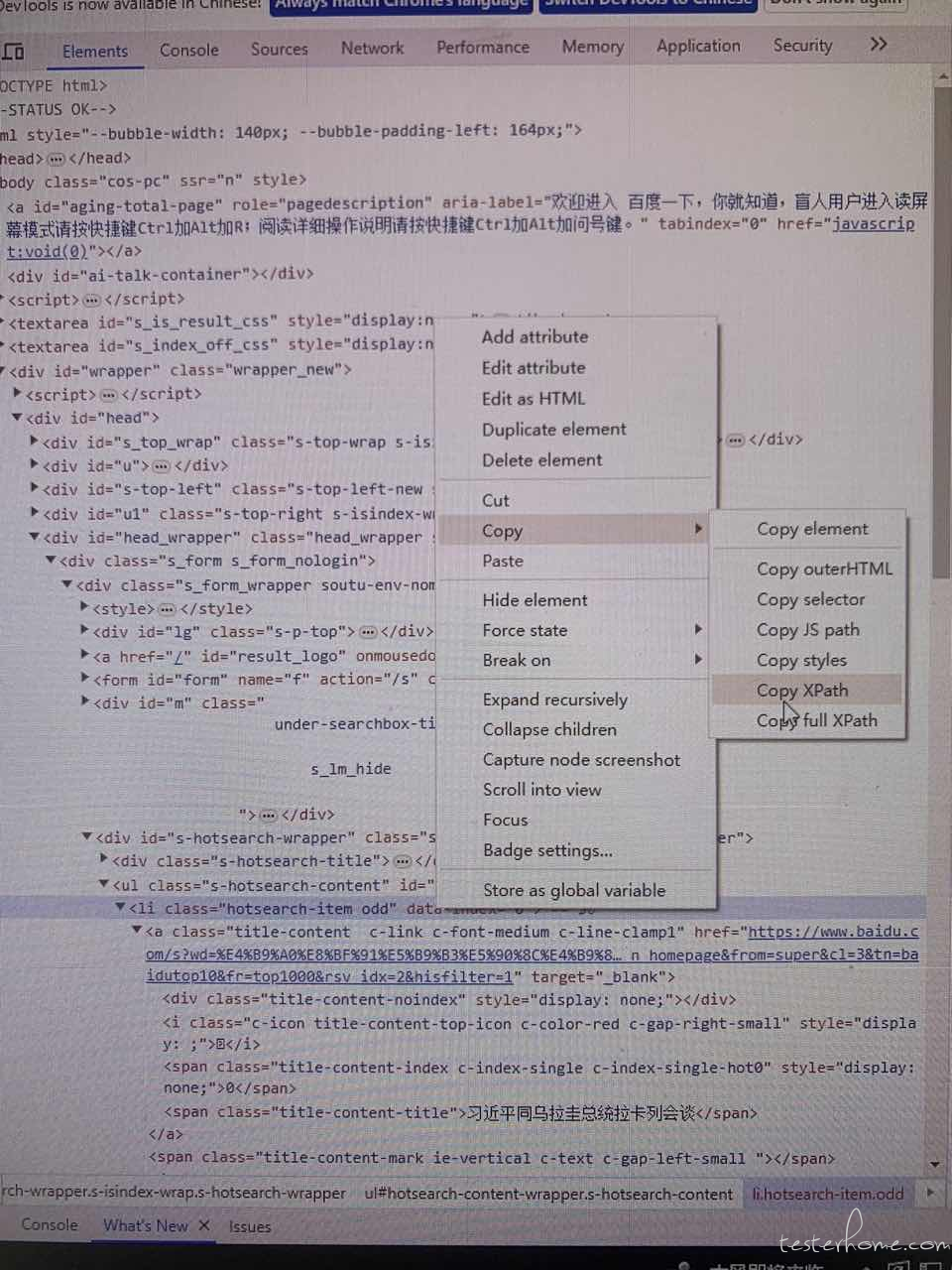
复制 Xpath 后,粘贴到代码中,就自动生成了 Xpath 的值://*[@id="hotsearch-content-wrapper"]/li[1]
#访问百度首页的“百度热搜”被置顶的新闻链接
wb.find_element(By.XPATH,'//*[@id="hotsearch-content-wrapper"]/li[1]').click()
sleep(5)
注意:以上方式打开新的 Tab,但是 Selenium 还是认为当前 Tab 停留在百度主页上面,并不是新打开的新闻页面
热搜区域的其他几个新闻链接,以此类推
# 访问百度首页的“百度热搜”编号为1的新闻链接
wb.find_element(By.XPATH,'//*[@id="hotsearch-content-wrapper"]/li[3]').click()
sleep(5)
# 访问百度首页的“百度热搜”编号为2的新闻链接
wb.find_element(By.XPATH,'//*[@id="hotsearch-content-wrapper"]/li[5]').click()
sleep(5)
# 访问百度首页的“百度热搜”编号为3的新闻链接
wb.find_element(By.XPATH,'//*[@id="hotsearch-content-wrapper"]/li[2]').click()
sleep(5)
# 访问百度首页的“百度热搜”编号为4的新闻链接
wb.find_element(By.XPATH,'//*[@id="hotsearch-content-wrapper"]/li[4]').click()
sleep(5)
# 访问百度首页的“百度热搜”编号为5的新闻链接
wb.find_element(By.XPATH,'//*[@id="hotsearch-content-wrapper"]/li[6]').click()
sleep(5)
6.点击百度首页的 “换一换” 按钮,进行热搜新闻链接的刷新
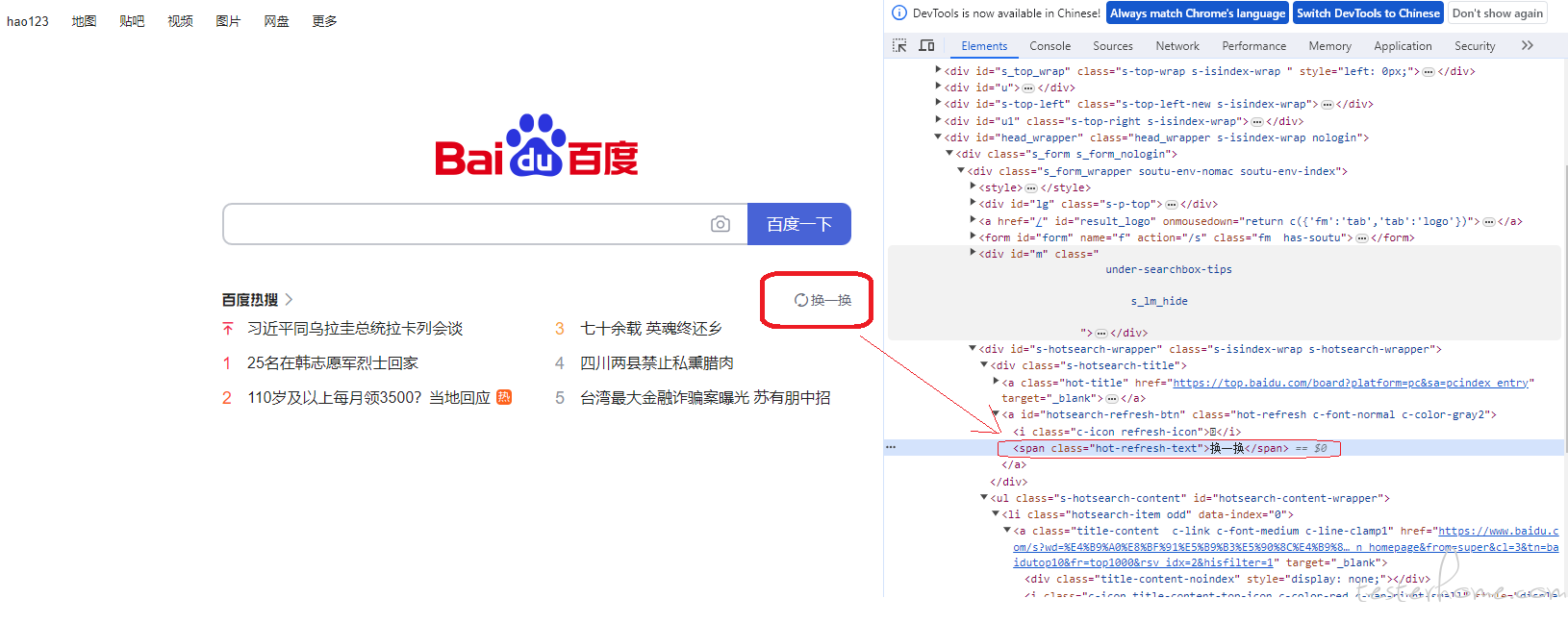
此时 Selenium 会认为当前 Tab 还是在百度主页,但实际上浏览器的表现当前 Tab 是在新打开的新闻网页上,所以我们要点击百度主页的 “换一换” 按钮,前提是要切换到百度主页上
#将浏览器的当前展示Tab切换到百度主页
wb.switch_to.window(wb.window_handles[0])
print("切换到最开始打开的百度主页")
sleep(2)
#点击搜索框下侧的“换一换”按钮
wb.find_element(By.CLASS_NAME,'hot-refresh-text').click()
sleep(5)
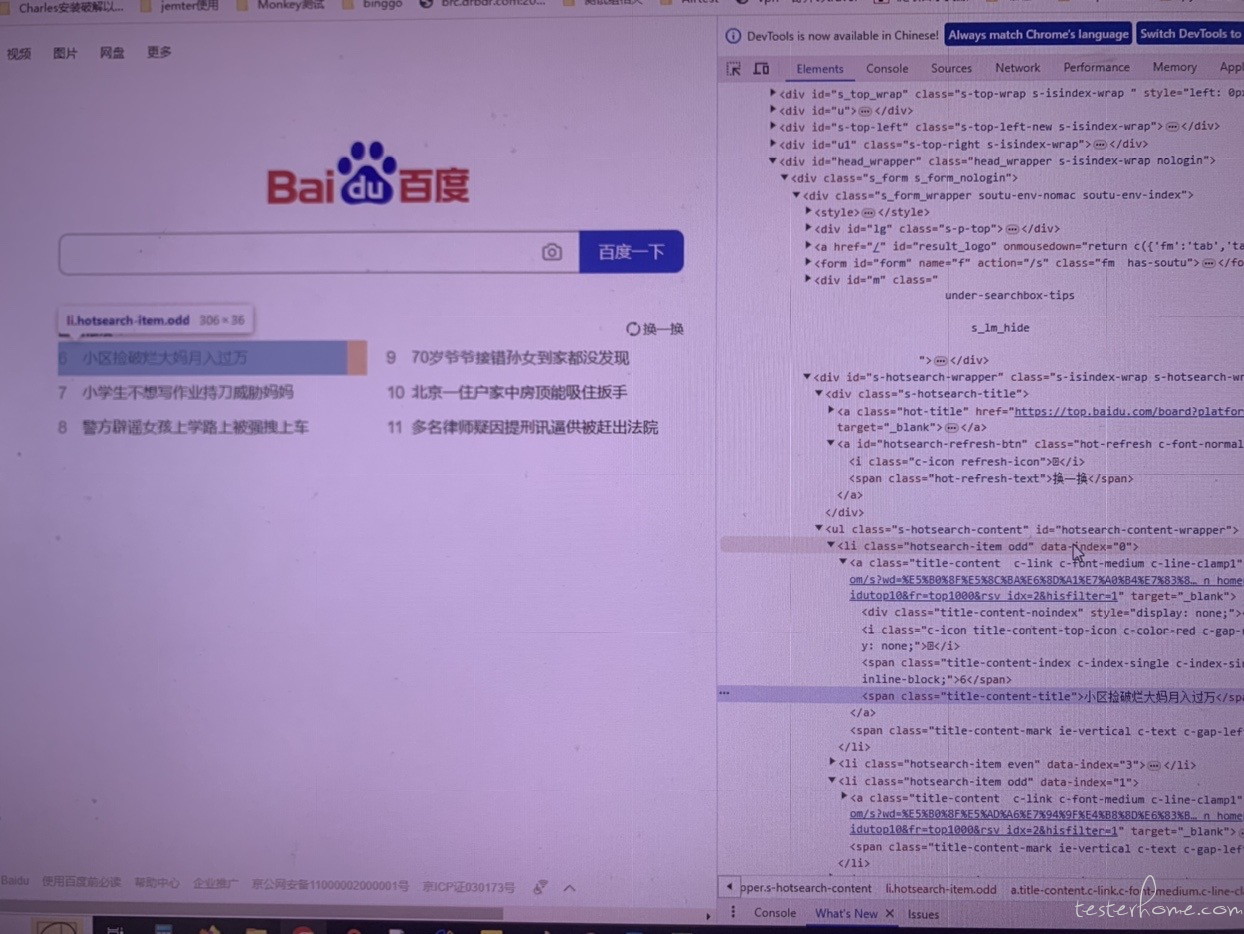
7.“换一换” 点击之后,会出现新的编号新闻内容,进行点击操作
此时虽然新闻编号和内容变了,但是每条新闻所对应的位置,还是与步骤 5 中 6 条新闻对应的位置一致
所以此时如果还需要再对 6-11 的新闻进行点击,只需要把步骤 5 中的点击操作再重复 一遍即可
8.新闻都点击了之后,将浏览器关闭
wb.quit()
print("测试已完成,退出浏览器")
「原创声明:保留所有权利,禁止转载」