介绍 ab 分流的流量保护功能之前,先普及一下 ab 分流的一些概念和术语
名词解释:
- 实验:用来验证某个决定请求处理方式的功能或策略的一部分流量,通常用来验证某个功能或策略对系统指标(如 PV/UV,CRT,下单转化率等)的影响。
- 流量 :指所有访问用户的请求
- Hash 因子:可以理解为访问实验用户的 uuid,即一个可以识别某个流量用户的唯一标识。
- Hash 算法:是把任意长度的输入通过散列算法变换成固定长度的输出,是一种从任意文件中创造小的数字「指纹」的方法。与指纹一样,散列算法就是一种以较短的信息来保证文件唯一性的标志
- 桶位:ab 测试又称为分桶测试。当用户的请求打到某个实验进行分流时,分流引擎会根据请求的 uuid + 强一致性 hash 算法(保证分每个桶分到的越随机越平均越好)生成一个全局固定不变的值 ,然后 值取模 100 得到一个 0-100 区间的具体桶位编号,一个百分点对应一个桶位编号。
- 实验版本:实验版本即实验分组,A/B 实验通常是为了验证一个新策略的效果。在实验进行中,所抽取的用户被随机地分配到 A 组和 B 组中,A 组用户体验到新策略,B 组用户体验的仍旧是旧策略。在这一实验过程中,A 组便为实验组,B 组则为对照组。也有多个实验组和一个对照组构成的实验,他们共同承载了 100% 的流量请求。
用户桶位编号如何生成
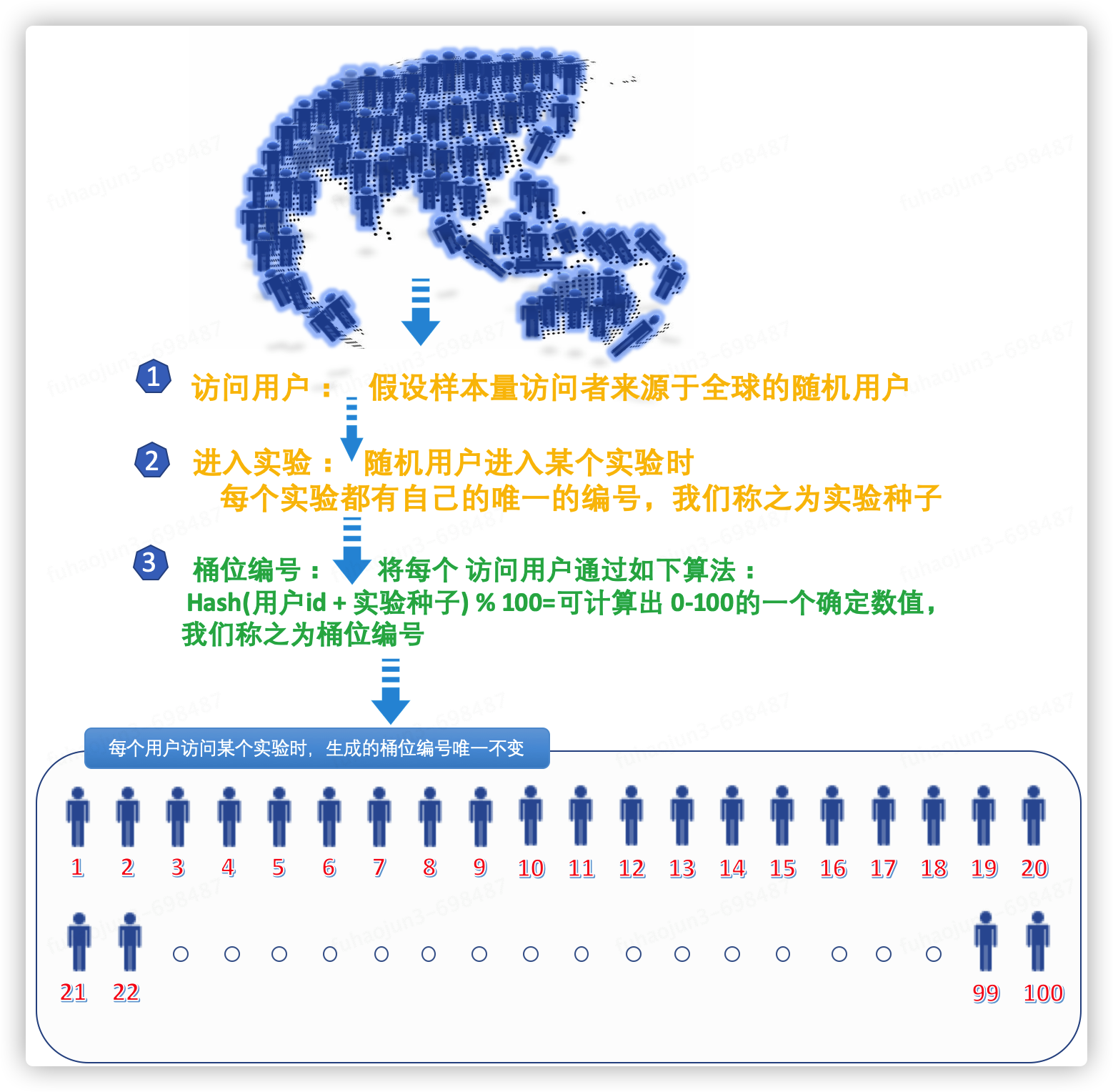
如上图说明,现在大家知道一个用户访问某个实验时都会有一个唯一固定的编号。
为了更好阐述其意,假设我们有这样 26 位流量用户,分别是 A-Z 的这样 26 位用户:
{A , B , C , D , E , F , G , H , I , J , K , L , M , N , O , P , Q , R , S , T , U , V , W , X , Y , Z }
他们访问实验 X 时,通过 Hash(uid+ 实验 X 种子) 生成了如下的实验编号(命名规则为:用户 x_桶位编号):
A_11,B_9,C_12,D_10,E_7,F_9,G_24,H_22,I_18,J_8,K_21,L_15,M_1,N_4,O_76,P_33,Q_40,
R_5,S_12,T_80,U_67,V_25,W_33,X_49,Y_87,Z_100

他们访问实验 Y 时,通过 Hash(uid+ 实验 X 种子) 生成了如下的实验编号(命名规则为:用户 x_桶位编号):
A_25,B_17,C_19,D_2,E_1,F_18,G_19,H_22,I_12,J_2,K_22,L_14,M_4,N_16,O_28,P_30,
Q_92,R_93,S_8,T_55,U_18,V_100,W_1,X_100,Y_50,Z_36
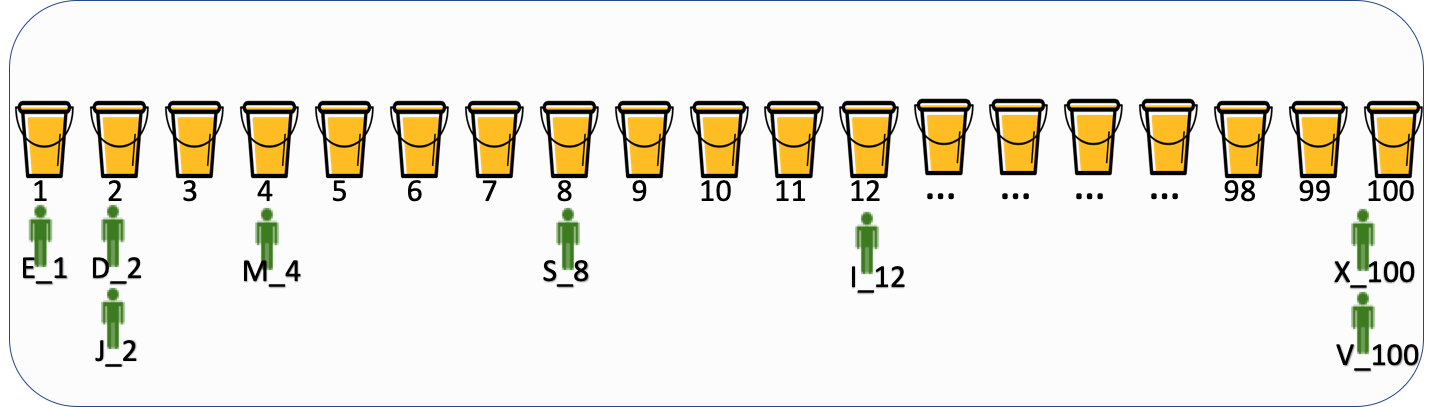
通过上面的案例说明,随机的流量用户访问实验时,某些用户生成的桶位编号会一样,那他们就会进入实验的同一个分组里。
实验版本与桶位的关系
一个桶位编号代表全部流量(100%)的一个百分点的流量 (1%)
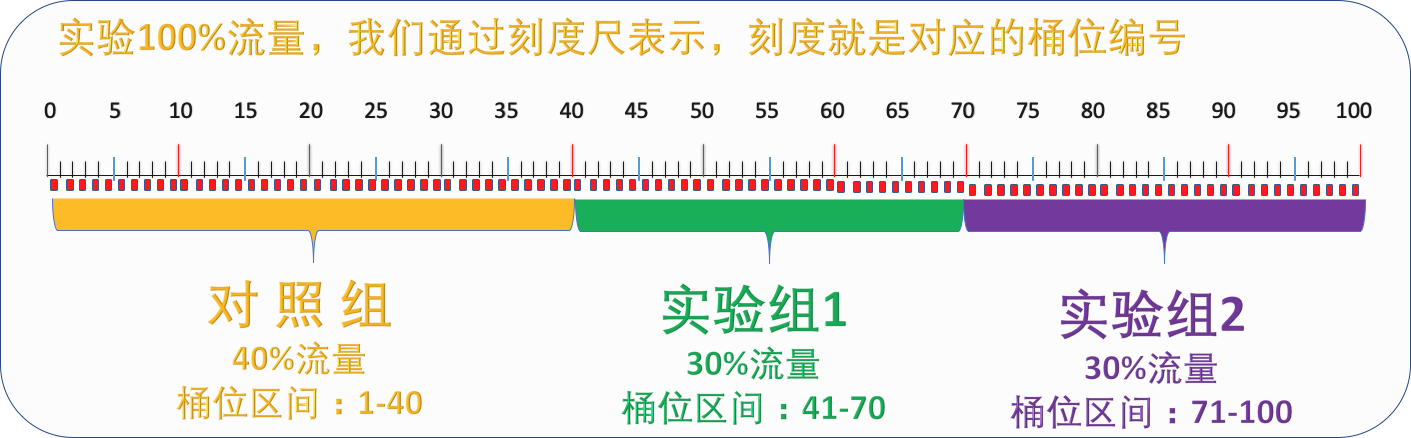
实验分流演示
假设我们一个实验有三个版本即三个分组,分别是 实验组 1=VA,实验组 2=VB,对照组=VC
初始分组比例为:VA=10%,VB=10%,VC=80%
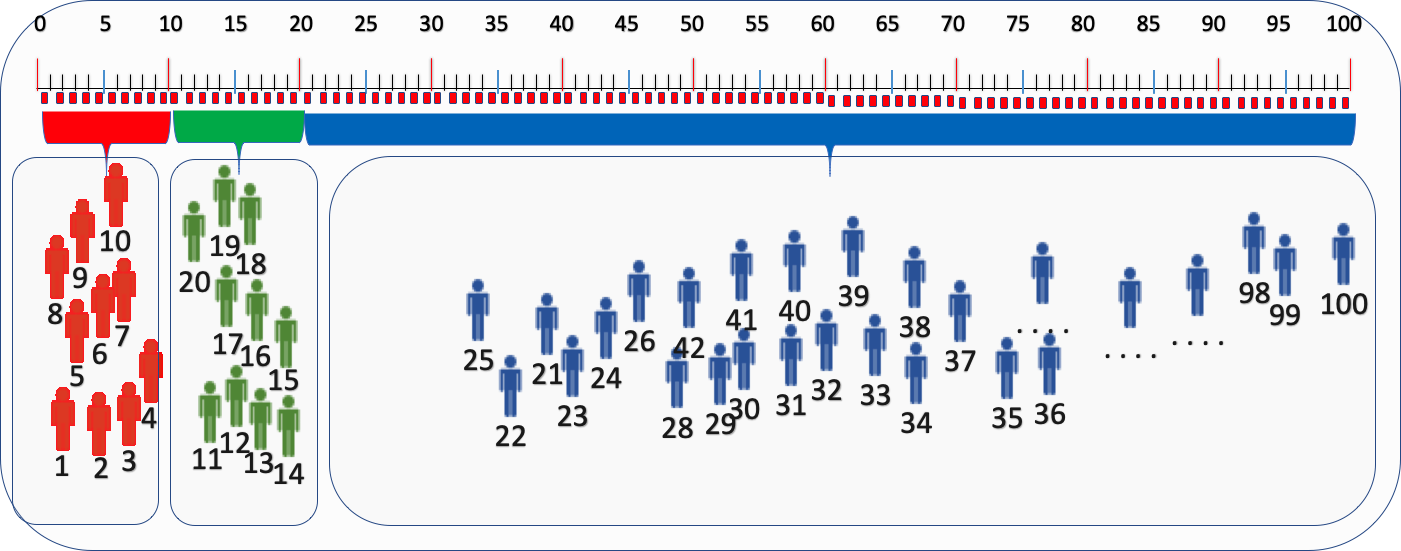
下一步,我们要将实验组流量扩量,流量分别为:VA=20%,VB=20%,VC=60%

这种扩量后的分流,从分流角度看是 ok 的,But 细心的同学可能会发现之前进入实验组 2 的用户 11-20 桶位编号的在进行实验组扩量后,居然...居然...被分配到实验组 1。这样就发生了用户跳组的情况,如果接下来继续扩量,一直会存在此类问题:就是进入过实验组 2 的用户扩量后又被分配到实验组 1。
每次都有实验组用户污染的问题,但是运营同事每次调整比例时并不知道后端分配逻辑,他们会想当然认为流量分配是 ok 的,这种分配方式会造成数据分析问题和用户体验问题,可能比例调整后对其他组的用户进行了污染,这样的结果在业务上是不可接受的
那么... 针对这种情况实际怎么分配会最佳呢,继续往下看。
正确的分流效果图

如上效果图:
VA 版本由原来的 10% 扩量到 20%,正确的分流是:
新增的 10% 流量来自对照组 VC 的流量用户即桶位区间是 21-30。
扩量后 VA 的 20% 流量是由:1-10,21-30 的两个桶位区间。
VB 版本由原来的 10% 扩量到 20%,正确的分流是:
新增的 10% 流量来自对照组 VC 的流量用户即桶位区间是 31-40。
扩量后 VB 的 20% 流量是由:11-20,31-40 的两个桶位区间。
这样的扩量之后不会出现之前那样的流量用户发生跳组,即保证原来的用户进入的哪个版本扩量之后还是之前的版本。
这种的分流优化我们称之为:流量保护,就是我们本篇文章重点介绍的功能。
为什么做流量保护:
答:实验迭代时,增减版本、调整比例是最高频的操作,此时平台采用了【流量保护】功能,即每次修改先识别减少比例的版本,从减少比例的版本的流量拆分给增加比例的版本。最大限度隔离流量,减少实验组之间相互污染;
引入流量保护功能
ab 分流亟需解决这种不科学的流量调整问题,升级【流量保护】功能后,再看一组如下实验的版本流量迭代的推演过程(红色代表 A 组、蓝色代表 B 组、绿色代表 C 组)

这样经过多次调整后,每个实验都尽可能的减少了自己区间的变动,保证自己用户的留存性,减少对实验指标的影响
流量保护动画推演
大家可以直接欣赏:四个版本比例调整的推演(可以关注每个版本色块的变化)

从上面的例子可以看出,经过多次的流量调整后,各个实验的区间分布会变得比较复杂,但是从使用者的角度看,他只需要关心每个实验所占的流量配比,不需要关心底层实验流量的区间分布情况 (这块对他是黑匣子),因此不会增加使用者操作的难度。
流量保护分配规则
- 对版本比例调整进行分组:比对版本修改前、后的数据。按序识别比例新增、减少、不变的三个变化组
- 将版本减少组的桶位拆分:对减少组版本桶位区间从最右侧拆分、匹配直到满足减少的浮动比例的桶位区间段
- 对拆分的桶位区间排序、移动:对减少组被拆分的桶位区间按从左到右的排序,依次次分配给新增版本
- 对版本变化后的桶位排序、合并: 分配后的所有版本进行桶位区间排序,相邻的桶位区间进行合并操作
作者:京东科技 付浩军
来源:京东云开发者社区 转载请注明来源