作者:赵泽鑫 |QE_LAB
K6 的简单介绍
K6 是一个现代化的、开源的负载测试框架,可以帮助开发者和测试人员对 Web 应用程序、API 以及微服务进行性能测试。K6 基于 JavaScript 编写,简单易学,不需要额外的编程语言或工具。同时该框架社区生态也很好,有很多拓展可以根据需要灵活的进行选择。
使用 K6,用户可以创建自定义的性能测试脚本,模拟多种负载场景,包括并发用户数、请求速率、请求类型、网络带宽等,在真实的环境中对应用程序进行压力测试,发现问题并进行优化。
K6 还提供了丰富的测试报告和分析工具,可视化展示测试结果,帮助用户快速定位性能瓶颈和优化方案。K6 支持多种协议,包括 HTTP/2、WebSockets、gRPC 以及 SSL\TSL。
安装 K6 的方式很简单,Mac 电脑直接使用brew install k6进行安装即可。同时它也支持 dockerdocker pull grafana/k6 。运行测试使用K6 run file_name。同时支持添加参数,比如虚拟用户(virtual users)和持续时间(duration)等。
K6 执行模式
Local: 测试完全发生在一台机器、容器或者 CI 服务上 k6 run script.js
Distribute:测试通过 K8S 集群分布式的执行kubectl apply -f /path/k6-resource.yaml
Cloud:测试执行在 K6 的 cloud 上k6 cloud script.js
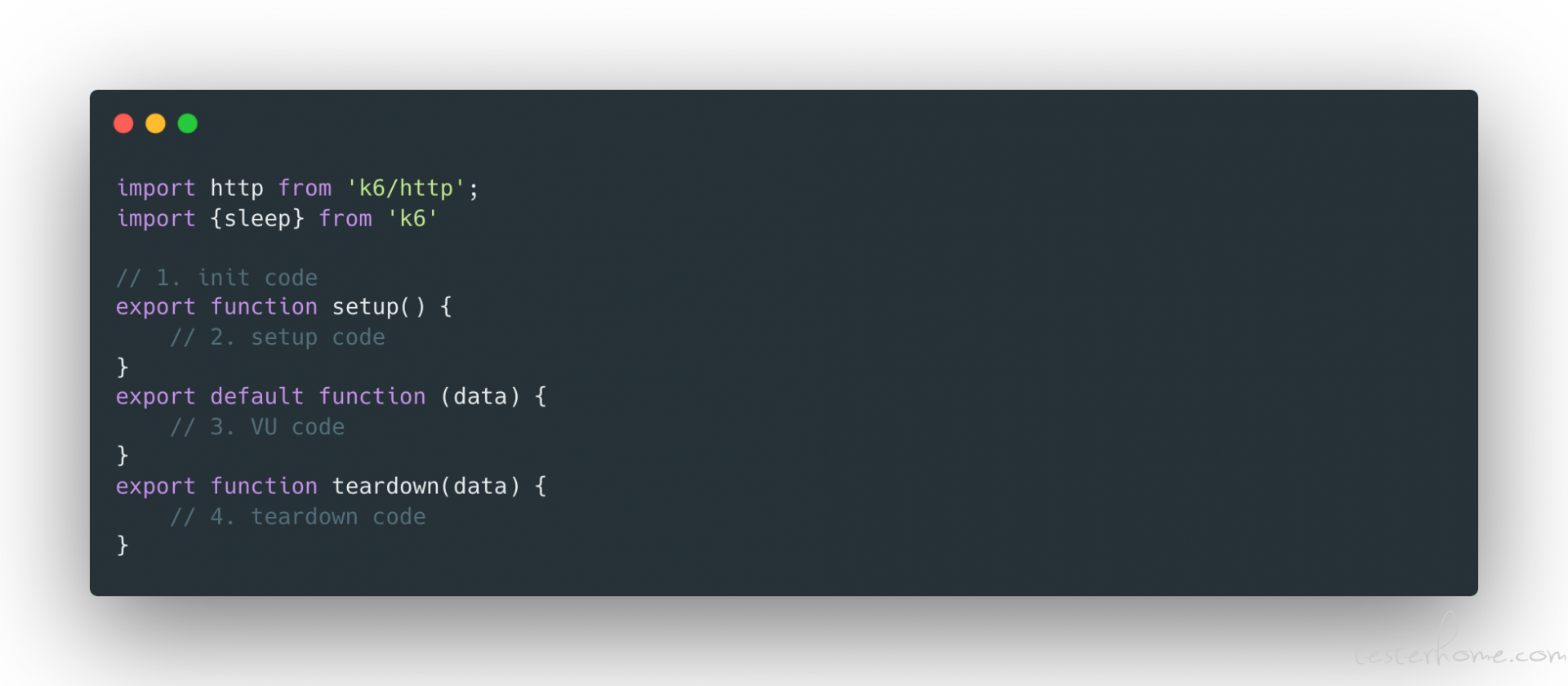
简单的 K6 测试的生命周期
- init code, 一般指的是需要加载的本地文件、K6 options 的定义和 import 一些必要的 module。
- set up code,测试需要的前置步骤,一般是测试需要的数据以及测试环境的初始化。
- VU code,测试代码一般在这里,处理一些测试必要的逻辑,一般是 API 调用逻辑以及度量的指标。对于 K6 而言,虚拟用户本质是 javascript 实现的平行的 while(true)循环。K6 还提供了额外的生命周期函数给我们使用,以应对复杂的业务逻辑,在 VU code 中还可以使用 scenario function 来代替 default function。关于 scenario 后面会详细讲解。
- tear down code,一般包括测试结果的处理以及关闭测试环境和数据回收。
K6 框架中的重要组成部分
1. HTTP request
支持丰富的 HTTP 请求类型,包括 batch\put\post\get\delete\等。
HTTP Request Tags
tag 是 K6 为了更好的筛选测试结果,默认是会自动给每个 HTTP 请求打 tag 的,tag 的类型包括期望的响应内容、URL、分组名称和场景。
URL Grouping
通常情况下,一个 URL 会被默认分配一个 URL tag,如果是动态的 URL 路径,我们就不希望有这种行为,因为会给 tag 带来大量的独特 URL,导致难以管理并且这些独特的 URL 值是没有什么意义的。所以更好的方式是使用 grouping 功能,在组内给一个共同的名字。比如请求 id 要 1-100 作为一次查询,这时候需要将 id 作为参数传递进去然后循环 100 次,每次用不同的 id,每次打上一个相同值的 name tag。这 100 次请求组成的 group 就能使用 name 共同管理。metrics 也支持 group,会对一个 group 进行度量。
2.Metrics
metric 是衡量在测试条件下的系统性能,默认情况下,会收集所有的内置 metrics 指标,如下图:
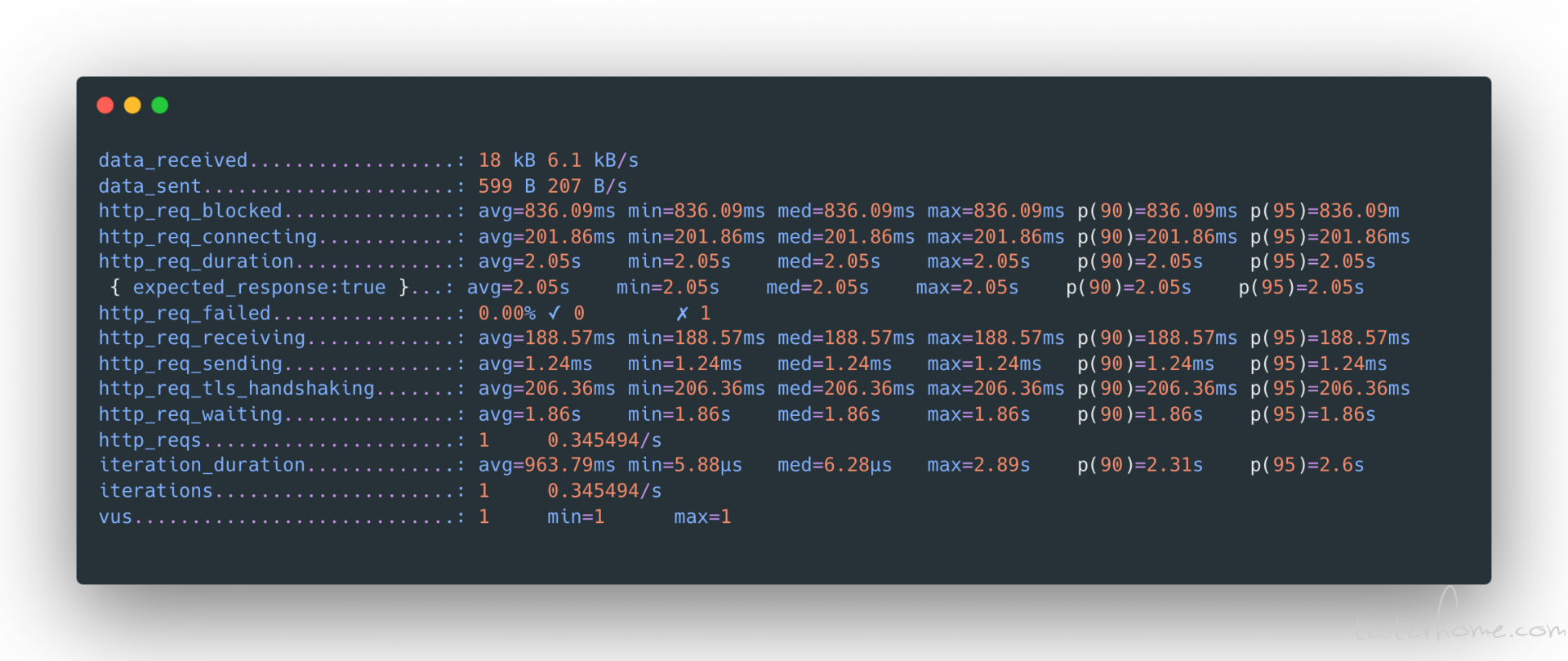
当然 K6 也支持自定义 metrics,可以在 VU code 执行阶段声明自定义的 metrics,可以获取某个支持数据的 trend,也可以获取某个支持数据的 counter,比如某个请求的错误总数,成功总数、相应时间,等待时间,数据接收时间的趋势,这样 K6 在执行结束后会按照声明的 metrics 输出相应的数据。
3. Thresholds
阈值通常是和 metrics 绑定使用的,K6 支持我们给需要监控的指标设置 thresholds,它能自动化的检查 SUT(system under test)的性能是否满足期望。比如某个 threshold 可以设定为:每个 request 相应时间都小于 200ms 或者小于 1% 的 request 会返回 error。我们可以根据 metrics 的数据自定义任何合理的阈值。测试执行中一旦不满足设定的阈值,那么测试就会以失败的状态终止。
Thresholds 编写格式
一个基本的 Thresholds 由 metrics-name 和 threshold-expression 组成的,前者很好理解,一般使用内置的 metrics 指标对应的名称,也可以使用聚合方法自定义对象使用。后面的语法是aggregation_method operator value其中聚合方法就是 K6 提供的四种,分别是 counter、trend、gauge、rate。
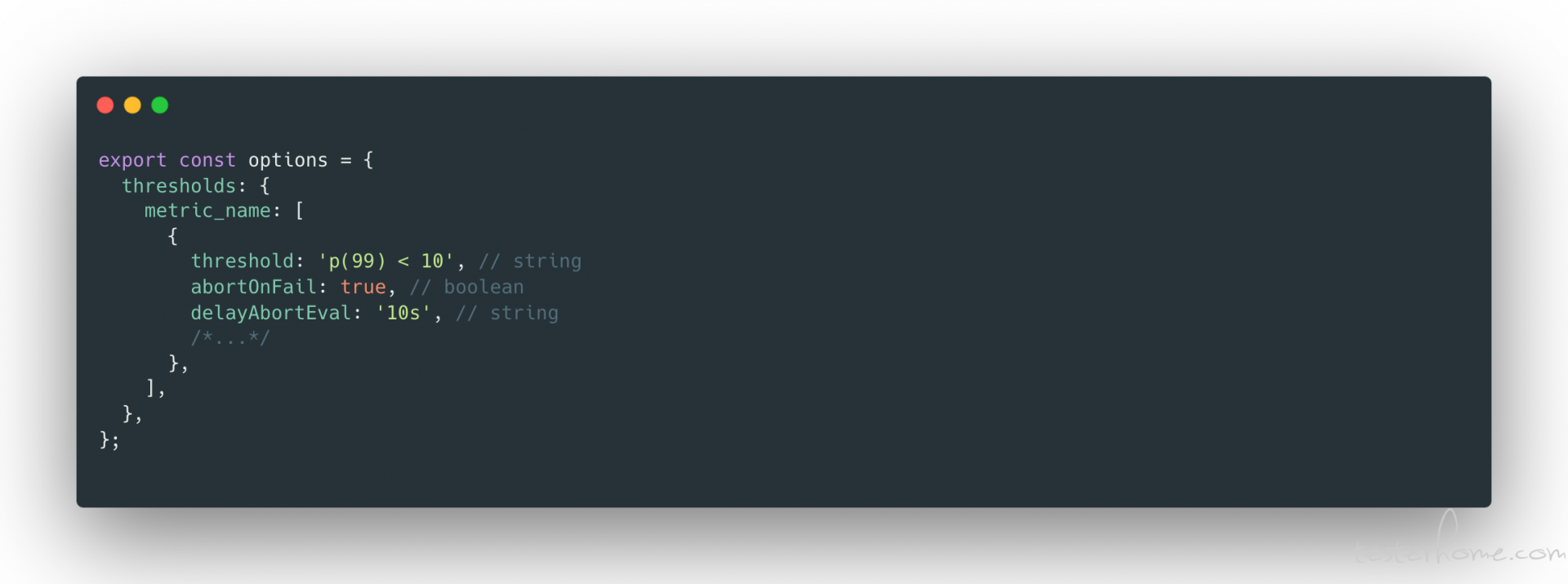
在 threshold 中使用 check
check 也是 K6 提供的一种断言方式,但是与 threshold 不同的是,check 并不会导致不满足预期停止测试这样的结果,所以如果只想作为断言而不影响整个测试的话,check 是一种很好的选择。
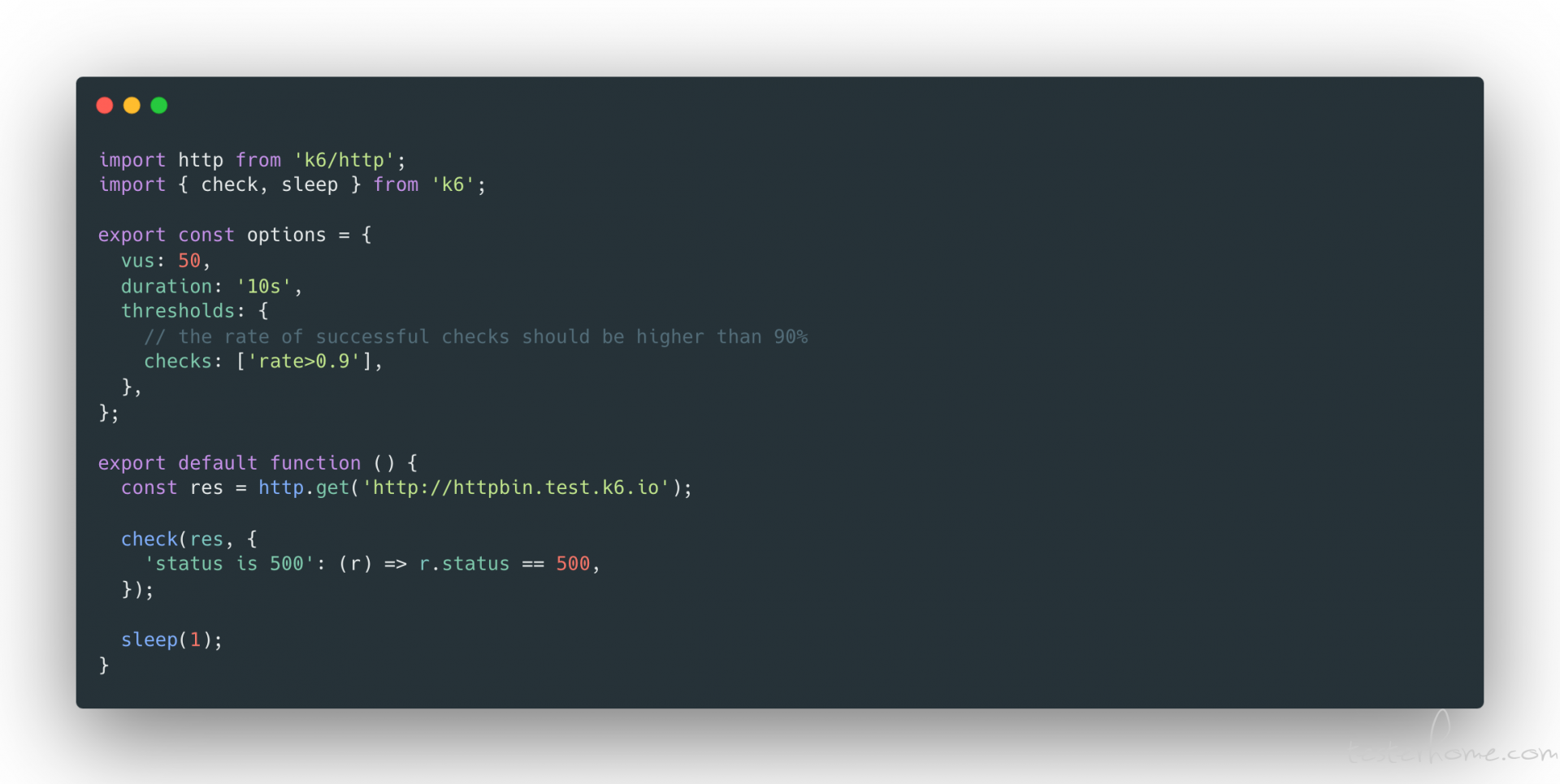
4. Options
K6 提供了很多方式增加配置选项,default --> config -->script options --> environment variables -->CLI flags,如果多个同时设置的话,对于 K6 而言,优先级时按照顺序递减的。PS(如果在命令行中直接添加 options,优先级是最高的)。通常情况下,script options 的方式是最常用且灵活的,options 作为一个 object 设置在脚本中,程序运行的时候再去读取。
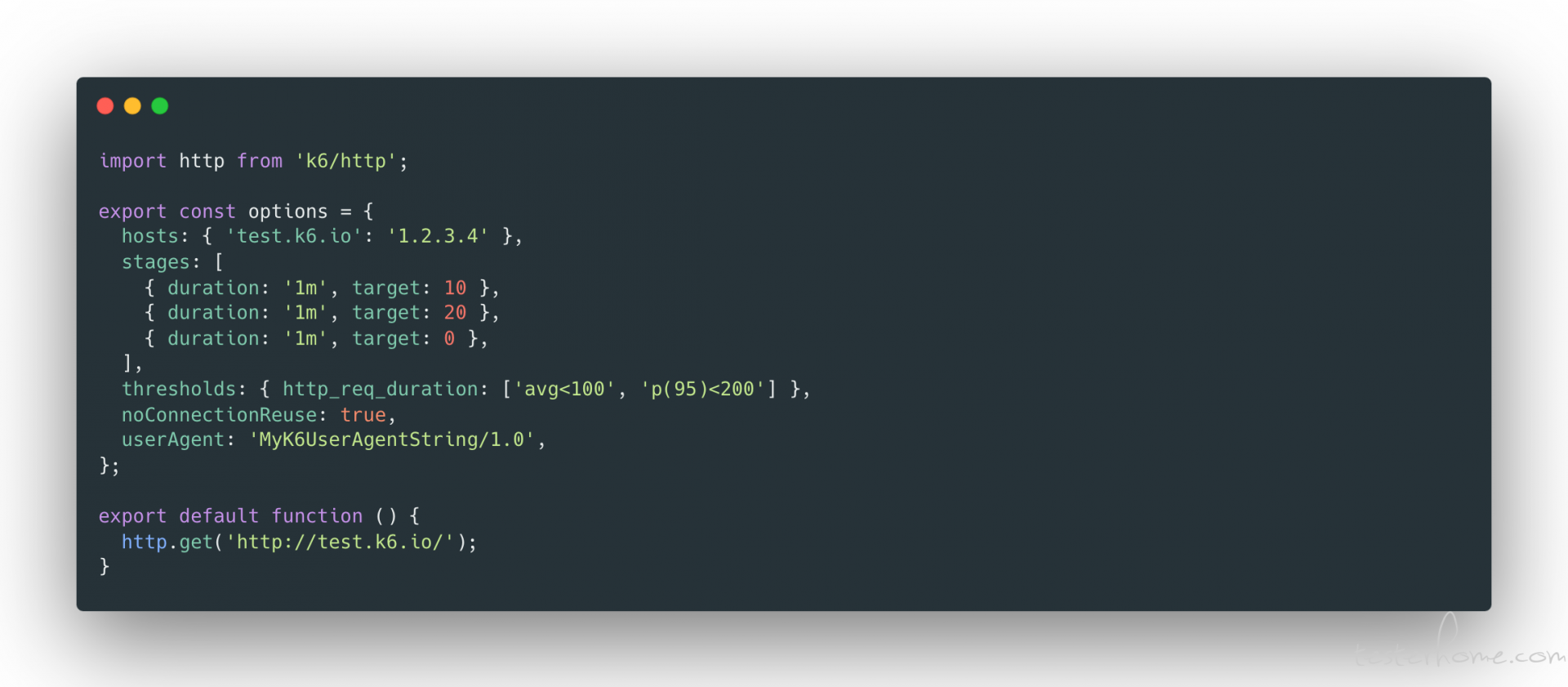
5. Scenarios
scenarios 功能是 K6 框架的一大亮点,使用的时候很灵活方便,我们可以更简单的组织我们的测试以应对不同的业务场景。不同的场景间可以自定义 VU 数量,duration time 等各种指标以满足测试需要。同时不同场景间是可以定义并行还是顺序执行的,不同的场景可以设置只属于该场景的 metrics 和 tags。
scenarios 配置的几个要素
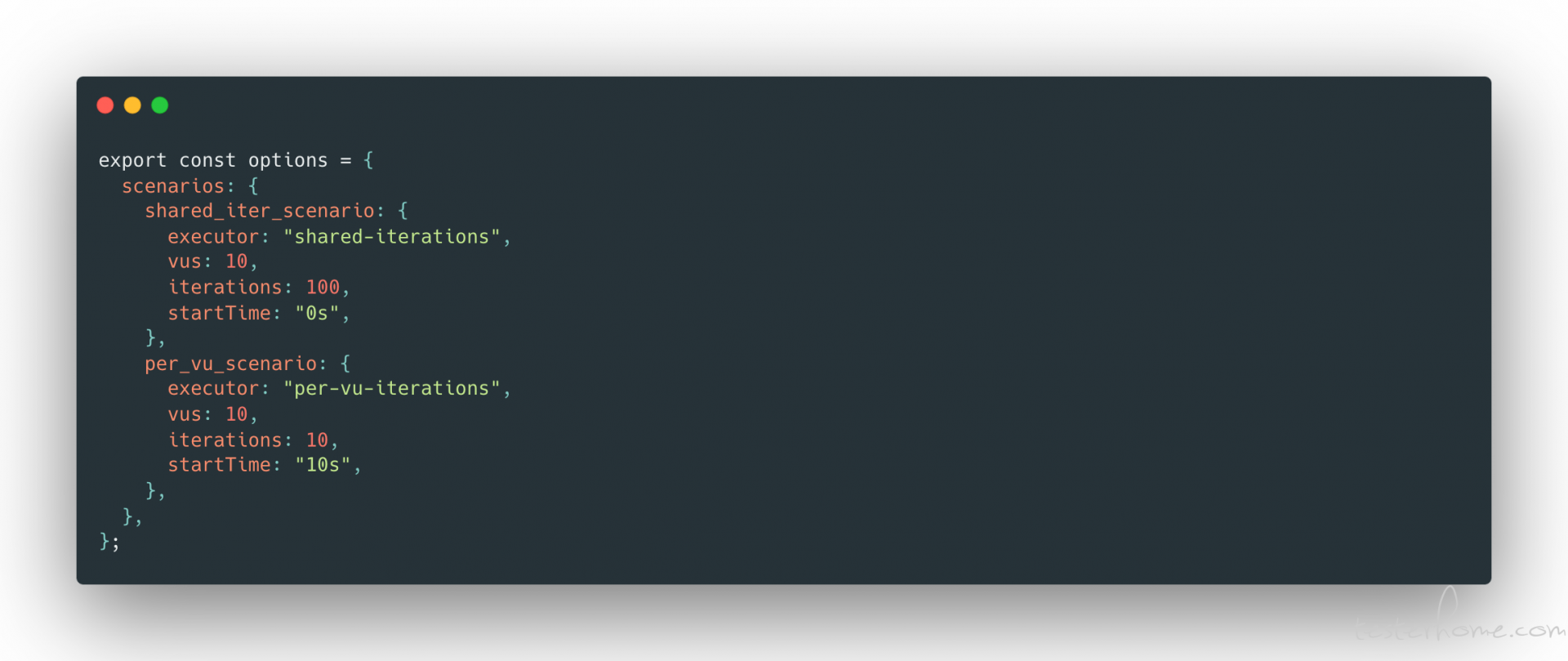
executor:必须的值,定义执行者类型,不同的 executor 有不同的效果,比如 Constant VUs 就是 VU 数量不变的情况下在一定的时间内执行尽可能多的 iteration,Ramping VUs 就是可变的 VU 数量在一定时间内执行尽可能多的 iteration。shared- iterations 是 iteration 在一定数量的 VU 间共享,不保证 VU 的分配,会导致执行快的 VU 执行了更多的 iteration。如果想要合理的分配就要使用 Per VU iterations,每个 VU 都有自己要执行的 iteration 数量。
vus:虚拟用户的数量。
itrations:迭代次数。
startTime:测试开始后的时间偏移,默认是 0s。
K6 项目中用例的通用结构设计
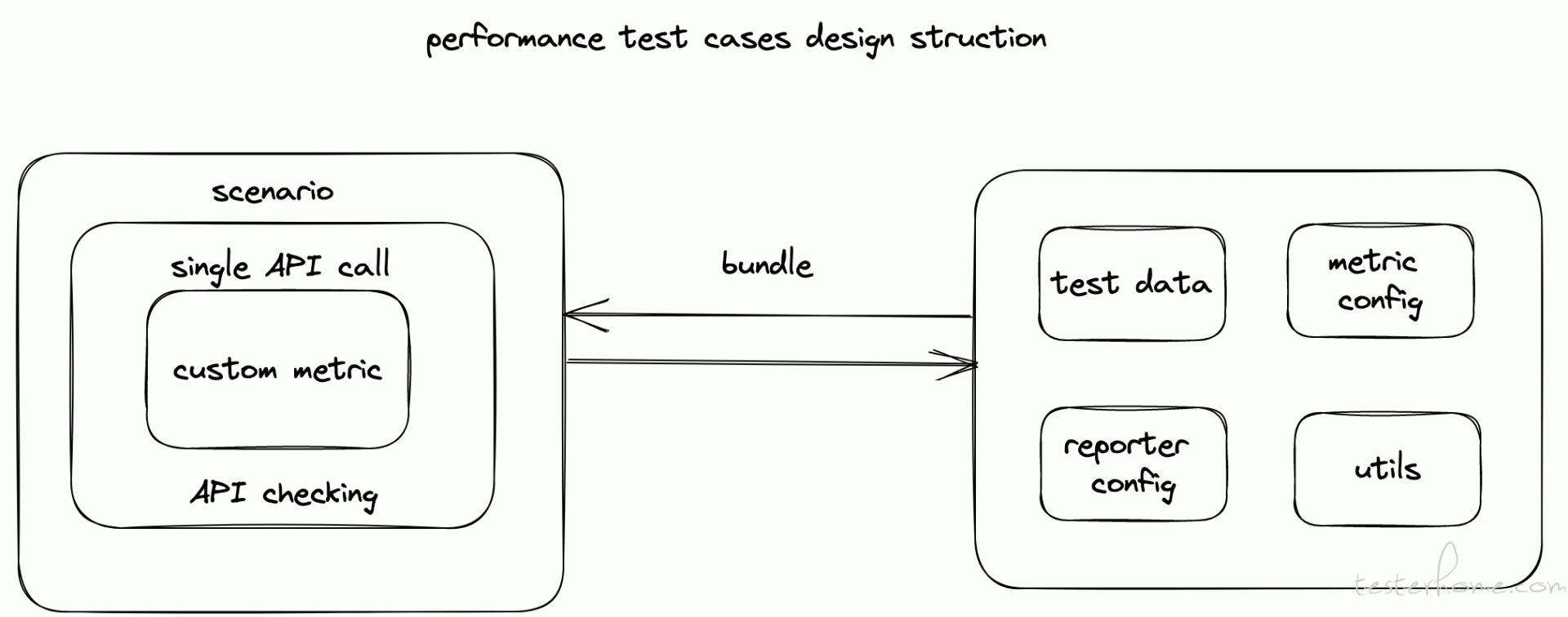
如果是单个 API 的性能测试,那直接采用基本的用例结构,将单个接口的调用写在 default function 中,配置相应的 option 执行即可。如果是多个 API 组合成的业务场景,那就使用 scenario,单个 API 的调用逻辑写在相应的文件中,然后由场景进行组合形成用例。测试数据、metrics、reporter 和 util 这些辅助测试的数据也单独成文件进行管理。这样辅助测试文件和场景用例组合在一起就形成了一个合理的项目结构了。demo 传送
测试阈值
测试阈值的选择是做性能测试不可避免的一个重要环节,从测试类型来看一般存在三种方式,每种方式的数值选择都不同。第一种是想要验证系统性能能不能满足实际的业务需求,这种一般称为负载测试。第二种是在不断的加压下想要得到系统的性能上限,一般称为压力测试。第三种一般是关注于系统一定压力下的长时间运行,一般称为浸泡测试。负载测试需要我们根据实际业务来判断,可以访问终端用户或者在 prod 环境数据作为参考来设置不同场景的性能测试环境以及数据量。压力则是多次进行实验,梯度加压直到系统处理上限,最终得到一个数据量。浸泡测试是基于一定的数据量,这个数据量可能是平均值也可以是中位数这样子能代表整体的数据,然后经过长时间的测试,最终得到系统在长时间的压力下所产生的性能和可靠性问题。
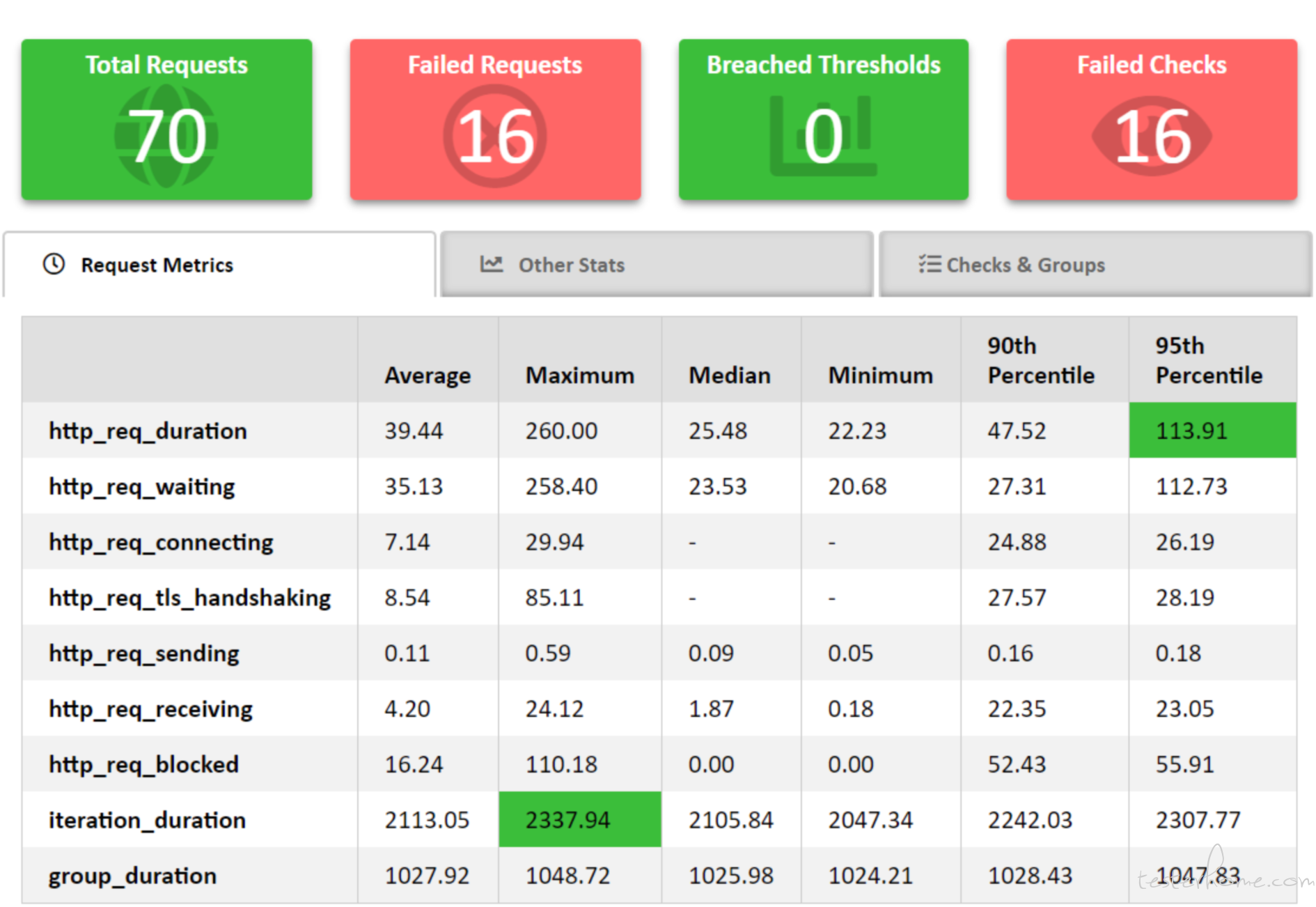
测试结果
测试报告
K6 本身是没有图形化界面的测试报告的,它的测试结果只是以一种标准的格式输出在控制台中。为了能够适配不同的需求,我们可以使用 K6 的拓展来完成测试结果的图形化,比如 HTML 的报告就可以使用https://github.com/benc-uk/k6-reporterhandleSummary() 以一个 object 的方式接收测试结果然后进行相应的处理。,它的原理是使用