前言
我们经常会说互联网 “三高”,那什么是三高呢?我们常说的三高,高并发、高可用、高性能,这些技术是构建现代互联网应用程序所必需的。对于京东 618 备战来说,所有的中台系统服务,无疑都是围绕着三高来展开的。对于一个程序员,或多或少都能说出一些跟三高系统有关的技术点,而我本篇文章的目的,就是帮大家系统的梳理一下三高系统中的第一高:高可用性。
首先来说,互联网的业务特点决定了他必须保证 “三高”, 同时,高并发,高可用,高性能,这三高之间并不是孤立的,而是强相关。一个高可用的系统,一定也需要应对高并发场景对系统带来的冲击,保证系统在高流量访问情况下,系统的服务的正常运转。同时,一个能够支撑高并发的系统也一定要满足高性能,否则也无法实现高流量的承载。
回到我们本文的主旨,我们这里所说的高可用性是指,系统在遇到任何困难的情况下仍能正常运行的能力。
在京东 618 备战期间,系统的高可用对我们来说至关重要,因为系统的崩溃,不止带来直接经济上的损失,还会导致用户信任的丢失。接下来我通过一张思维导图展开我的分享,帮大家梳理一下一个高可用系统所需要考虑的技术点。
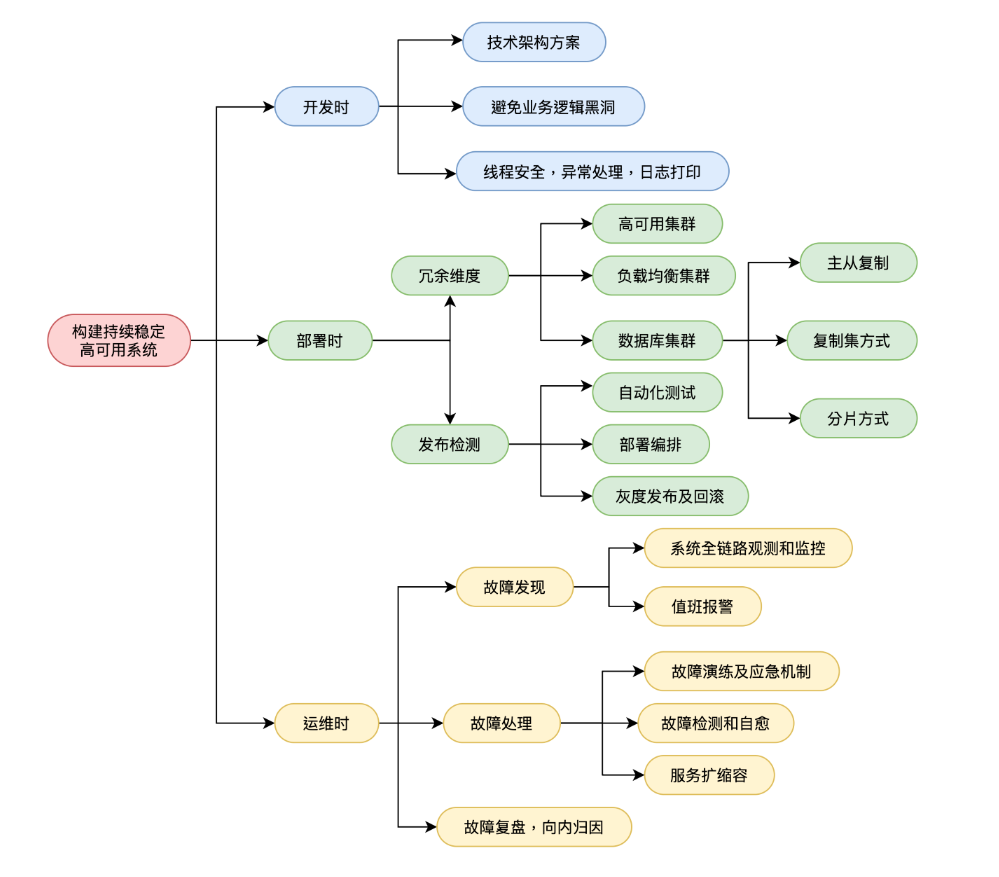
开发时
1. 首先技术架构方案选型很重要,切记避免过度设计。
比如我们常说的单体应用架构和微服务架构,两种架构单纯来对比,单体应用架构的可用率要比微服务架构高的。因为多服务之间的依赖一定会降低系统的可用率,比如一个依赖 10 个微服务的对外接口,假设每个服务的可用率是 99%,那么这个接口对外提供服务的整体可用率就直接降到了 90.4%,这中间还要考虑到服务之间的网络延迟,数据一致性的问题。
还有例子就是中间件选择,比如一个缓存业务场景,我可以用内存缓存,也可以使用 redis 分布式缓存,那么使用哪个呢?使用内存缓存系统可用率会高,因为如果引来 redis,系统的可用率又得乘以一个 redis 的可用率。当然如果我们的业务场景必须使用 redis,那么也是完全可以的,但这里切记系统的过度设计,也是设计复杂的系统,也需要更多的高可用相关的保证,所付出的资源代价和运维代价也是几何增长。
2. 其次就是代码质量。
其实这个可能是很多人忽略的一点,因为很多人更喜欢高谈阔论分布式,集群,压测,故障演练等等,但在我看来,一个代码开发质量的好坏,或者说一个程序员对代码的掌控力,对系统可用性起到至关重要的作用。以下举几个代码维度的例子。
第一个就是异常处理。一个代码质量的好坏,要看他对异常处理能力,一个本科生的课程设计代码,可能都是主业务逻辑,一条路写到黑,不考虑任何异常情况,而一个毕业几年的程序员,经历过线上业务的拷打,可能会用在代码里找到很多的 try-catch,用于捕捉各种不确定逻辑,而一个资深程序员,反而他的代码里你看不到任何 try-catch, 因为他全部用 AOP 的方式实现了异常的捕捉。这就是代码维度的考量,一个优秀的代码,一定是防御式编程,同时还会配合单元测试等。
第二个讲述一个什么是对代码的掌控力。在大厂里,你更多场景是接手别人的老代码。想必所有程序员都深有体会,接手别人的老代码是一件极其痛苦的经历,尤其是别人写了一半的代码。老话前人种树后人乘凉,但在程序员圈,前人种树,后人只能凉凉了..... 调侃归调侃,但有些事情需要面对,前期你需要对业务场景和代码逻辑进行抽丝剥茧的梳理,这个很重要。如果你无法对老代码进行充分熟悉,那么你就不敢去改写和重构它,如果在不熟悉的前提下贸然修改代码或者配置,然后上线,那么很大几率会带来线上系统问题,影响系统可用率。换一个角度来说,我们写的代码未来也可能交接给别人,如何不让别人痛苦,也是我们的责任。所以合理使用设计模式,遵循代码规范,书写代码架构和设计文档,这些也是很重要的一点,他的重要可能会关乎系统未来的可用率。
对于代码开发这块,京东技术平台也沉淀了一些自己的经验。内部有自己的 java 代码开发规范说明文档,也在京英学习平台上可以进行考试。而京东的 coding 平台,可以在你代码提交时,配置代码开发规范扫描和代码安全性扫描,同时,可以配置代码评审人,这些都可以用来提升我们代码质量。
部署时
1. 冗余性和备份
在部署维度,我们首先考虑的是冗余性和备份设计,这个可能是大家已经很熟悉的情况了,我们可以通过集群的方式,多个服务器、磁盘或者网络接口来减少故障点的数量。说到集群,根据实现方式和目的不同,我帮大家梳理一下集中集群类型:
(1)高可用集群。
有多个独立服务器组成的系统,旨在提高系统可用性,当主节点出现故障时,通过失败转移(Failover)让备用节点自动接管服务。这个我们常见的有 zookeeper 集群,etcd 集群等等,这类集群是基于共识算法实现的, 通过选举的方式,来保证当主节点故障时,可以有自动备份节点自动接管。
(2)负载均衡集群。
在负载均衡系统中,流量被分散到多个服务器中,每个服务器都独立地处理请求。当一个服务器负载过高或出现故障时,请求会自动被转移到其他可用的服务器上,从而保证系统的可用性和性能。负载均衡可以在多个层面上实现,包括应用层、传输层和网络层。在应用层负载均衡中,负载均衡器通常通过 HTTP 代理来分发请求,并根据请求的特定属性(例如 URL 或 Cookie)进行路由。在传输层负载均衡中,负载均衡器通常在传输层(例如 TCP 或 UDP)上运行,并根据端口号或其他特定协议进行路由。在网络层负载均衡中,负载均衡器通常是一个独立的网络设备,用于在不同的服务器之间分发网络流量。
(3)数据库集群。
这里的数据库可以理解为广义数据库,就是数据的存储媒介。对于数据库的的集群实现方式,分为如下几个:主从复制,复制集,分区。
关于这几种实现方案,这里可以 elasticsearch 举例说明。ES 有分片和副本的概念,所谓的分片,就是将数据水平划分到多个节点,每个节点存储部分数据,当查询数据时,需要在多个节点上进行查询,最后将结果合并。分区可以实现数据的高可用性和可扩展性,但需要考虑数据一致性问题。
同时 ES 的每个分片都可以配置多个副本,副本跟主从复制类似,或者说更像一个集群内的高可用子集,允许多个副本实例同时存在,并支持自动故障转移和成员选举,保证了数据的高可用性和负载均衡。
此外,对于集群方案来说,还要额外考虑多机房部署问题,异地多活。换句话说,我所有服务实例,不能放在一个篮子里,因为网络的抖动和不稳定性,对系统可用性来说是很大的威胁。
2. 发布检测
在部署维度,第二个关键点是发布检测。有统计数据表明,我们大部分的稳定性问题来源于系统变更,也就是系统的发布上线。那么如何保证一个平稳的系统上线呢?
首先,要完善自动化测试和单元测试,每次发版前,必回归测试,当然这块如果交给人工来做,费时费力,不一定能起到他的效果,所有说,完善的自动化测试流程,对于系统稳定性部署来说,至关重要。
其次就是做好发布的自动化,在发版过程中,减少人为参与,这样也就减少了出错的可能性。京东的行云部署本身就支持部署编排,利用部署编排,可以稳定且高效的实线滚动发版。同时也可以在行云上的流水线中配置 CI/CD 流程,实现继续集成和持续部署的串联。
最后就是要实现发版的可观测,可灰度,可回滚。发版前要有 checklist,发版时采用灰度发布验证的方式,可以降低因为发版引起的线上故障。最后如果发版发现失败,可以实现快速的回滚操作。这个就要在发版前的 checkList 里,做好回滚流程的备案。
运维时
在运维时,我们的目标是能够快速止损线上问题,做到问题早发现,快定位,速解决。
1. 系统全链路观测和监控
在互联网系统中,从用户请求开始,经过所有的系统组件或服务,直到响应返回给用户,对整个系统的性能、稳定性和可用性进行全面观测和监控的过程。这包括了对硬件、网络、存储、软件等方面的观测,监控。
在京东 618 备战期间,所有应用系统都必须完成自建,完善 UMP 监控埋点,对核心接口方法的可用率,TP99,调用量进行实时监控,同时,也对需要对云主机,中间件等资源维度,包括 CPU,内存,资源占有率进行实时监控。
此外,针对监控,要做好日志监控做好采集工作,因为日志记录了系统中各个组件或服务的运行状态,可以提供丰富的信息用于问题排查和分析。
在京东内部采用 logbook 进行日志采集,对于核心业务需要审计留存的,可以单独搭建 ELK,将历史日志存入 ES 中。
2. 值班与报警。
针对 618 备战期间,需要额外安排固定人员进行每日值班,做到对线上问题可以及时反馈。
针对报警机制,有一点需要切记,要把握好报警的阈值问题,如果阈值偏低,会导致研发人员频繁收到报警,导致警惕性降低。而如果阈值偏高,会错过一些线上问题,导致问题没有及时发现,致使故障扩大化。
3. 故障演练及应急机制。
京东内部有两大利器,一个是 ForceBot,一个是 Chaos Monkey。
前者是做全链路军演压测用的,一般 618 大促前要进行三次军演压测,通过这些军演,让各个应用系统发现系统中的薄弱点,并针对性解决。forcebot 是通过部署在全国各地的 CDN 节点,模拟真实用户发起的大规模访问流量,这种接近实战的压测,可以让我们做到防患于未然,同时,通过压测,可以针对性的优化服务资源,能够更针对性的进行扩容。
第二个我们有时候会叫猴子捣乱测试,也会叫混沌测试。它能够通过模拟包括网络,中间件,流量等在内的各种故障,通过故障的随机注入,来演练我们对系统故障的反应能力。
这里就该提到所谓的应急机制。该机制就像一本类似医院给发的急救指南手册,需要在日常做到对各种不确定的故障进行反应能力。比如遇到突发高流量,系统出现了熔断,如何快速扩容云主机和各类中间件资源;比如网络突然发生延迟,接口请求超时情况下,如何做好降级方案等等。
总结
本文写于京东 618 备战开门红前夜值班之时。
以上的所有关于系统高可用的总结,都源于一次次的前人的实践经验总结出来的。每次备战略细节有不同,但大的方向原则是不变的。
祝:京东 618 大麦。
作者:京东物流 赵勇萍
来源:京东云开发者社区