持续交付要求团队能够快速、频繁、高质量构建可运行的产物以响应业务的快速变化,抓住瞬息万变的市场需求。谁能够更快的响应客户变化,交付客户满意的产品成为了公司最重要的核心竞争能力之一。Agile、DevOps 成为了让持续交付变成可行的重要实践之一。DevOps 三步法为落地 DevOps 提供了指导方针:
法则一:从左至右构建 “流水线”,通过流水线提高“流动”效率及时发现 “部署” 过程中的问题。比如:通过流水线构建一键自动编译、测试、打包、部署、发布 (一般手动) 等。
法则二:从右至左构建“快速反馈”机制,通过在流水线上设置质量门禁,保证每一个阶段运行到下一阶段之前达到质量门禁的最低阈值。比如:代码静态扫描、单元测试通过率、代码覆盖率、安全扫描、集成测试通过率等。
法则三:“持续学习” 以提高团队整体战斗力和减少过程中的 “浪费”。比如:通过结合敏捷中的实践让项目交付过程更加顺畅,例如:Scrum、Kanban、SAFe 等。
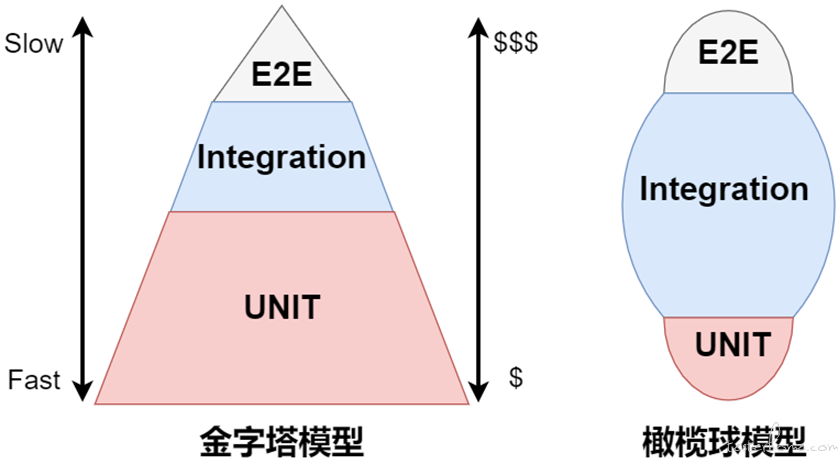
大多数的情况下大部分公司都能够建立 “法则一”,搭建流水线完成软件的编译、打包、部署的过程。但是仅仅完成从左至右的流水线并不能交付高质量的软件,流水线虽然加快了软件的发布速度,然而最终达到用户手中软件质量参差不齐,影响了用户的体验。在 “持续交付” 一书中提倡通过 “自动化测试” 构建快速反馈,保障每次流水线的每个阶段都能达到质量门禁要求。实施自动化测试会投入大量的成本,在项目管理中需要平衡质量的投入产出比。Mike Cohn 的《敏捷的成功》(Succeeding with Agile) 一书中提出了自动化测试金字塔模型,用于衡量自动化测试的投入产出效益,其中将自动化测试分为三层 “UI、API、Unit”。大部分公司的项目也会采用分层自动化测试以控制投入产出效益,然而大部分自动化测试仅仅是采用了传统的 UI、API、Unit 分层对软件进行测试,实际编写的测试用例都是基于 “端到端” 或者 “服务端测试”,而非真正的分层自动化测试,导致分层自动化徒有其表而无其实。使用传统的方式开展自动化测试带来了很多重复性工作,拉长了流水线的反馈机制,排查问题更加困难。传统的 “分层自动化测试” 不在成为提效的 “资产”,反而臃肿难以维护的自动化测试用例正在成为团队的 “负担”。
背景
随着 DevOps、敏捷、微服务的发展,产品的迭代速度越来越快,“速度” 与 “质量” 经常被视为互相矛盾点。由于业务逐渐服务化,导致微服务野蛮生长。企业在实施传统的分层自动化测试也由 “金字塔模型” 转变为 “橄榄球模型”。由于 UI、API 自动化测试都需要依赖被测系统正常运行,且经常出现由于测试数据、环境 (前端、后端) 部署、用例依赖等原因导致自动化测试执行失败。即使环境正常的情况下由于测试用例的数量由开始的核心场景覆盖延伸到各个分支覆盖,数量成几何指数的倍增,带来了测试用例执行失败定位问题极为困难。基于这种背景下衍生出了对 “分层自动化测试” 更加深入的思考。
自动化测试与缺陷生产率
金字塔模型中指出自动化测试策略应该首先将更多的测试投入到底层 “单元测试”,其次是 “集成测试”,最后是 “端到端测试”。然而当前微服务现状中,企业将自动化测试更多放在 “集成测试 (API 测试)” 环节,这也是接口测试最近几年爆发式增长原因之一。
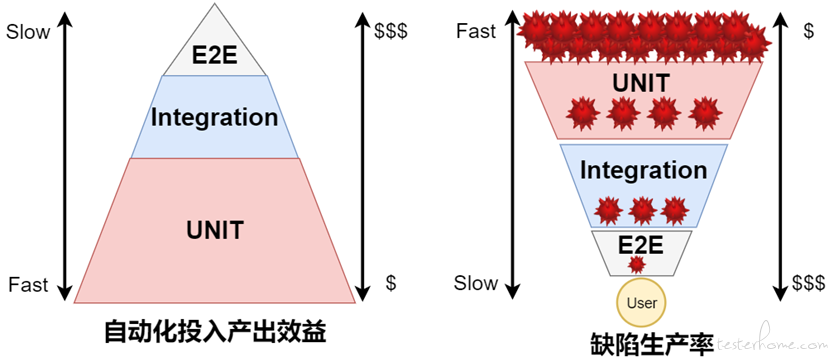
从 “缺陷的产生率” 倒三角模型来看,缺陷更多产生在 “单元级别”,而且在单元级别修复缺陷的成本更低、效率更高。通过从单元层面消灭缺陷使得 “集成/端到端测试” 缺陷会明显减少,而且排查问题的效率也更。特别是当需要对代码模块进行重构或重新设计时单元测试是保证质量的最重要手段之一。从单元级别解决缺陷是最快的反馈机制,执行效率也最高,结合 “测试替身 (Test Double)” 等技术进行依赖的隔离能降低单元之间的依赖性,提高测试用例的执行成功率,使得持续测试变为可能。
何为分层自动化测试
在有了持续交付、自动化测试等基本理念之后,我们梳理一下分层自动化实施的具体方法。传统的 “集成测试” 更多是通过调用 “接口” 来完成自动化测试用例设计,而并非是单独测试 “接口” 本身。通过调用 “接口” 完成整个后端的业务逻辑测试与 “UI” 自动化测试相同都需要依赖整个后端服务器被正常的加载,且环境 “初始化” 成功。当实施 UI、API 自动化测试时,团队经常会有一个疑问?为什么 UI 自动化已经保证了业务核心流程的正确性,还需要在通过 API 测试进行 “重复” 的用例开发?从代码覆盖率角度而言,相同的代码逻辑被不用的测试类型覆盖确实没有什么意义。这也引发了对于测试策略的思考,手工、UI、API、Unit 应该如何去分配资源。通过合理的测试策略的划分减少测试过程种的浪费,这也是DevOps 三步法则之三 “精益” 思想的体现之一。长链路的测试带来测试设计上的难题,比如:用例之间的依赖、测试数据的依赖、环境的依赖等,虽然这些问题都可以通过 “工程化” 方式得以缓解,但是测试用例执行效率、如何精准发现被测代码具体问题依然没有能有效的解决,导致流水线执行失败时排查 “用例问题” 或 “被测代码问题” 的效率极其低下。
这里以一个缺陷管理平台为例讲解 “传统分层自动化” 与 “分层自动化” 区别。前端技术栈为 Vue.js, 后端技术栈为 SpringBoot,平台技术架构如下图:
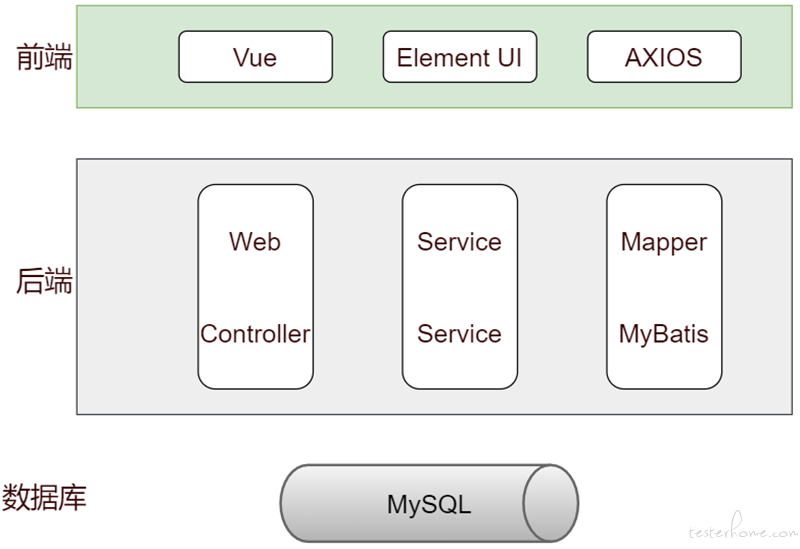
针对上图的技术架构如果要进行分层自动化测试,测试大致可以分为前端测试、后端测试和集成测试。需要注意的是实际项目种后端往往是微服务架构。
前端测试
传统的分层自动化测试对 UI 层更多的是使用 Selenium、Playwright、Nightwatch 等 “外置驱动” 的方式开展自动化测试,比如:启动浏览器,进行模拟用户真实的操作。而分层自动的思想是通过 “内置驱动” 的方式通过测试代码驱动研发代码的方式开展自动化测试。前端工程通过分层技术进行拆解之后可以达到独立隔离测试前端以提高持续测试的成功率。以 Vue 项目为例,分层自动化在前端测试时会将自动化测试分层三个层面。函数级别 JavaScript、组件级别 component、端到端级别 End-to-End。在每一次层测试的重点及使用的技术栈不同。函数级别的测试通常会使用单元测试框架 jest 对函数本身进行测试,通过 “测试数据” 调用函数验证函数的执行逻辑是否符合预期,对于函数内部的调用链通过 jest.mock() 完成隔离;组件级别的测试通过 Vue 官方的 Vue Test Utils 工具对组件进行浅渲染(shallowMount)只渲染组件的第一层 DOM 结构,其嵌套的子组件不会被渲染出来,从而使得渲染的效率更高,单元测试执行的速度也会更快。UI(E2E,端到端)自动化测试通过 Mock Server 作为前后端挡板可以实现无需启动后端服务器即可完成前端的 UI 自动化测试,极大的提高了 UI 自动化测试的稳定性,当然UI 自动化测试本身也依赖于被测代码的规范性。通过分层自动化使得前端分层测试职责更加明确,也减少了外部依赖。关于函数、组件、端到端,其投入的测试比例可以参考 “测试金字塔模型”。前端分层自动化测试拆分之后如下图所示:
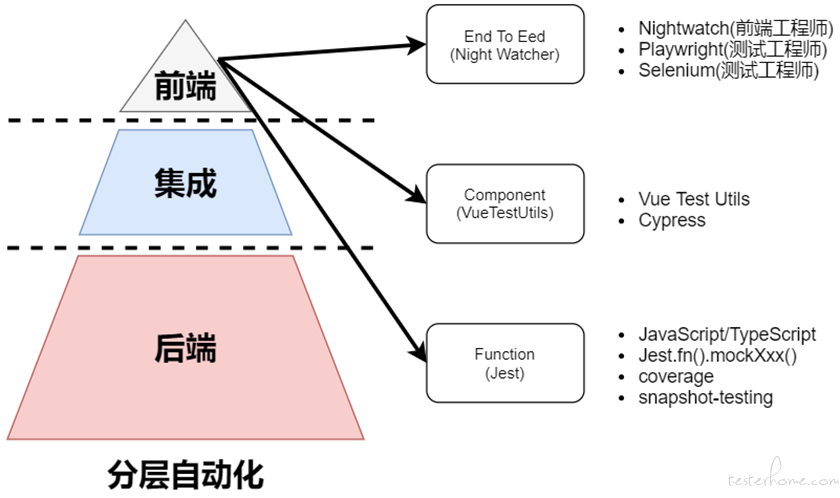
-
函数测试:通过给定的一组数据校验输入、输出是否符合预期结果,及函数执行是否对其他资源产生了影响。比如:使用 JavaScript 单元测试框架 Jest 进行函数的测试。Jest 可以理解为与 JUnit 5 具有相同的作用。Jest 功能更加齐全,比如:内置函数 mock、代码覆盖率、快照测试等特性。Jest 支持前端主流框架,比如:TypeScript, Node, React, Angular, Vue 等等。使用 Jest 进行单元测试示例代码如下:
/** * 使用 Mock 函数定义 Mock 函数的实现体 */ test('Test Mock function implements', () => { let sum = jest.fn().mockImplementation( () => { console.log('mockImplementation function be invoked!') return 'Miller_' + 30 + '_Male' } ) expect(sum(1, 2, 3)).toMatch(/Miller/) }) -
组件测试:在 Vue 项目中组件就是一个个.vue 文件,组件包含三大块内容,HTML< template>、CSS< style>、Function< script>。通过模拟行为验证组件的函数、数据、事件是否正确。而不是像单元测试那样直接调用函数验证函数和数据的正确性。相对与单元测试,组件测试需要加载更多的代码进行测试。对于组件的测试通常还需要隔离组件与组件之间的依赖,以及 Mock 组件内部的网络请求等。在 Vue 项目中可以通过 Vue.extend 渲染组件,然后通过构造器挂载组件获取浏览器上下文对象。示例代码如下:
import Vue from 'vue' import HelloWorld from '@/views/HelloWorld' describe('HelloWorld.vue', () => { // Vue 创建工程是自带的测试用例 it('should render correct contents', () => { // 通过 Vue.extend 渲染 HelloWorld 组件 const Constructor = Vue.extend(HelloWorld) // 获取浏览器上下文对象 vm, 这个 vm 对象包含了 HelloWorld 组件的所有信息 const vm = new Constructor().$mount() expect(vm.$el.querySelector('.hello h1').textContent) .toEqual('Welcome to Your Vue.js App') }) })
也可以通过官方的 Vue Test Utils 工具包对组件进行测试,其支持浅渲染(shallowMount)的特性,可以只渲染组件的第一层 DOM 结构,其嵌套的子组件不会被渲染出来,从而使得渲染的效率更高,单元测试执行的速度也会更快,使用 VueTestUtils 工具包测试组件示例代码如下:
// 导入Vue Test Utils 工具库
import {shallowMount} from '@vue/test-utils'
import HelloWorld from '@/views/HelloWorld'
describe('TestSuite_HelloWorld', () => {
test('TestCase_CheckChangeData', () => {
// Given...测试用例初始化的条件和初始状态
const wrapper = shallowMount(HelloWorld)
// When...执行动作
const message = wrapper.vm.$data.msg
// Then...断言动作带来的结果
expect(message).toMatch('Welcome')
// 修改 data 属性内容
wrapper.setData({msg: 'Miller'})
expect(wrapper.vm.$data.msg).toMatch('Miller')
})
})
-
端到端测试:以自然人类的操作方式对被测系统进行模拟点击、输入等行为,校验系统是否符合预期结果。通常这种测试需要依赖被测系统的稳定性,需要使用完整的真实环境进行测试。Vue 创建完之后默认端到端测试工具为 Nightwatch。如果你是一个前端工程师那么使用 Nightwatch 是个不错的选择,它可以将测试代码打包到工程中,方便进行代码协作、版本管理是个非常好的实践,其底层使用的是 selenium 作为测试驱动框架。示例代码如下:
module.exports = { 'e2e_Login_Page_CheckElement': function (browser) { // 使用 nightwatch.conf.js 中的默认地址和端口 const devServer = browser.globals.devServerURL browser .url(devServer) .waitForElementVisible('#app', 5000) .assert.containsText('h3', '持续测试-分层自动化') .assert.elementCount('h3', 1) .end() } }
如果你是一个测试工程师那么推荐使用 Playwright 进行端到端的自动化测试,它支持一些很方便的特性能够快速、稳定的构建自动化测试用例,比如:智能等待、录制、运行中调试、回放等特性。示例代码如下:
@DisplayName(value = "Playwright测试端到端用例集")
public class PlaywrightEndToEndTests {
@DisplayName("测试添加缺陷流程")
@Test
public void testAddIssueFlow() {
// Given.
try (Playwright playwright = Playwright.create(options)) {
BrowserType.LaunchOptions launchOptions = new BrowserType.LaunchOptions().setHeadless(false).setSlowMo(200);
// When.
Browser browser = playwright.chromium().launch(launchOptions);
// 启用追踪功能,这样可以在运行自动化脚本之后查看整个执行的过程
BrowserContext context = browser.newContext();
context.tracing().start(new Tracing.StartOptions().setScreenshots(true).setSnapshots(true).setSources(true));
Page page = context.newPage();
page.navigate(url);
// 定位元素
page.locator("#username").fill("admin@aliyun.com");
page.locator("button.el-button.submit.el-button--primary").click();
// 跳转到缺陷列表
page.navigate(url + "/issues/list");
page.locator("#addIssue").click();
page.locator("#issueTitle").fill("playwright test by Miller");
page.locator("#issueHandler").click();
page.locator("li[id=\"miller.shan@aliyun.com\"]").click();
page.locator("#submit").click();
// Then
assertThat(page.content(), Matchers.containsStringIgnoringCase("playwright test by Miller"));
// 暂停启动调试、录制模式
page.pause();
context.tracing().stop(new Tracing.StopOptions().setPath(Paths.get("trace.zip")));
}
}
}
通过以上技术方案可以实现前端的分层自动化测试,但是这里需要注意的一点是当执行端到端自动化测试时由于需要依赖后端服务正常运行,所以需要使用 MockServer 技术进行前后端隔离。
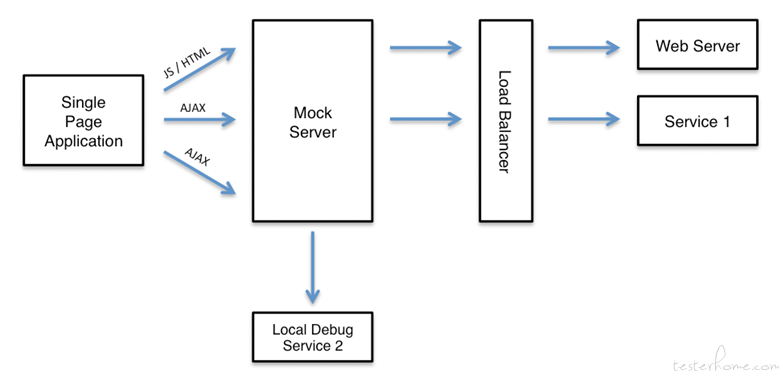
为了在端到端的自动化测试过程中正确断言,保证后台服务器处于正常运行状态是必备的,前端开发、测试往往会因为后端的实现进度而滞后,而由于团队中数据的公用也会影响效率。比较理想的前后端分离研发,后端在项目初期就已将表结构定义完成,配套生成了 Java Bean 对象,并且将接口定义完成,提供至少一个 Mock 的数据返回;前端可以根据 Swagger 自动生成的文档进行联调,随着后端接口的逐步完成,前端也与之同步,达到业务逻辑的同步实现。当出现前端需要一个新的接口,后端还没有该接口的定义和实体的开发时,前端可以根据原型设计进行前端静态页面的开发,通过使用 Mock 技术来访问一个非真实的服务端接口。通过使用 Mock Server 可以方便的模拟后端返回数据,协助验证前端逻辑。这样就可以在不依赖后端服务器,进行独立的前端开发及测试。其内部处理流程可以参考如下图:
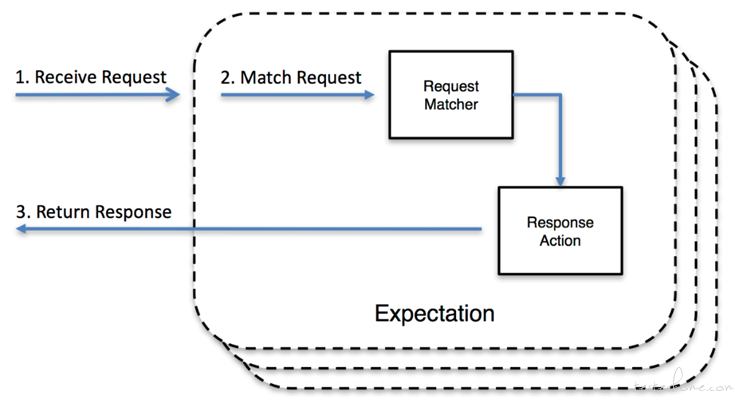
MockServer 不单单可以作为前后端隔离服务,而且也可以用于后端的微服务隔离,它不但支持 JSON 文件数据的方式作为响应数据,而且也支持代码的方式,比如:通过 JUnit 方式对微服务之前的调用进行隔离。也可以作为一个代理服务器用于代理负载均衡器 (比如 Nginx)。作为代理服务其状态流程如下图:
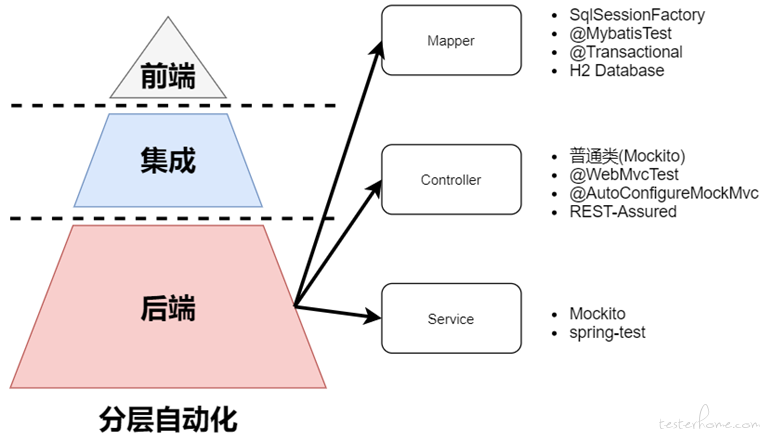
后端测试
后端根据被测系统的架构可以拆分为 Mapper、Service、Controller 等层测试,其分层策略大概如下图:
-
Mapper 测试: 对于 Mapper 层的测试更多的是关注与 SQL 语句的正确性,还有就是如果使用了动态 SQL 特性,那么需要校验不同分支的逻辑正确性。Mapper 测试可以使用 mybatis-config-test.xml 文件配置数据源,然后使用原生的 SqlSessionFactory 创建与数据库的 session 连接,进而完成 CRUD 的操作。这种方式的在于无需依赖 SpringBoot 即可完成 Mapper 层的测试。示例代码如下:
@DisplayName("使用纯Java代码测试Mapper层接口及Xml") public class CalculatorHasDBMapperTestByJavaCodeTests { private static SqlSession sqlSession; private CalculatorHasDBMapper mapper; @BeforeAll public static void beforeAll() throws IOException { // 从 mybatis-config-test.xml 读取 MyBatis 配置 Reader reader = Resources.getResourceAsReader("mybatis-config-test.xml"); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader); sqlSession = sqlSessionFactory.openSession(); } @AfterAll public static void afterAll() { sqlSession.close(); } @BeforeEach public void beforeEach() { mapper = sqlSession.getMapper(CalculatorHasDBMapper.class); } @AfterEach public void afterEach() { // 将修改提交到数据库,不提交则数据库不生效,如果仅仅只是测试 Mapper 接口可以不提交 sqlSession.commit(); } @DisplayName("测试Insert语句") @Test public void testInsert() { Calculator calculator = new Calculator(); calculator.setFirstNumber(1.0); calculator.setSecondNumber(2.0); calculator.setResult(3.0); Integer insert = mapper.insert(calculator); //System.out.println(calculator.getId()); // 断言影响的记录数据为1 assertThat(insert, Matchers.is(1)); } }
第二种方式是通过 MyBatis 官方提供的@MybatisTest注解测试 MyBatis,使用@MybatisTest注解会自动配置 SqlSessionFactory,并且自动配置一个内存数据库。使用@MyBatisTest注解编写的测试用例在测试结束时会自动进行事务的回滚,而且@MybatisTest运行时是不会加载其他的 Bean 组件到当前测试用例。
@MybatisTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
@DisplayName("使用@MyBatisTest测试Mapper")
public class CalculatorHasDBMapperTestByMyBatisTestAnnotationTests {
@Autowired
private CalculatorHasDBMapper calculatorHasDBMapper;
@DisplayName("测试Insert语句")
@Test
public void testInsert() {
Calculator calculator = new Calculator();
calculator.setFirstNumber(1.0);
calculator.setSecondNumber(2.0);
calculator.setResult(3.0);
Integer insert = calculatorHasDBMapper.insert(calculator);
assertThat(insert, Matchers.is(1));
}
}
第三种方式是通过 Spring 的事务功能进行 Mapper 的测试。使用 @Transactional 的方式数据并不会真实入库,可以理解为之前用纯 Java 代码的 SqlSession 的方式不做 commit,主键自增 ID 会被使用掉了,但数据会被回滚,这是事务的默认行为。
@Transactional
@SpringBootTest
@DisplayName("使用Spring的事务Transaction隔离数据")
public class CalculatorHasDBMapperTestByTransactionTests {
@Autowired
private CalculatorHasDBMapper calculatorHasDBMapper;
@DisplayName("测试Insert语句")
@Test
public void testInsert() {
Calculator calculator = new Calculator();
calculator.setFirstNumber(1.0);
calculator.setSecondNumber(2.0);
calculator.setResult(3.0);
Integer insert = calculatorHasDBMapper.insert(calculator);
assertThat(insert, Matchers.is(1));
}
}
第四种方式是使用 H2 Database 内存数据库,通过将数据源切换到 application-h2.properties 配置的方式让所有测试数据都指向内存数据库,通过会结合 flyway 一起使用,使用这种方式对于 SQL 语句的语法有一定要求。示例代码如下:
@ActiveProfiles("h2")
@SpringBootTest
@DisplayName("使用内存数据库H2")
public class CalculatorHasDBMapperTestByH2Tests {
@Autowired
private CalculatorHasDBMapper calculatorHasDBMapper;
@DisplayName("测试Select语句")
@Test
public void testSelect() {
List<Calculator> select = calculatorHasDBMapper.getCalculatorList();
assertThat(select.size(), Matchers.greaterThanOrEqualTo(0));
//select.forEach(System.out::println);
}
}
-
Controller 测试: 对于 Controller 层测试的重点应该关注于输入数据的正确性校验,以及返回数据的结构是否正确即可。因为 Controller 层调用的 Service 已经在 Service 层进行单元验证了。同理 Controller 层也是一个普通的 Java 类,所以我们可以通过 Mock 的方式把它当作普通类进行测试,但是这样就会丢失 HTTP 服务器的数据报文。将 Controller 作为普通 Java 类测试示例代码如下:
@DisplayName("测试计算器Controller层代码") @ExtendWith(MockitoExtension.class) public class CalculatorControllerTestByMockitoTests { @InjectMocks private CalculatorController calculatorController; @Mock private CalculatorServiceImpl calculatorService; // 测试数据 private Calculator calculator; /** * 直接调用 Controller 对象的方法,把 Controller 当普通类进行测试,而不是 HTTP 接口 @DisplayName(value = "测试Restful的POST方法,参数为JSON") @Test public void testPostMethod() { when(calculatorService.add(anyDouble(), anyDouble())).thenReturn(calculator); assertAll( // 构造POST方法请求参数, 第一种情况:传null () -> { String nullObject = calculatorController.testPostMethod(null); assertThat(nullObject, equalToIgnoringCase("Request body can't be empty.")); }; } }
第二种方式是使用 SpringBoot 中提供了@WebMvcTest 注解可以单独注入需要测试的 Controller,通过 MockMvc 模拟客户端发送请求到服务器,然后通过@MockBean注解 Mock 具体 Service 方法的行为,进而达到单独对 Controller 测试的目的。
package com.github.millergo.controller;
@WebMvcTest(value = {CalculatorController.class})
@DisplayName("Test CalculatorController by @WebMvcController")
public class CalculatorControllerTestByWebMvcTestTests {
@MockBean
private CalculatorServiceImpl calculatorService;
@Autowired
private MockMvc mockMvc;
private Calculator calculator;
@DisplayName("Test RESTFul GET Method")
@Test
public void testGetMethod() throws Exception {
// Stubbing, 隔离 Service
when(calculatorService.add(anyDouble(), anyDouble())).thenReturn(calculator);
// MockMvc 拥有 Client 能力,可以对服务器发送请求
ResultActions resultActions = mockMvc.perform(MockMvcRequestBuilders.get("/calc/add/1/2"));
resultActions.andExpect(MockMvcResultMatchers.status().isOk())
resultActions.andDo(MockMvcResultHandlers.print());
}
}
对于Controller 层的测试推荐使用@WebMvcTest注解进行测试,当然使用@SpringBootTest、REST-Assured 等其他方式也支持测试 Controller。
-
Service 测试: Service 层测试是整个后端最重要的测试层,其关乎后端系统业务的正确性,在实际项目中大部分的后端测试都是在校验 Service 的正确性。目前大部分团队在进行 SpringBoot 单元测试基本上就是使用@SpringBootTest注解标注进行,这种方式测试用例执行期间会启动 Spring IOC 容器加载所有依赖的 Bean 对象,并且自动注入所有对象,测试用例通过调用 Service 层的方法进行单元测试,这样做带来的弊端是测试用例执行时需要被依赖的所有服务均处于正常运行,现在微服务下很多 RPC 的调用,我们以为是调用一个方法,实际可能调用了成千上万的服务。并且需要保证 Service 依赖的数据库、Kafka、Redis 等都正常运行,否则测试用例很可能导致失败。而分层自动化测试则不同,分层自动化通过 Test Double(测试替身) 的方式对 Service 进行隔离,通过 Mock 技术可以单独针对某一个方法甚至是某一行代码行进行单独的测试,而不依赖于方法内部的调用链路。由于 Mapper 层我们已经单独对其进行了测试,所以测试 Service 层时完全可以自己构造测试数据,Mock 掉 Mapper 层的依赖,达到独立测试 Service。Service 层测试可以使用 Mockito、PowerMock、spring-test 等技术手段。比如:下面的代码使用 spring-test 结合 Mockito 进行一个简单的计算器测试示例代码。
@ExtendWith(MockitoExtension.class) public class UseMockitoInJunit5ByAnnotation { private CalculatorServiceImpl calculatorService; @Mock private CalculatorMapper mockCalculatorMapper; @Test public void testGetCalcResultUseMockito() { this.calculatorService = new CalculatorServiceImpl(); ReflectionTestUtils.setField(calculatorService, "calculatorMapper", mockCalculatorMapper); Mockito.when(mockCalculatorMapper.getCalcResultByDesc("desc")).thenReturn(4.0); calculatorService.getCalcResult("desc"); // 验证 Mock 的对象 CalculatorMapper 被调用的次数为1 Mockito.verify(mockCalculatorMapper, Mockito.times(1)).getCalcResultByDesc("desc"); } }
CalculatorServiceImpl 里需要注入 CalculatorMapper 所以这里需要借助 Spring-test 的反射测试工具来实现将 Mock 出来的 CalculatorMapper 注入到 CalculatorServiceImpl 类中。当然也可以不使用 spring-test 包的反射工具类注入对象而使用 Mockito 的@InjectMocks注解自动注入 CalculatorServiceImpl 的一个 Mock 对象。示例代码如下:
@ExtendWith(MockitoExtension.class)
public class MockitoInjectMocksTests {
// 将 @Mock 注解的对象注入到 @InjectMocks 对象中的属性
@InjectMocks
private CalculatorServiceImpl calculatorService;
@Mock
private CalculatorMapper mockCalculatorMapper;
@Test
public void testInjectMocks() {
calculatorService.getCalcResult(null);
}
}
InjectMocks 注解 会尝试通过构造方法自动注入需要的 Mock 对象,如果没有构造方法,则会使用 setXxx() 尝试进行注入。
集成测试
集成测试的 “集成 “是一个相对概念,一般我们将测试会分为几个级别,单元测试、集成测试、系统测试、验收测试等。集成测试更多指的是在单元被组合在一起之后的测试。比如:方法之间的集成、类之间的集成、模块之间的集成、微服务之间的集成、服务与中间件的集成、前后端的集成、系统之间的集成等。在上面的前端测试中组件测试和端到端测试可以理解为是一种集成测试。后端测试中对 Controller 使用 REST-Assured 也可以理解为是一种集成测试。在集成测试中更多关注的是模块之间组合在一起之后的正确性。如果直接使用 Postman、HttpClient、REST-Assured 就可以认为是后端的集成测试或者叫服务端测试。但是如果只是想测试 Controller 与 Service 之间的集成测试,那么则需要隔离 Mapper,这种方式通常在调式中完成,而非自动化的集成测试,或者使用 H2 Database 进行后端的集成测试。
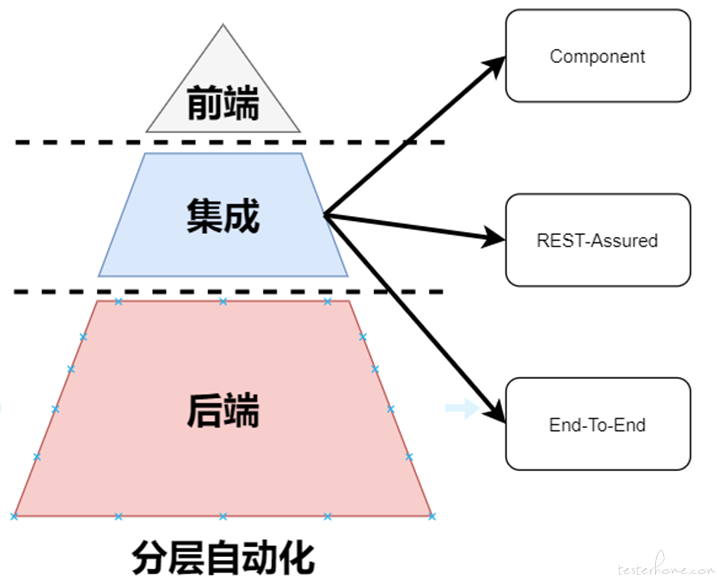
分层测试架构
通过使用分层自动化中的这些技术能有有效的进行 “真正” 分层自动化测试,但是对于传统的端到端测试、服务端测试也是有其价值的,具体还需要根据项目及团队进行取舍。传统的分层自动化与分层自动化也可以通过配置化的方式选择是否使用测试替身 Test Double 的切换,不过这个属于测试框架、测试平台层面需要去配合实现。关于分层自动化测试架构完整图可以参考如下:
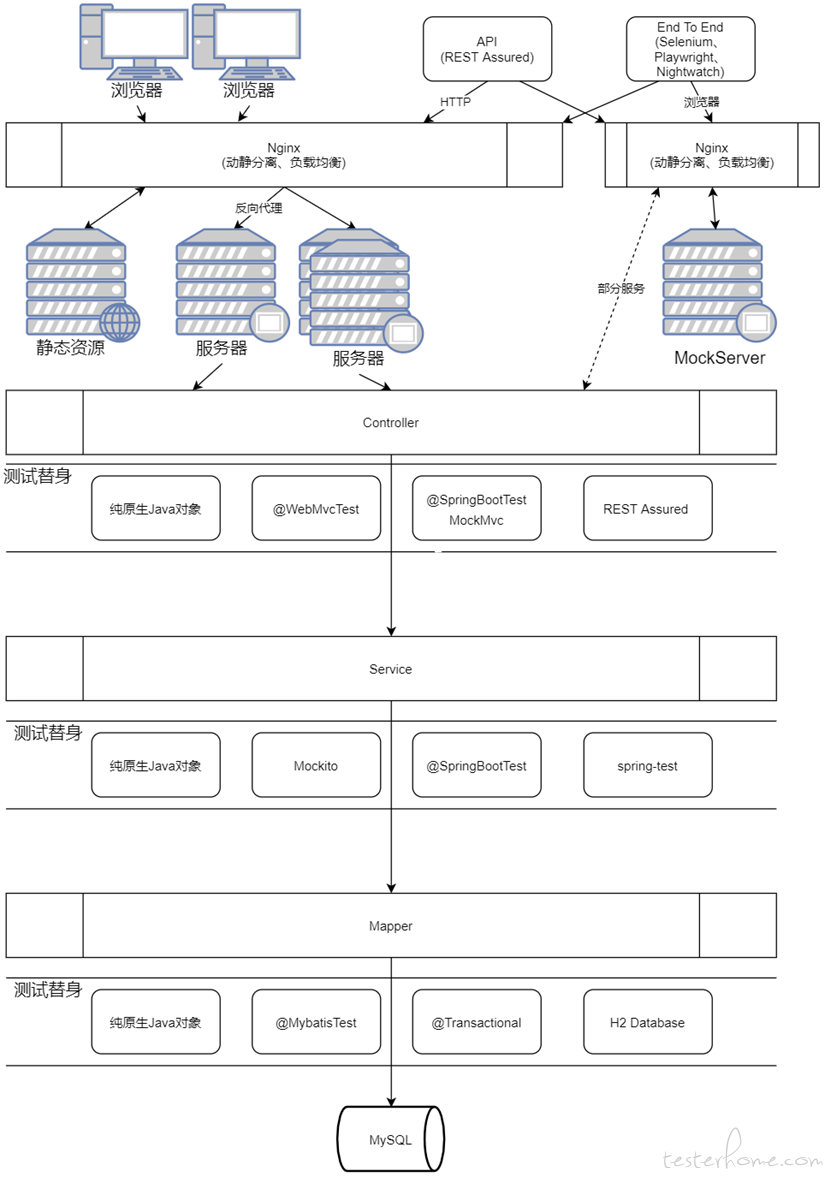
测试用例与 DevOps 平台
持续交付要求我们能有更快的速度交付产品到客户手中,使用 DevOps 构建高质量的软件还并不足以完成产品的交付,交付产品到客户手中还需要继续左移到需求端,使得流水线能与需求关联,这样平台能感应到需求与流水线之间的对应关系,进而可以在需求端选择要发布的流水线,同理测试用例应该也需要与流水线或者需求、用例等进行关联,使用哪种关联方式取决于实际企业的交付场景及 DevOps 平台的设计。
传统接口、UI 自动化测试用例一般是独立的工程,且与公司内部平台缺乏联动性,这样存在的不足是自动化测试用例与业务之间缺乏关联性,当业务发生变更时不太方便定位到此需求涉及到的测试用例,以及需求变更影响了哪些测试用例。在敏捷测试中,如果使用 Scrum 实践,需求一般会以用户故事编写,在用户故事下会有对应的开发任务、测试任务、测试用例、缺陷等关联。自动化测试用例可以通过注解的形式与需求或用例进行关联,不同的平台可能实现的方式不同,有些平台是通过需求与用例进行关联从而分析出需求及子需求影响的测试用例,基于这种模式下自动化测试用例只需要与测试用例关联即可,并且可以用过自动化测试执行完自动更新测试用例状态 (手工或自动化用例)。在理想敏捷开发过程中,测试应该是与研发并行的,这样当研发将需求下的开发任务修改为 “待测试” 时,触发自动化测试用例执行即可自动更新测试任务状态。也存在另外一种场景,测试用例与需求之间是脱离关系,比如测试人员通过编写思维导图创建测试用例(这里仅讨论在线思维导图),那么此时自动化测试用例则需要建立双向关系,绑定思维导图中的节点 ID 与需求 ID,则可以实现自动化测试用例执行完自动更新思维导图用例节点及需求状态 (这里一般不是直接更新需求状态字段,而是通过在需求下面写一条记录或者自动创建一条自动化测试用例,用例名称就是自动化测试用例的方法名 (@DisplayName)。测试用例关联需求或用例的伪代码代码如下:
@DisplayName("测试用例关联DevOps平台测试")
public class IssuesTests extends BasicTestCase {
/**
* {
@link ApiDoc @ApiDoc}当执行成功时自动更新任务ID中的状态
*/
@ApiDoc(value = {"project/7/task/10010","project/7/task/10011"})
@DisplayName("更新需求关联的任务10010和10011状态")
@Test
public void testAddIssue() {
// 这里完成具体业务的正确性验证代码。
doSomething...
// 通过JUnit的TestWatcher监听测试结果,如果断言通过则自动更新任务的状态为“完成”,失败则更新任务状态为“失败”
assertThat(true, is(true));
}
}
上面的伪代码中 “@ApiDoc” 是自定义注解,其作用为自动更新需求管理平台中指定任务或用户故事 ID 的数据。
测试覆盖率
测试覆盖率通常包含两个最基本的维度 “需求覆盖和代码覆盖率”。需求覆盖率通常是指需求被分解之后是否有对应的任务 (开发、测试、用例、缺陷等) 与之进行关联,最终达到所有需求都被验证过,证明软件是经过测试的。需求与用例之间的关联关系可以参考下图:
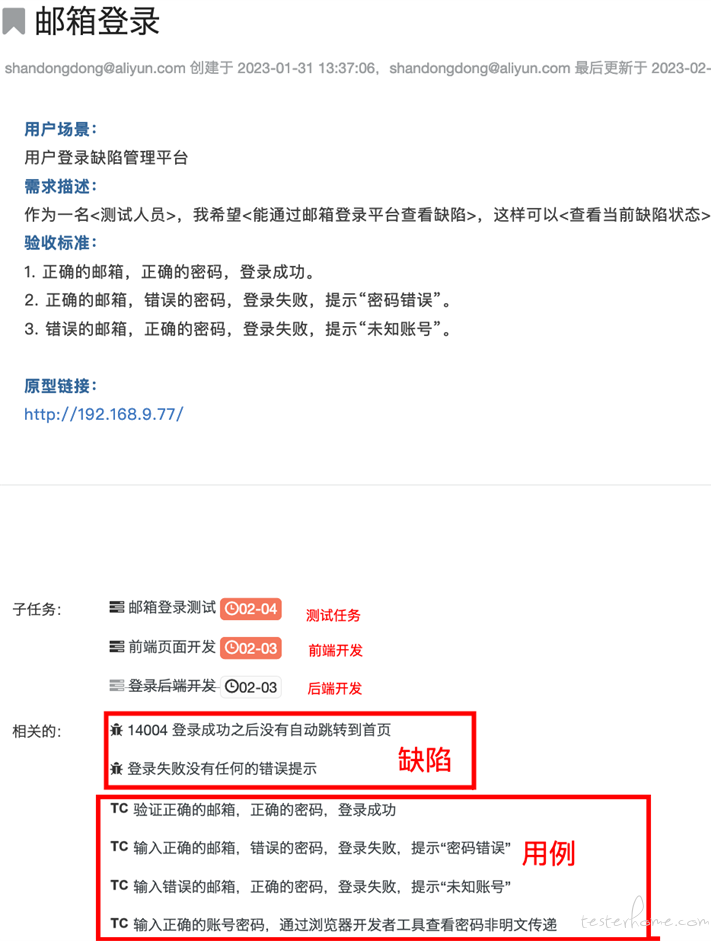
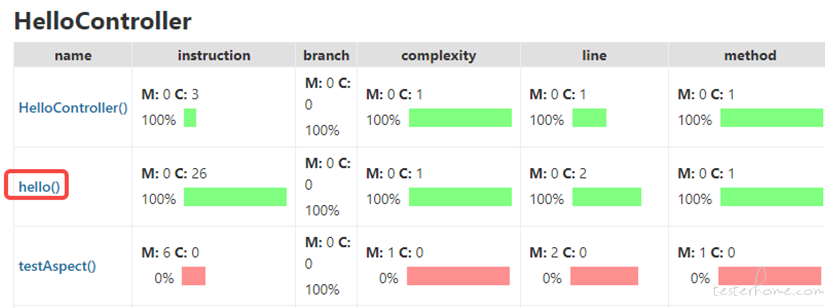
代码覆盖率是一种通过计算测试执行过程中被执行的代码占全部源代码的比例,从而间接性衡量软件质量的方法,需要注意代码覆盖率通常是为了发现测试设计的不足,进而补充测试用例,而不是被用来设计衡量代码质量的唯一标准。Java 语言可以使用 JaCoCo 工具收集代码覆盖率,结合 gitdiff,jgit 等工具能获取增量覆盖率。通过结合 DevOps 平台、测试用例、代码覆盖率等技术之后,能有效构建需求、手工用例、自动化用例之间关联关系及影响范围。
总结
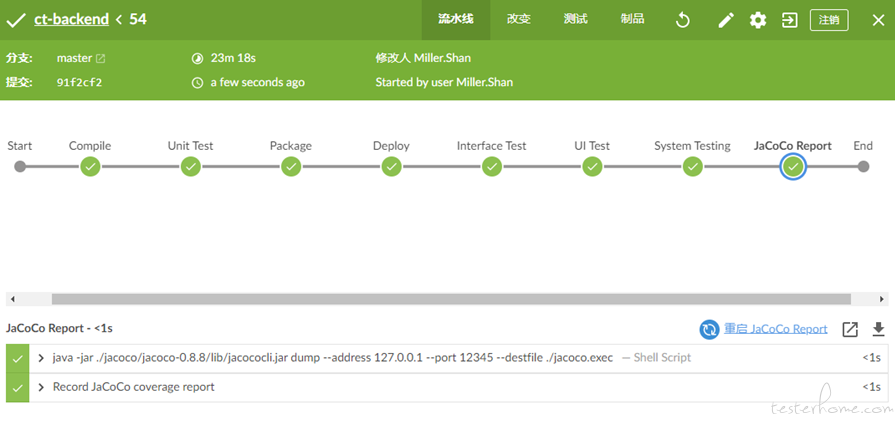
通过类似于 “DevOps 平台”,我们可以将需求、任务、缺陷、用例、代码 (开发 + 测试)、流水线等进行有机整合实现从业务需求的产生到发布上线一体化,真正做到持续交付高质量软件。这些数据不再是信息孤岛,通过互相关联使得整个项目管理过程更加数字化。关于如何产品化这块大家可以参考 “云效、TAPD、禅道” 等产品。也可以先做技术端的持续交付,直接用开源的 Jenkins 完成技术端的敏捷,然后在左移到业务端。下图为 Jenkins 的持续集成流水线示例图。
限于篇幅整个分层自动化测试体系,这里没有展开详细讲解,后续有规划推出系列文章。欢迎志同道合的朋友添加我的微信 (Miller_Shan)一起交流,互相学习,共同进步。

