背景
在现代企业中,信息管理对企业的发展至关重要。企业内部的信息包括了业务规范、操作流程、行业信息等方面,但这些信息通常分散在各个部门和人员之中,难以有效地被整合和利用。为了解决这个问题,我们希望通过使用人工智能技术,构建一个内部信息问答 AI 接口,使得员工可以快速地获取所需的信息,提高工作效率。
实现功能
本文中,我们将介绍如何通过 OpenAI 的 embedding 功能,结合公司业务规范,实现一个内部信息问答 AI 接口。该接口具备以下功能:
- 可以针对公司内部的业务规范、操作流程等信息进行问答;
- 员工可以在内部的系统界面中方便地使用,提高工作效率。
技术架构
我们使用了 OpenAI 的 embedding 技术来实现这个内部信息问答 AI 接口。具体来说,我们首先需要将公司内部的需要共识的业务规范、操作流程等信息进行向量化处理。这个过程需要使用一个预训练好的语言模型,例如 GPT 的 ada 模型。然后,我们将员工提供的问题也进行向量化处理,然后使用一个相似度计算方法,比如余弦相似度,来计算员工提供的问题和每个信息的相似度,从而找到可能内容信息,再由更强大的 GTP-3.5 模型分析给出最佳答案。
整个技术架构如下图所示:
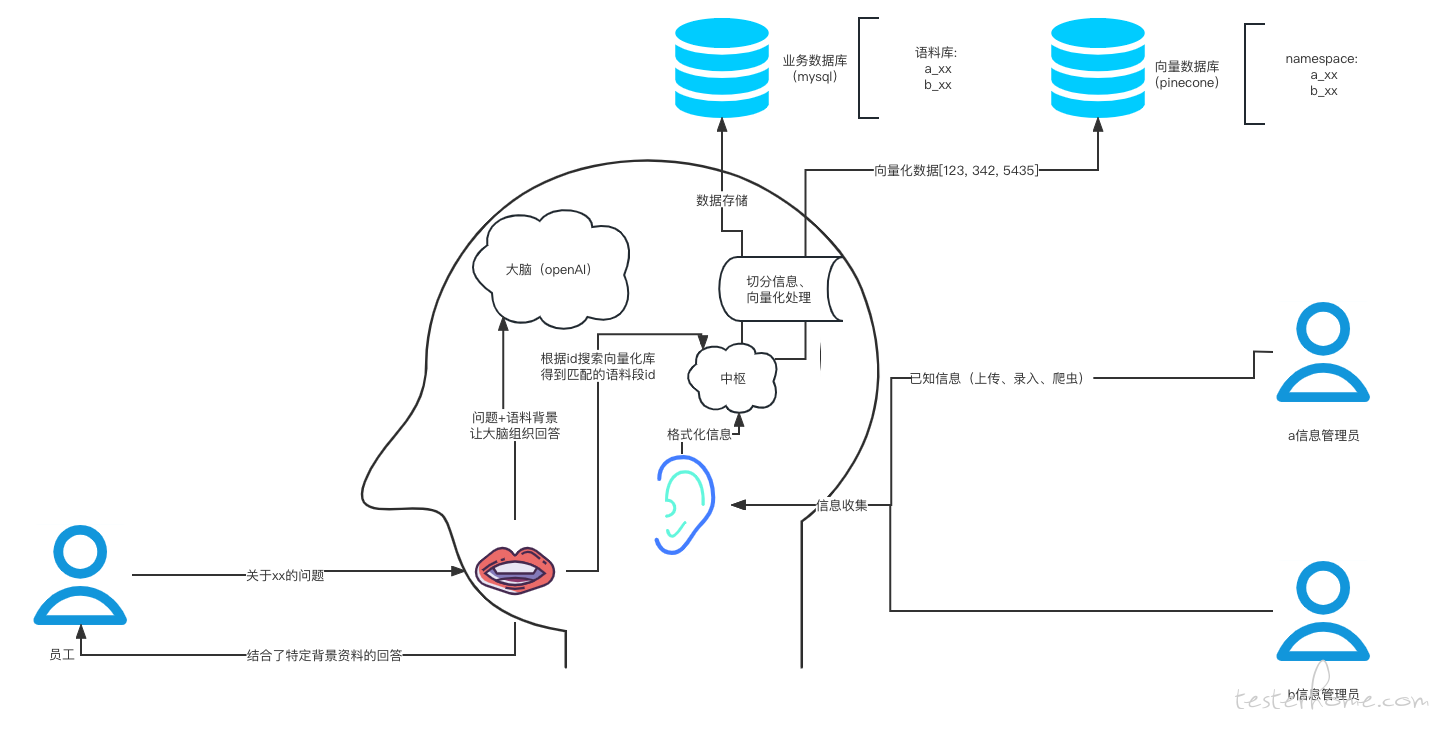
设计细节
向量化处理
首先,我们需要将公司内部的所有业务规范、操作流程等信息进行向量化。我们可以使用一个预训练好的语言模型,例如 text-embedding-ada-002,来实现这个向量化过程。具体来说,我们可以将每一条业务规范、操作流程等信息先根据语意进行分段拆分,在将每一段作为一个输入,然后使用 text-embedding-ada-002模型来生成一个对应的编码向量。
这个过程可以使用 OpenAI 的 API 来实现。我们需要调用 API 的 embeddings 方法,传入业务规范或操作流程等信息,以及一些其他参数,例如 model(选择预训练的语言模型)、input(输入的文本信息)。调用 embeddings 方法后,API 将返回一个编码向量,我们可以将这个编码向量保存在数据库中,以便后续的相似度计算。
以下是调用 embeddings 方法的示例代码:
import openai
openai.api_key = "YOUR_API_KEY"
def embedding_text(text, model):
response = openai.Embedding.create(
input=text,
model=model
)
embeddings = response['data'][0]['embedding']
return embeddings
# 使用 ada 编码一条业务规范
business_rule = "在订单完成前,顾客可以随时取消订单。"
model = "text-embedding-ada-002"
encoding = embedding_text(business_rule, model)
print(encoding)
相似度计算
一旦我们获得了业务规范、操作流程等信息的编码向量,我们就可以使用一个相似度计算方法,例如余弦相似度,来计算员工提供的问题和每个信息的相似度。具体来说,我们可以将员工提供的问题也进行编码,然后将问题的编码向量和每个信息的编码向量计算余弦相似度,得到一个相似度得分。得分最高的信息就是最佳答案。
以下是以我们已经在 pinecone 中定义了算法模型为余弦相似度的 index,调用的示例代码:
import pinecone
# initialize connection to pinecone (get API key at app.pinecone.io)
pinecone.init(
api_key="YOUR_API_KEY",
environment="YOUR_ENV" # find next to API key in console
)
# check if 'openai' index already exists (only create index if not)
if 'openai' not in pinecone.list_indexes():
pinecone.create_index('openai', dimension=len(embeds[0]))
# connect to index
index = pinecone.Index('openai')
res = index.query([xq], top_k=5, include_metadata=True)
for match in res['matches']:
print(f"{match['score']:.2f}: {match['metadata']['text']}")
多类型数据管理
对于信息的分类,不同场景下的规范要求,是多样的。因此我们还需要在获取业务信息时加以区分。对于系统来说,我们可以通过提问数据的来源或场景查询不同的业务领域信息。
如下是个简易的嵌入信息管理后台,用来管理启用和新增我们的自定义数据:

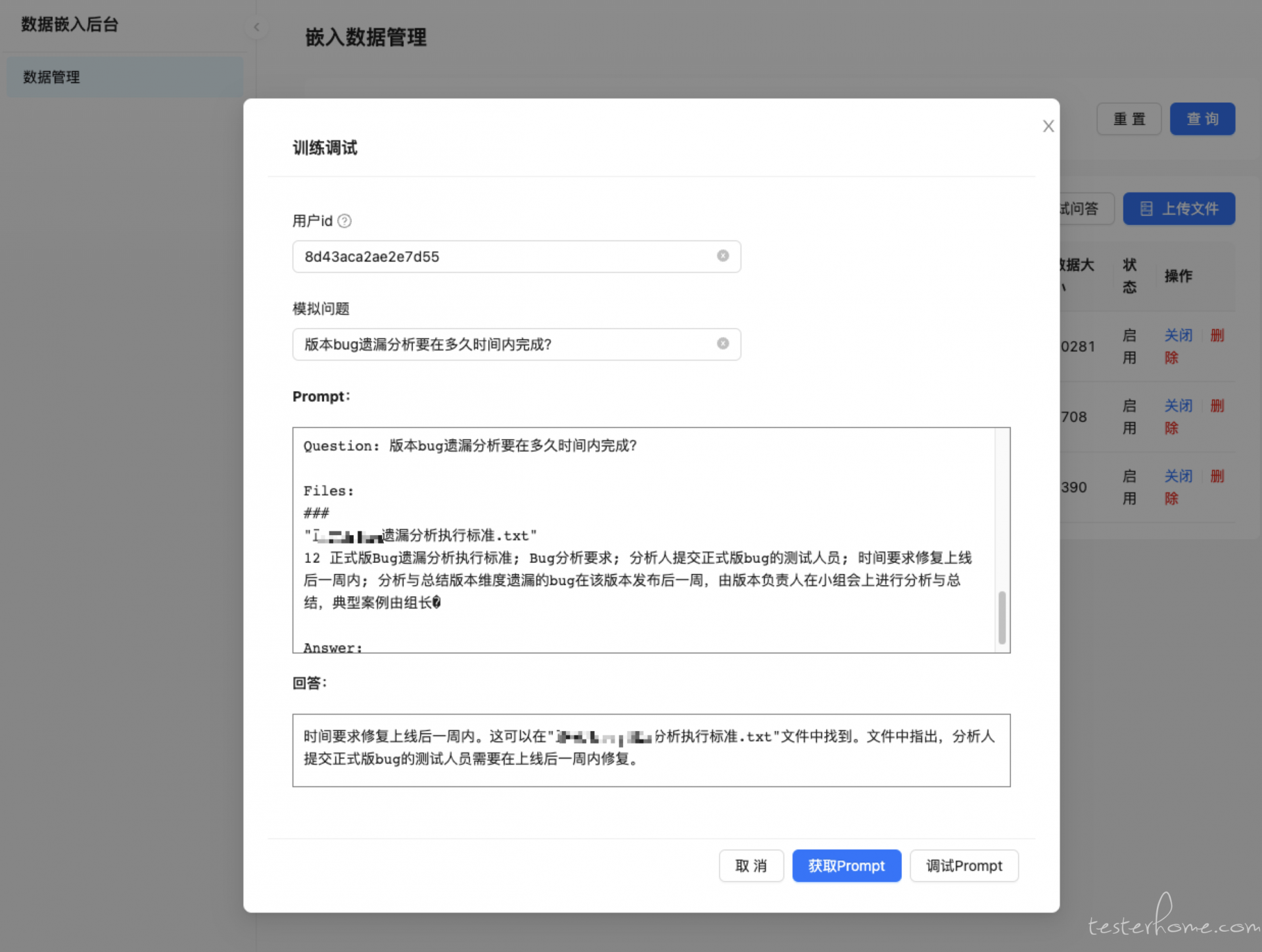
可以看到我们以不同的用户 id、数据状态作为了数据匹配的范围控制。
在实现了内部信息问答 AI 接口后,我们可以考虑进一步扩展其功能。例如,我们可以使用自然语言生成技术来自动生成业务规范、操作流程等信息,集成到已有的软件系统中,以减轻员工的工作负担。
我们还可以将接口整合到公司已有的可对话系统中,以便员工可以直接在聊天窗口中提问,并且可以获得更加个性化的回答。
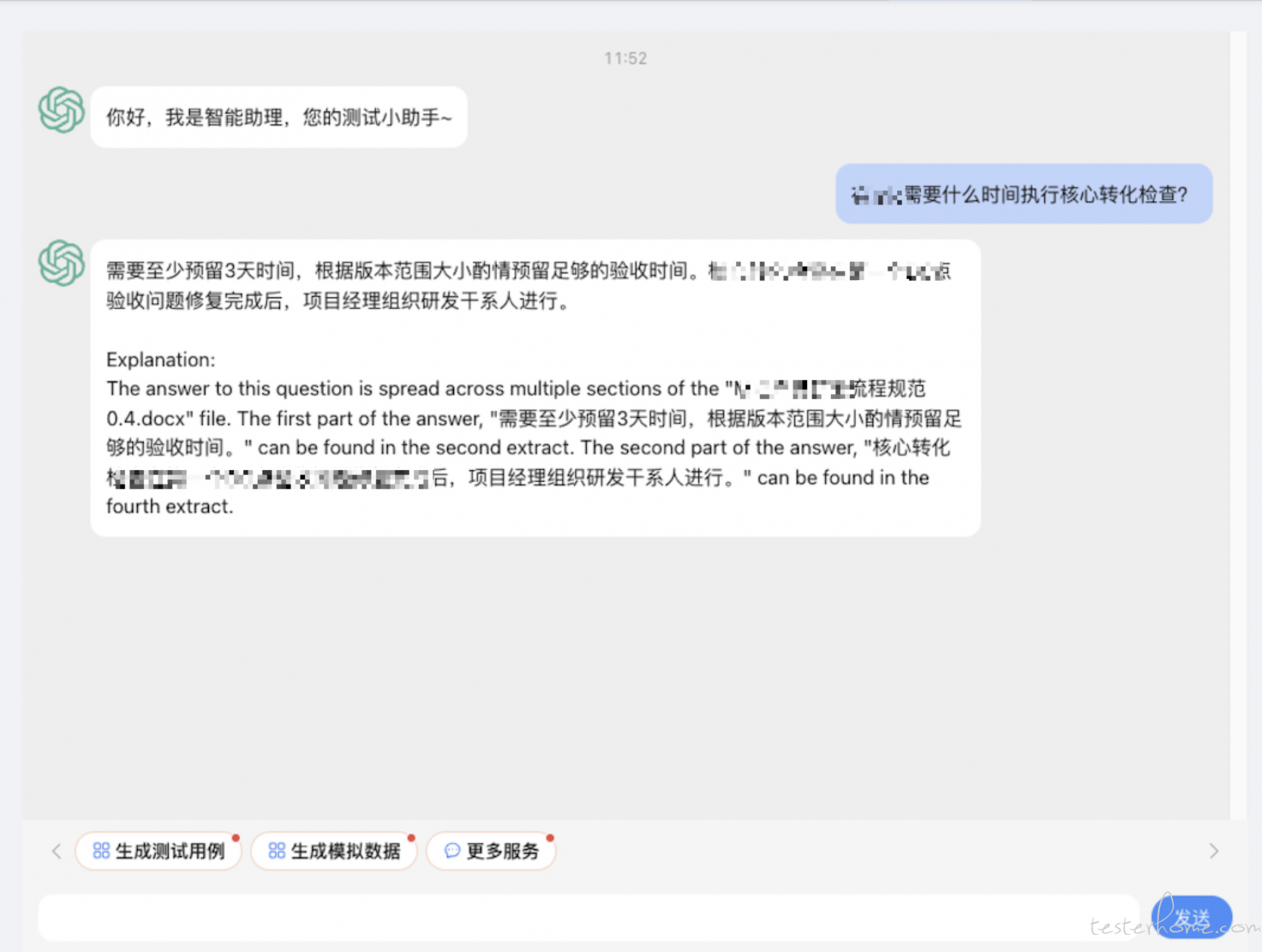
后续规划
我们还可以考虑将接口扩展到公司的客户服务中,以帮助客户更快地解决问题,提高客户满意度。
在技术方面,我们可以探索更先进的自然语言处理技术,例如预训练的语言模型 GPT-3,以提高接口的准确性和覆盖面。我们还可以探索更高效的相似度计算方法,以便能够更快地响应员工的问题。此外,我们还可以使用监督学习技术,例如分类器和回归器,以便更好地处理一些特定的问题类型,例如价格计算、库存查询等等。
总之,通过使用 OpenAI 的 embedding 功能,我们实现了一个内部信息问答 AI 接口,帮助员工更快地解决问题,提高工作效率。随着技术的不断发展,这种接口的功能将越来越强大,为企业带来更多的价值。