上篇提到过,这一篇是关于 linux 相关的性能测试结果展示的部署。
locust
这部分没有改变,依旧是执行之前压力测试机上的代码即可
influxdb
去官网下载你想要的 rpm 包,然后通过 rpm -ivh 命令去安装。这里需要注意,如果安装一直提示失败,可能是你下载的 rpm 包不完整,把之前下载好的包删除,并且重新下载即可。
安装完毕之后,需要做一些简单的配置。
- create user username with password '12345' with all privileges; 用来创建一个 admin 用户
- 修改 /etc/influxdb/influxdb.conf 配置文件
[http]
enabled = true
auth-enabled = true
[coordinator]
query-timeout = “60s”
以上完成,即可使用。
grafana
grafana 这里没什么好讲的,只要确认 3000 端口没有被占用即可,如果被占用了就换一个,同时开放这个端口的访问权限
linux
关于 linux 的性能监控,这里使用了 vmstat 的命令,具体代码如下:
import subprocess
import re
from influxdb import InfluxDBClient
import time
client = InfluxDBClient('127.0.0.1', 8086, 'name', 'password', 'database')
client.switch_database('database')
while True:
cpu_usage = 'vmstat 2 1'
p = subprocess.Popen(cpu_usage, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
for line in iter(p.stdout.readline, b''):
line = line.rstrip().decode('utf8')
my_re = re.compile(r'[A-Za-z]', re.S)
res = re.findall(my_re,line)
if len(res):
continue
else:
data_list = []
fields = {}
for item in line.split(' '):
if item != '':
data_list.append(item)
fields['swpd_mem'] = int(data_list[2])
fields['free_mem'] = int(data_list[3])
fields['buff_mem'] = int(data_list[4])
fields['cach_mem'] = int(data_list[5])
fields['si'] = int(data_list[6]) # check SI/SO
fields['so'] = int(data_list[7]) # check SI/SO
fields['IO_r'] = int(data_list[8]) # check Server_IO
fields['IO_w'] = int(data_list[9]) # check Server_IO
fields['wait'] = int(data_list[15]) # check cpu
fields['user_time'] = int(data_list[12]) # check cpu
fields['system_time'] = int(data_list[13]) # check cpu
content = [
{
"measurement": "measurement name",
"fields": fields
}
]
client.write_points(content)
time.sleep(10)
只需要启动这个代码,同时去 grafana 配置一个数据源即可显示自己想要的信息。关于 vmstat 的各个参数的意义,我自己的理解放在下面,如若不对请指正。
# vmstat 2 1 表示每隔两秒刷新一次数据 1 表示只显示一次
# swpd 虚拟内存已使用的大小,如果虚拟内存使用较多,可能系统的物理内存比较吃紧
# 数据 free 代表空闲的物理内存/1024为MB, buff cache都可以计算为空闲
# si, 从磁盘交换到内存的交换页数量,单位:KB/秒. so,从内存交换到磁盘的交换页数量,单位:KB/秒
# 内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。当看到空闲内存(free)很少的或接近于0时,
# 就认为内存不够用了,这个是不正确的。不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
# bi 磁盘读, bo磁盘写
# wa wait越大则机器io性能就越差。说明IO等待比较严重
# us 用户CPU时间(非内核进程占用时间)(单位为百分比)。 us的值比较高时,说明用户进程消耗的CPU时间多
# sy 系统使用的CPU时间(单位为百分比)。sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因
我这里碰到个问题,也还没有解决。因为这个监控 linux 性能的脚本是执行在 server 本身的,所以当压力测试开始执行的时候,并发数上来之后关于 server 的监控信息刷新很慢,大概率是因为多个请求到达服务器导致的请求过多。这里有些不确定是因为脚本跑在服务器的关系还是因为 grafana 的关系导致的信息没有办法实时同步。不过当并发下降或者测试结束之后是可以看到数据的正常波动的。
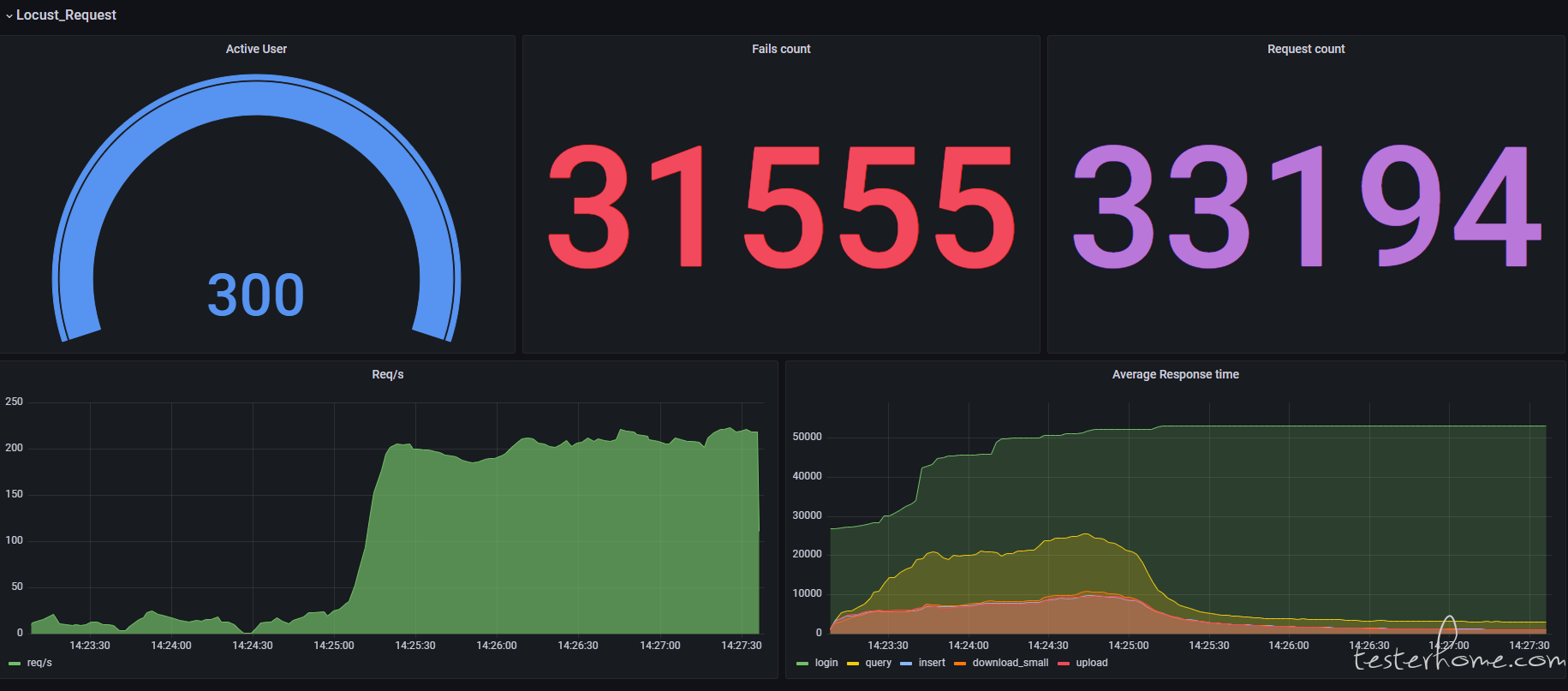
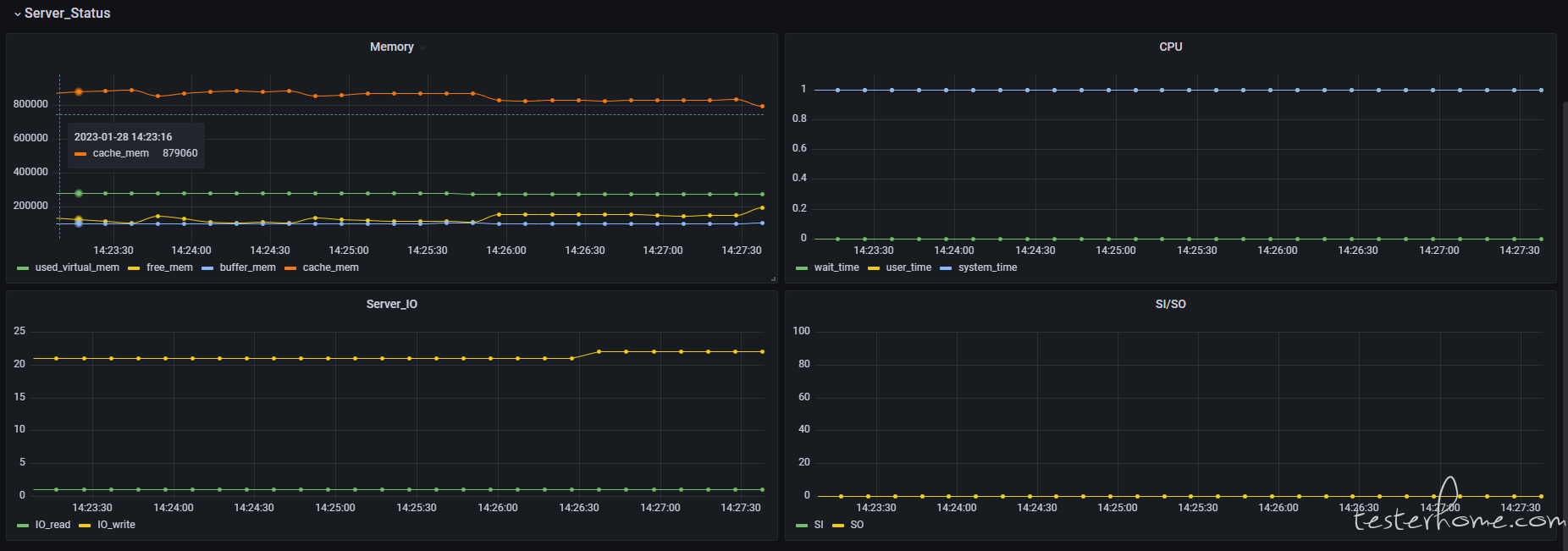
上个配置好的图
「原创声明:保留所有权利,禁止转载」
暂无回复。