作者:李玉亮
引言
数据库事务与大多数后端软件开发人员的工作密不可分,本文从事务理论、事务技术、事务实践等方面对常用的相关事务知识进行整理总结,供大家参考。
事务理论介绍
事务定义
在数据库管理系统中,事务是单个逻辑或工作单元,有时由多个操作组成,在数据库中以一致模式完成的逻辑处理称为事务。一个例子是从一个银行账户转账到另一个账户:完整的交易需要减去从一个账户转账的金额,然后将相同的金额添加到另一个账户。
事务特性
原子性 ( atomicty)
事务中的全部操作在数据库中是不可分割的,要么全部完成,要么全部不执行。
一致性 (consistency)
事务的执行不能破坏数据库数据的完整性和一致性。一致性指数据满足所有数据库的条件,比如字段约束、外键约束、触发器等,事务从一致性开始,以一致性结束。
隔离性 ( isolation)
事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务是透明的。
持久性 (durability)
对于提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
注:DBMS 一般采用日志来保证事务的原子性、一致性和持久性。
事务隔离级别
并发事务带来的问题

不可重复读的重点是数据修改场景,幻读的重点在于新增或者删除场景。
事务隔离级别
SQL92 标准定义了 4 种隔离级别的事务
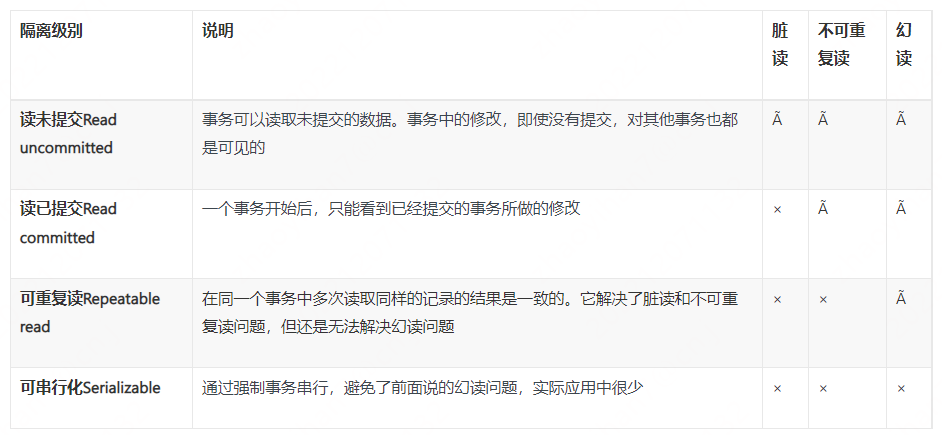
大多数数据库系统如 oracle 的默认隔离级别都是 Read committed,mysql 默认为可重复读,InnoDB 和 XtraDB 存储引擎通过多版并发控制(MVCC,Multivesion Concurrency Control)解决了幻读问题,Repeatable read 是 Mysql 默认的事务隔离级别,其中 InnoDB 主 要通过使用 MVVC 获得高并发,使用一种被称为 next-key-locking 的策略来避免幻读。
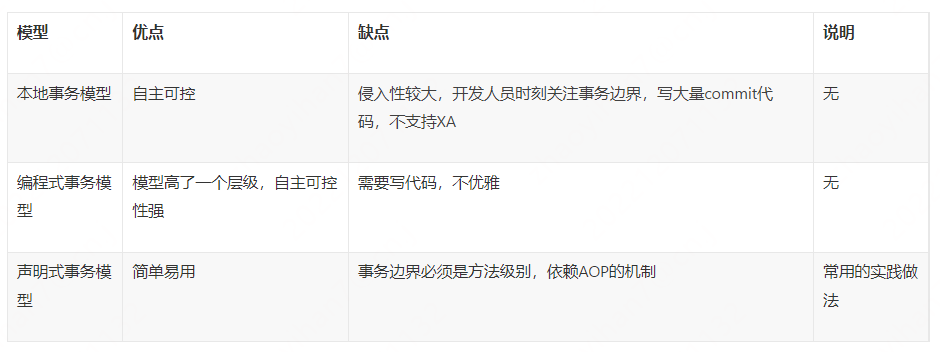
事务模型
事务提交模型
显式事务:又称自定义事务,是指用显式的方式定义其开始和结束的事务,当使用 start transaction 和 commit 语句时表示发生显式事务。
隐式事务:隐式事务是指每一条数据操作语句都自动地成为一个事务,事务的开始是隐式的,事务的结束有明确的标记。即当用户进行数据操作时,系统自动开启一个事务,事务的结束则需手动调用 commit 或 rollback 语句来结束当前事务,在当前事务结束后又自动开启一个新事务。
自动事务:自动事务是指能够自动开启事务并且能够自动结束事务。在事务执行过程中,如果没有出现异常,事务则自动提交;当执行过程产生错误时,则事务自动回滚;一条 SQL 语句一个事务。
事务编程模型
本地事务模型:事务由本地资源管理器来管理。简单理解就是直接使用 JDBC 的事务 API。
connection.setAutoCommit(false);// 自动提交关闭
//XXXX数据库的增删改查操作
connection.commit(); //提交事务
编程式事务模型:事务通过 JTA 以及底层的 JTS 实现来管理,对于开发人员而言,管理的是 “事务”,而非 “连接”。简单理解就是使用事务的 API 写代码控制事务。
示例一、JTA 的 API 编程
UserTransaction txn = sessionCtx.getUserTransaction();
txn.begin();
txn.commit();
示例二、Spring 的事务模版
transactionTemplate.execute(
new TransactionCallback<Object>() {
@Override
public Object doInTransaction(TransactionStatus status) {
// 事务相关处理
return null;
}
}
);
声明式事务:事务由容器进行管理,对于开发人员而言,几乎不管理事务。简单理解就是加个事务注解或做个 AOP 切面。
@Transactional(rollbackFor = Exception.class)
public void updateStatus(String applyNo){
cashierApplyMapper.updateStatus(applyNo, CANCEL_STATUS, CANCEL_STATUS_DESC);
}
比较
附:SQL 相关小知识
**SQL 的全称:**Structured Query Language。中文翻译:结构化查询语言。
关系数据库理论之父:埃德加·科德。是一位计算机的大牛,他凭借关系数据模型理论获得了图灵奖,核心思想就两个:关系代数和关系演算,发表了一篇牛逼的论文 “A Relational Model of Data for Large Shared Data Banks”。
写第一句 SQL 的人:Donald D. Chamberlin 和 Raymond F. Boyce。埃德加·科德的两个同事 Donald D. Chamberlin 和 Raymond F. Boyce 根据论文,发明出了简单好用的 SQL 语言。
**SQL 标准:** 有两个主要的标准,分别是 SQL92 和 SQL99 。92 和 99 代表了标准提出的时间。除了 SQL92 和 SQL99 以外,还存在 SQL-86、SQL-89、SQL:2003、SQL:2008、SQL:2011 和 SQL:2016 等其他的标准。
事务技术介绍
以 Spring+Mybatis+JDBC+Mysql 为例,常见的事务类请求的调用链路如下图。请求调用应用服务,应用服务中开启事务并进行业务操作,操作过程中调用 Mybatis 进行数据库类操作,Mybatis 通过 JDBC 驱动与底层数据库交互。
因此接下来先按 Mysql、JDBC、Mybatis、Spring 来介绍各层的事务相关知识;最后进行全链路的调用分析。
Mysql 事务相关
Mysql 逻辑架构
架构图如下 (InnoDB 存储引擎):
MySQL 事务是由存储引擎实现的,MySQL 支持事务的存储引擎有 InnoDB、NDB Cluster 等,其中 InnoDB 的使用最为广泛,其他存储引擎如 MyIsam、Memory 等不支持事务。
Mysql 的事务保证
Mysql 的 4 个特性中有 3 个与 WAL(Write-Ahead Logging,先写日志,再写磁盘)有关系,需要通过 Redo、Undo 日志来保证等,而一致性需要通过 DBMS 的功能逻辑及原子性、隔离性、持久性共同来保证。
MVCC
MVCC 最大的好处是读不加锁,读写不冲突,在读多写少的系统应用中,读写不冲突是非常重要的,可极大提升系统的并发性能,这也是为什么现阶段几乎所有的关系型数据库都支持 MVCC 的原因,目前 MVCC 只在 Read Commited 和 Repeatable Read 两种隔离级别下工作。它是通过在每行记录的后面保存两个隐藏列来实现的,这两个列, 一个保存了行的创建时间,一个保存了行的过期时间, 存储的并不是实际的时间值,而是系统版本号。MVCC 在 mysql 中的实现依赖的是 undo log 与 read view。
read view
在 MVCC 并发控制中,读操作可以分为两类: 快照读(Snapshot Read)与当前读(Current Read)。
•快照读:读取的是记录的快照版本(有可能是历史版本)不用加锁(select)。
•当前读:读取的是记录的最新版本,并且当前读返回的记录,都会加锁,保证其他事务不会再并发修改这条记录 (select… for update 、lock 或 insert/delete/update)。
redo log
redo log 叫做重做日志。mysql 为了提升性能不会把每次的修改都实时同步到磁盘,而是会先存到 Buffer Pool(缓冲池) 里,当作缓存来用以提升性能,使用后台线程去做缓冲池和磁盘之间的同步。那么问题来了,如果还没来及的同步的时候宕机或断电了怎么办?这样会导致丢部分已提交事务的修改信息!所以引入了 redo log 来记录已成功提交事务的修改信息,并且会把 redo log 持久化到磁盘,系统重启之后再读取 redo log 恢复最新数据。redo log 是用来恢复数据的,保障已提交事务的持久化特性。
undo log
undo log 叫做回滚日志,用于记录数据被修改前的信息。他正好跟前面所说的重做日志所记录的相反,重做日志记录数据被修改后的信息。undo log 主要记录的是数据的逻辑变化。为了在发生错误时回滚之前的操作,需要将之前的操作都记录下来,然后在发生错误时才可以回滚。undo log 记录事务修改之前版本的数据信息,假如由于系统错误或者 rollback 操作而回滚的话可以根据 undo log 的信息来进行回滚到没被修改前的状态。undo log 是用来回滚数据的,保障未提交事务的原子性。
示例
假设 F1~F6 是表中字段的名字,1~6 是其对应的数据。后面三个隐含字段分别对应该行的隐含 ID、事务号和回滚指针,如下图所示。
具体的更新过程如下:
假如一条数据是刚 INSERT 的,DB_ROW_ID 为 1,其他两个字段为空。当事务 1 更改该行的数据值时,会进行如下操作,如下图所示。
•用排他锁锁定该行,记录 Redo log;
•把该行修改前的值复制到 Undo log,即图中下面的行;
•修改当前行的值,填写事务编号,并回滚指针指向 Undo log 中修改前的行。
如果再有事务 2 操作,过程与事务 1 相同,此时 Undo log 中会有两行记录,并且通过回滚指针连在一起,通过当前记录的回滚指针回溯到该行创建时的初始内容,如下图所示,这里的 undolog 不会一直增加,purge thread 在后面会进行 undo page 的回收,也就是清理 undo log。
JDK 事务相关
JDBC 规范
java 定义了统一的 JDBC 驱动 API,各数据库厂商按规范实现。jdbc 驱动相关包在 java.sql 包下:
使用示例:
// 创建数据库连接
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/easyflow", "root", "12345678");
// 自动提交设置
connection.setAutoCommit(false);
// 只读设置
connection.setReadOnly(false);
// 事务隔离级别设置
connection.setTransactionIsolation(Connection.TRANSACTION_REPEATABLE_READ);
// 创建查询语句
PreparedStatement statement = connection.prepareStatement("update config set cfg_value='1' where id=11111");
// 执行SQL
int num = statement.executeUpdate();
System.out.println("更新行数:" + num);
// 事务提交
connection.commit();
JDBC 驱动注册机制
之前需要调用 Class.forName 或其他方式显式加载驱动,现在有了 SPI 机制后可不写。
public class DriverManager {
// List of registered JDBC drivers
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();
private static volatile int loginTimeout = 0;
private static volatile java.io.PrintWriter logWriter = null;
private static volatile java.io.PrintStream logStream = null;
// Used in println() to synchronize logWriter
private final static Object logSync = new Object();
/* Prevent the DriverManager class from being instantiated. */
private DriverManager(){}
/**
* Load the initial JDBC drivers by checking the System property
* jdbc.properties and then use the {@code ServiceLoader} mechanism
*/
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
……
JTA 规范
JTA 全称 Java Transaction API,是 X/OPEN CAE 规范中分布式事务 XA 规范在 Java 中的映射,是 Java 中使用事务的标准 API,同时支持单机事务与分布式事务。
作为 J2EE 平台规范的一部分,JTA 与 JDBC 类似,自身只提供了一组 Java 接口,需要由供应商来实现这些接口,与 JDBC 不同的是这些接口需要由不同的供应商来实现。
相关代码在 jta jar 的 javax.transaction 包下。
Mybatis 事务相关
Mybatis 核心是提供了 sql 查询方法、结果集与应用方法及对象之间的映射关系,便于开发人员进行数据库操作。
整体模块如下:
各模块与下面的各子包一一对应:
Mybatis 执行的核心类如下:
Mysql 的核心入口类为 SqlSession,事务相关的操作通过 TransactionFactory 来处理,可选择使用 Spring 事务 (SpringManagedTransaction) 还是内置事务管理。
事务相关的控制处理可见 SqlSessionInterceptor 类,主要逻辑如下:
源码见下:
private class SqlSessionInterceptor implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
SqlSession sqlSession = getSqlSession(SqlSessionTemplate.this.sqlSessionFactory,
SqlSessionTemplate.this.executorType, SqlSessionTemplate.this.exceptionTranslator);
try {
Object result = method.invoke(sqlSession, args);
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// force commit even on non-dirty sessions because some databases require
// a commit/rollback before calling close()
sqlSession.commit(true);
}
return result;
} catch (Throwable t) {
Throwable unwrapped = unwrapThrowable(t);
if (SqlSessionTemplate.this.exceptionTranslator != null && unwrapped instanceof PersistenceException) {
// release the connection to avoid a deadlock if the translator is no loaded. See issue #22
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
sqlSession = null;
Throwable translated = SqlSessionTemplate.this.exceptionTranslator
.translateExceptionIfPossible((PersistenceException) unwrapped);
if (translated != null) {
unwrapped = translated;
}
}
throw unwrapped;
} finally {
if (sqlSession != null) {
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
}
}
}
}
Spring 事务相关
spring 事务相代码主要位于 spring-tx 包,如 TransactionInterceptor。spring-jdbc 包中有 spring jdbc 对事务的相关支持实现,如 JdbcTransactionManager。核心类如下图,主要有三大部分:事务管理器(TransactionManager)、事务定义(TransactionDefinition)、事务状态(TtransactionStatus),这也是经常见的一种架构思维,将功能模块抽象为配置态定义、运行态实例和执行引擎,在开源组件 jd-easyflow(
https://github.com/JDEasyFlow/jd-easyflow) 中也是此种设计理念。从下面的类图可以 Spring 的设计非常有层次化,很有美感。
Spring 编程式事务
常用类为 TransacitonTemplate,执行逻辑为:获取事务状态->在事务中执行业务->提交或回滚,源码见下:
@Override
@Nullable
public <T> T execute(TransactionCallback<T> action) throws TransactionException {
Assert.state(this.transactionManager != null, "No PlatformTransactionManager set");
if (this.transactionManager instanceof CallbackPreferringPlatformTransactionManager) {
return ((CallbackPreferringPlatformTransactionManager) this.transactionManager).execute(this, action);
}
else {
TransactionStatus status = this.transactionManager.getTransaction(this);
T result;
try {
result = action.doInTransaction(status);
}
catch (RuntimeException | Error ex) {
// Transactional code threw application exception -> rollback
rollbackOnException(status, ex);
throw ex;
}
catch (Throwable ex) {
// Transactional code threw unexpected exception -> rollback
rollbackOnException(status, ex);
throw new UndeclaredThrowableException(ex, "TransactionCallback threw undeclared checked exception");
}
this.transactionManager.commit(status);
return result;
}
}
Spring 声明式事务
声明式事务实现原理就是通过 AOP/动态代理。
在 Bean 初始化阶段创建代理对象:Spring 容器在初始化每个单例 bean 的时候,会遍历容器中的所有 BeanPostProcessor 实现类,并执行其
postProcessAfterInitialization 方法,在执行 AbstractAutoProxyCreator 类的 postProcessAfterInitialization 方法时会遍历容器中所有的切面,查找与当前实例化 bean 匹配的切面,这里会获取事务属性切面,查找@Transactional注解及其属性值,然后根据得到的切面创建一个代理对象,默认是使用 JDK 动态代理创建代理,如果目标类是接口,则使用 JDK 动态代理,否则使用 Cglib。
在执行目标方法时进行事务增强操作:当通过代理对象调用 Bean 方法的时候,会触发对应的 AOP 增强拦截器,声明式事务是一种环绕增强,对应接口为 MethodInterceptor,事务增强对该接口的实现为 TransactionInterceptor,类图如下:
事务拦截器 TransactionInterceptor 在 invoke 方法中,通过调用父类 TransactionAspectSupport 的 invokeWithinTransaction 方法进行事务处理,包括开启事务、事务提交、异常回滚 。
声明式事务有 5 个配置项,说明如下:
事务配置一、事务隔离级别
配置该事务的隔离级别,一般情况数据库或应用统一设置,不需要单独设值。
事务配置二、事务传播属性
事务传播属性是 spring 事务模块的一个重要属性。简单理解,他控制一个方法在进入事务时,在外层方法有无事务的场景下,自己的事务的处理策略,如是复用已有事务还是创建新事务。
spring 支持的传播属性有 7 种,如下:

事务配置三、事务超时
事务的超时设置是为了解决什么问题呢?
在数据库中,如果一个事务长时间执行,这样的事务会占用不必要的数据库资源,还可能会锁定数据库的部分资源,这样在生产环境是非常危险的。这时就可以声明一个事务在特定秒数后自动回滚,不必等它自己结束。
事务超时时间的设置
由于超时时间在一个事务开启的时候创建的,因此,只有对于那些具有启动一个新事务的传播行为(PROPAGATION_REQUIRES_NEW、PROPAGATION_REQUIRED、ROPAGATION_NESTED),声明事务超时才有意义。
事务配置四、事务只读
如果一个事务只对数据库进行读操作,数据库可以利用事务的只读特性来进行一些特定的优化。我们可以通过将事务声明为只读,让数据库对我们的事务操作进行优化。
事务配置五、回滚规则
回滚规则,就是程序发生了什么会造成回滚,这里我们可以进行设置 RuntimeException 或者 Error。
默认情况下,事务只有遇到运行期异常时才会回滚,而在遇到检查型异常时不会回滚。
我们可以声明事务在遇到特定的异常进行回滚。同样,我们也可以声明事务遇到特定的异常不回滚,即使这些异常是运行期异常。
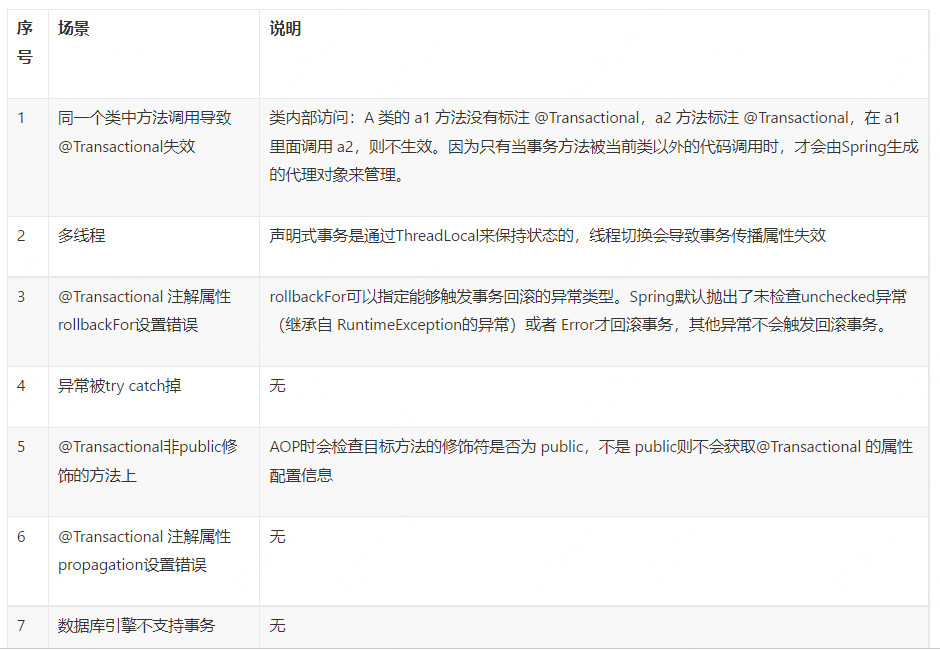
声明式事务失效的场景
事务同步管理器
Spring 中有一个事务同步管理器类
TransactionSynchronizationManager,它提供了事务提交后处理等相关回调注册的方法。当我们有业务需要在事务提交过后进行某一项或者某一系列的业务操作时候我们就可以使用
TransactionSynchronizationManager。
事务请求处理链路示例
下图为全链路的从应用发起到开启事务,到业务逻辑处理(SQL 执行),最后关闭事务的正向链路。
事务实践相关
数据一致性
同一个数据源的操作在一个事务内可保证一致,但实际场景中会因为不同事务或不同数据源(不同关系数据库、缓存或远端服务)而导致数据不能强一致。在 CAP 理论框架下,我们一般是保证可用性、分区容错性,基于 BASE 理论达到最终一致性。但如何达到数据的最终一致性需要合理设计。
数据库的提交、缓存的更新、RPC 的执行、消息的发送的先后顺序
一般我们以数据库数据为准,先数据库提交,再更新缓存或发送消息,通过异步轮询补偿的方式保证异常情况下的最终一致性。
不建议用法:
1、事务回滚会导致缓存和数据库不一致
2、事务回滚会导致消息接收方收到的数据状态错误
建议用法:
1、先更新数据库,事务提交后再更新缓存或发送消息
2、通过异步异常重试或批处理同步来保证数据的最终一致性
3、核心交易以数据库数据为准
系统健壮性增强,但编程模型复杂一些
长事务
如果事务中有耗时长的 SQL 或有 RPC 操作可能会导致事务时间变长,会导致并发量大的情况下数据库连接池被占满,应用无法获取连接资源,在主从架构中会导致主从延时变大。
建议事务粒度尽量小,事务中尽量少包含 RPC 操作。事务尽量放在下层。
不建议用法
建议用法
这种方式需要应用程序保证多个事务操作的最终一致性,一般可通过异常重试来实现。
事务代码层级
事务该加在哪一层?放在上层的优点是编程简单,放在底层则需要需要在一个事务的操作封装在一起沉淀到底层。
对于传统架构(如下图),建议在 DAO 层和 Manager 层加事务。Service 层可以有,但重的 Service 或有 rpc 的 Service 操作慎用。
对于领域设计类架构(如下图),从 DDD 的思想上,建议放在 APP 层(基础设施不应是领域层关注的),但考虑到长事务问题,不建议放在 APP 层,更建议优先放在基础设施层,domain 的 service 层也可有。
总结
以上对事务的常用知识进行了总结整理,相关实践规范有的并无完美固定答案,需要结合实际而论,欢迎大家留言沟通!