音视频测试 Jan Ozer:高清直播互动场景下的硬编码如何选型?
前言
高清直播逐渐普及,硬编码也成为大势所趋。在 RTE 2022 大会上,来自 NETINT 的 Jan Ozer 通过一系列的对比测试结果,详细分享了如何为高清直播互动场景进行硬编码的技术选型。
* 本文内容基于演讲内容进行整理,为方便阅读略有删改。关注「声网开发者」公众号回复关键词「1102」,即可领取完整版 PPT;点击文末图片或阅读原文,即可回看完整版演讲视频。

大家好,我是 Jan Ozer。今天我们要讨论的是高清直播场景中的编码技术。我们将聚焦于高清(High-density)视频直播场景进行今天的分享。如大家所见,市场越来越青睐高数据量流媒体,硬件编码也成为了大势所趋。
有四种编码方式供大家选择:CPU、GPU、FPGA 和 ASIC,接下来我们来聊聊该如何选择。
其实就是具体要考虑不同编码方式的特性、成本(资本支出和运维支出)和能耗,很明显能耗也会影响运维支出以及碳排放问题。
做任何选择都要从找到你的工作点(operating point)开始,演讲末尾会着重说明这一点。
我们关注的是高清视频直播流媒体,比如云游戏、互动视频、AR、VR 和元宇宙等,不涉及视频点播场景。
演讲中只会谈到视频点播的质量问题和 ASIC 在这方面的表现,但讨论重点还是直播转码。
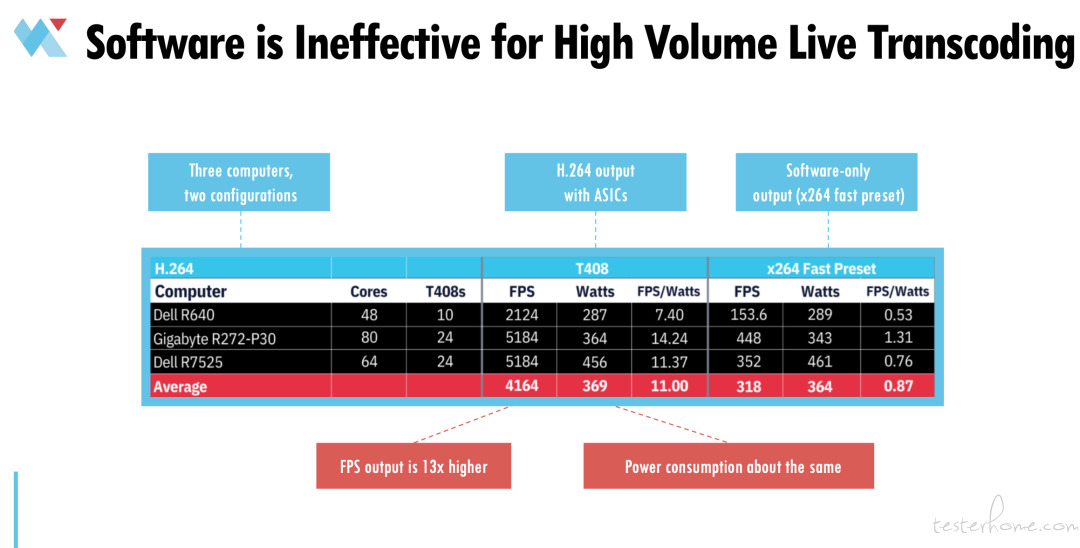
第一点:软件编码对高流量的直播转码来说较为低效,这个实验会告诉你为什么。
我们用三台不同的电脑进行测试:戴尔 R640、技嘉 R272 和戴尔 R7525。核心数的配置分别是 48、80 和 64。然后,我们还给这三台设备安装了 T408 转码卡进行测试。配置分别为 10、24 和 24。我们测量了这两种方法的性能:安装 T408 且使用 ASIC 的情况下,对比只用软件,使用 X264 快速预设情况下各设备的 FPS(每秒传输帧数)。测试性能包括:FPS,能耗,以及这三台电脑在每个配置中每瓦特的 FPS。
我们发现,两种情况下,使用 T408 的 FPS 要高 13 倍,耗电量相近。虽然必须给 T408 供电,但是因为原来计算机大部分电力都供给 CPU,而如果安装了 T408,CPU 工作量会减少很多。所以两种情况下,整体耗电量是差不多的。
也就是说一台 NVME 服务器,一台安装了 10 个或 24 个 T408 的服务器性能相当于约 13.1 台只用软件进行编码的电脑。

因此,软件编码意味着 7 到 8 倍的成本支出,13 倍的功耗。
使用 HEVC 的情况会更糟糕。因为它是很复杂的一种编解码器。如果在只用软件的情况下,运行会非常缓慢。
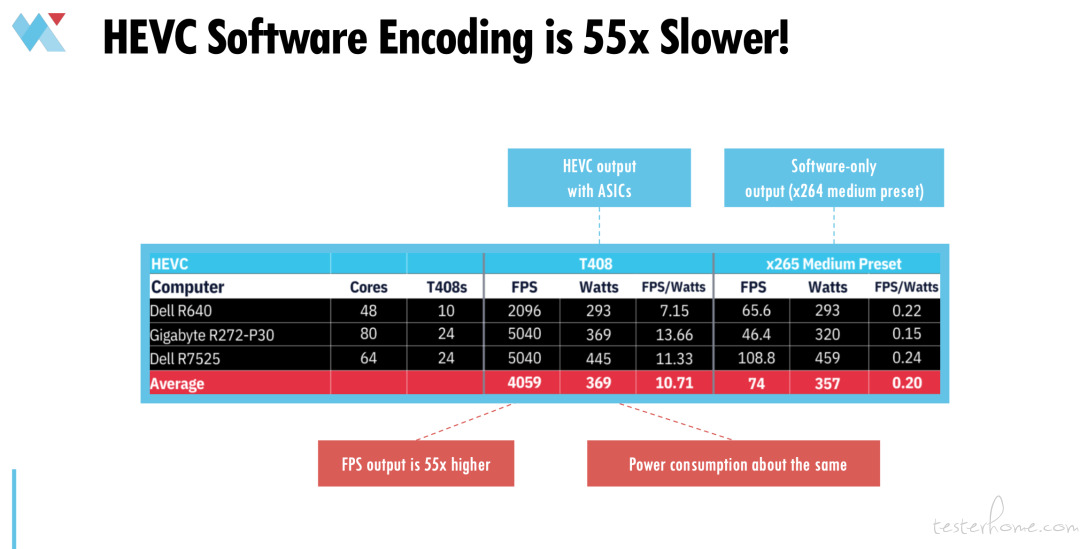
如上图这组测试中,我们用搭载 ASICS 的 HEVC 和使用 X264 medium 预设的纯软件做比较。同样,测试指标为 FPS,瓦特和每瓦特的 FPS。
可以看到,相比而言 T408 的 FPS 比纯软件高出 55%。而两者的耗电量还是差不多。
结论表明,不论是从资本支出,还是运维支出的角度来看,纯软件编码对直播流媒体应用来说都太昂贵了。
因此,我们来看一下用硬件替代的方案。选择有 CPU、GPU、FPGA 和 ASIC。你会如何从它们中选择呢?
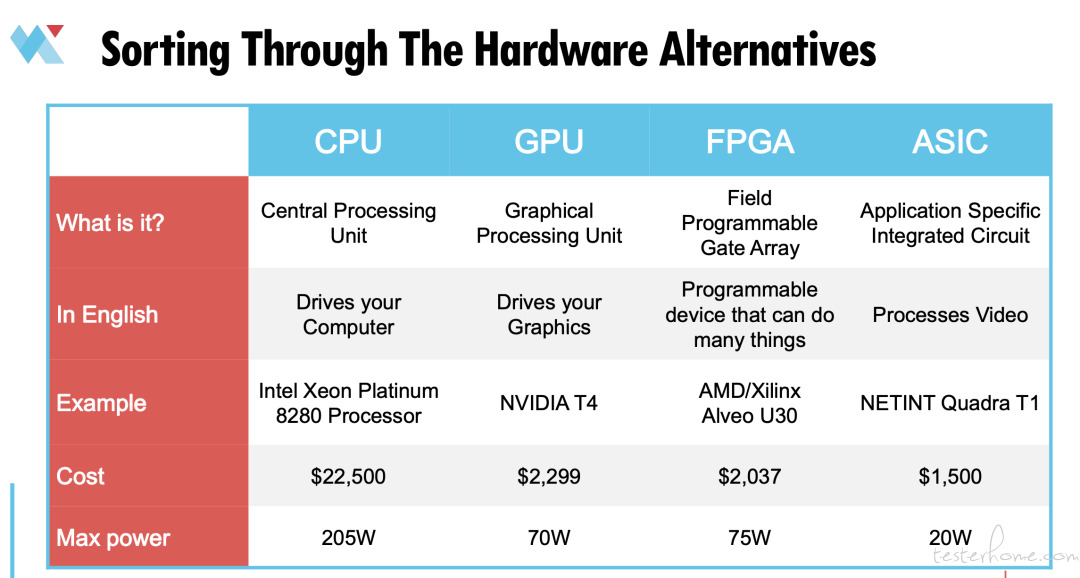
让我们先来梳理一下这些硬件选项:CPU,中央处理器;GPU,图形处理器;FPGA 是现场可编程门阵列;ASIC 是专用集成电路。
通俗来讲是什么意思呢?
CPU 是驱动整个计算机的通用处理器。
GPU 是可以驱动图形以及执行其他功能的通用处理器。
FPGA 是一种可编程的设备,你可以用它来做很多事情。
ASIC,当它以压缩视频为目的产生时,它所做的就是处理视频。
对应的产品例子有:英特尔 Intel Xeon Platinum 8280 处理器,22500 美元,英伟达 T4,2299 美元,AMD/Xilinx Alveo U30,大概 2000 美元。还有这次演讲中会提到的 NETINT Quadra T1,它的价格约为 1500 美元。
如上图所示,每一种硬件的最大功率也不同。CPU 的功率最大,而由于 ASIC 只需要处理视频,所以它的功率最小。
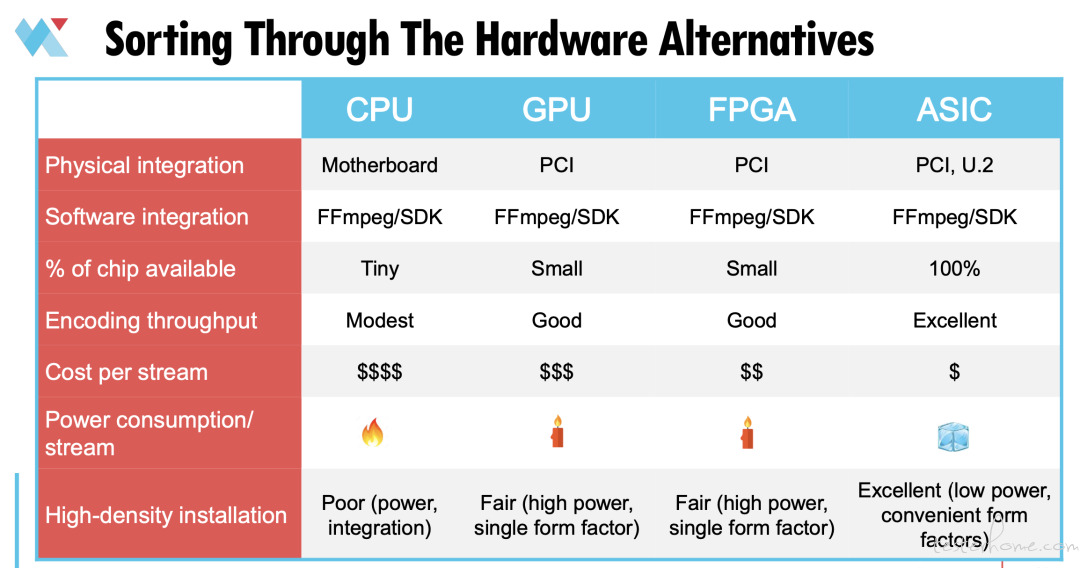
接下来,让我们对这些硬件选项进一步分类。怎样能把这些硬件添加到服务器上呢?
CPU 通常放在主板上。GPU 和 FPGA 放在 PCI 插槽中。像 Netint 的 Quadra 单元这种 ASIC 既可以放在 PCI 插槽中,也可以放在 U.2 插槽中。U.2 是一种非常有效的方式,可以在服务器上添加多张转码卡。
不同的设备之间,软件集成是类似的。大多数都有 FFmpeg 和或 Gstreamer 功能,以及用于软件开发的独立 SDK。
而说到用于转码的芯片可用率:CPU 非常小。CPU 是一个通用设备。因此该设备中只有一小部分是专门用于视频转码的。GPU 要好一点。FPGA 也可以。但 ASIC 的芯片完全是为视频处理而设计的。这意味着它在功率和吞吐量方面的效率都更高。
关于编码的吞吐量:因为 CPU 可用于视频转码的部分很少,所以从设备的总体门数来看,总体吞吐量会相对较小。GPU 和 FPGA 好一点。ASIC 表现优秀。因为它就是为视频处理而生的。
综上所述,按流的成本来计算的话,CPU 是最贵的。GPU 和 FPG A 会便宜一点,但 ASIC 通常才是最实惠的选择。
参考上一张幻灯片里各项的功耗,因为 CPU 的功耗非常高,流的输出又非常低,它每个流的功耗会非常高。GPU 和 FPGA 每个流的功耗稍低一点,但最效率最高的还是 ASIC。
那么,高清应用选其中哪一种呢?
CPU 并不适用于高清应用。因为它需要大量电力,且物理集成必须在主板上。选 GPU 和 FPGA 会稍好一些。这两种硬件都采用 PCI 形式,功耗更低。但 ASIC 会是最佳选择。因为它的功耗最低,且它的外形尺寸最方便集成到服务器中。
那么,像 Youtube 这样的产品会选择哪种方案呢?
它们采用的是 Argos,google 自研的专用于视频转/编码处理单元。在采用 Argos 时,Youtube 选择了 ASIC。因为它是处理视频最有效的方式。
我们认为对于其他公司来说,同样是 ASIC 的 Quadra 可以成为他们的 Argos。这样说是因为,大多数公司无法设计自己的 ASIC。其实没有必要自己来,因为大家可以从 Netint 购买 ASIC 服务,比如 T408,或者 Quadra(接下来会详细介绍)。

那么,到底应该怎样在这些备选方案中选择呢?我会按如上图的顺序进行说明。首先明确各硬件功能,确保它可以满足你的需求。然后了解影响质量和吞吐量的因素,再用各种内容类型进行测试。接下来,选择你的最优点。等下我们会详细讨论这一块。然后进行计算。计算每个流的成本和使用该最优点的每个流的质量。

如上图,是你要检查的硬件功能表,表中已标注了 NETINT Quadra 一项。可以看到,Quadra 支持 H.264、HEVC 和 AV1。在处理功能方面,Quadra 可以进行解码、编码、缩放和叠加,甚至还有人工智能,第三方编码器通常都不具备这项功能。

现在,在了解特定设备上包括哪些功能后,你需要确保在使用该设备生成文件的命令流中包含这些功能。以 NETINT Quadra 的命令流为例,这条流用于解码,即使用硬件解码器。如果命令流里不包含解码这一条,而是直接进入源文件,那你只能使用软件来解码,这会降低整体吞吐量。
这里是用 NETINT Quadra 选择 H.264 编解码器。这里是用 NETINT Quadra 进行缩放。第一个个 rung 是在源分辨率下生成,所以没有缩放。下面的 rung 按比例从 1080p 缩放到 720p。而命令流中没有包含所有所需硬件功能,就会影响到最终的吞吐量。得到的吞吐量会比使用卡上所有可用硬件功能所得到的量要少。

接下来,我们来谈谈质量问题。在大多数直播转码中,我们通常会用相对较低的质量预设部署应用,以减少计算周期,实现吞吐量。如果你用 x.264/x.265 进行转码,你通常在高水平情况下使用中等预设,在低水平情况下使用超快或非常快的预设。而如果是 SVT-AV1,你必须使用 10-12 范围内的预设,以达到完成实时操作所需的吞吐量。
如今,大多数硬件编码器的质量都在这个范围内,所以结果不会和那些使用更慢或更高质量预设的软件编码器相同,但会用于直播转码应用的软件质量相同,该软件用的是典型预设。
为什么呢?因为硬件限制了操作。为了获得适当的吞吐量,当你转码时,你需要硬件吞吐量,这就是为什么质量被设置在这个范围。我们稍后会详述这个问题。
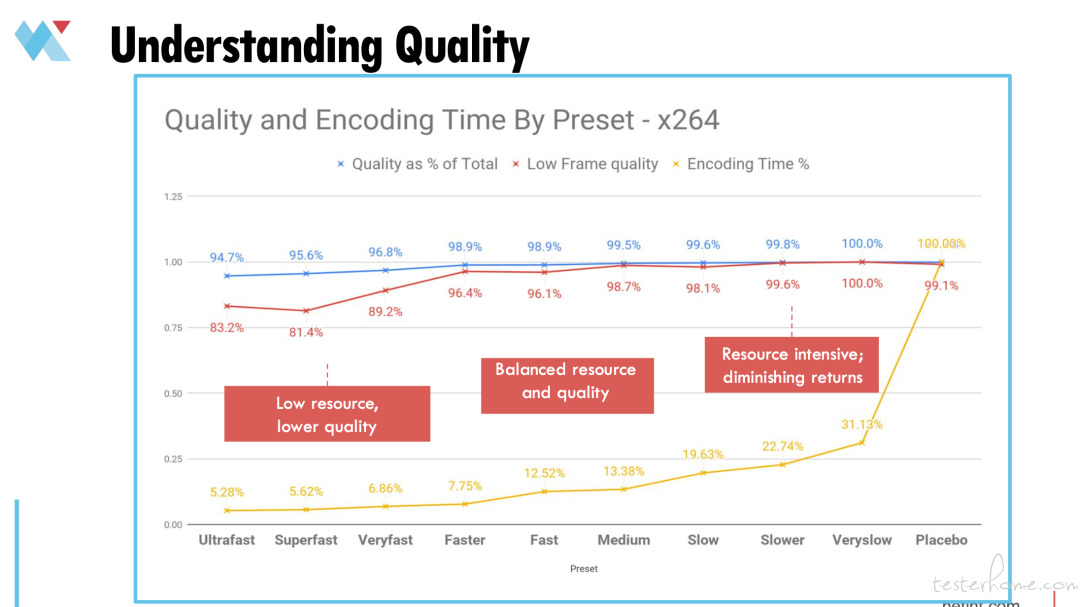
如图,图中展示了使用 X.264 编解码器按预设产生的质量和编码时间。最下面这根曲线代表编码时间。可以看到,从编程时间占比非常少的情况,一直到到非常慢预设这里。曲线开始很低,然后骤升。蓝色曲线代表整体 VMAF 质量。红色曲线代表低帧质量,用来衡量瞬态质量的倾向。在这一点我们会得到相对低的资源和更低的质量。但这是直播转码时必须做的,以此来获得吞吐量。这就是资源和质量的平衡。
而这一点,在中等预设下我们会获得 99.5% 的质量,与我们在非常慢预设情况下,获得的最高质量相同。而 96.1% 的低帧质量是在大约 12.5% 的编码时间实现的,但其实在该时间条件下,你会致力于实现非常慢的,或极慢预设。
上述说明了资源和质量的平衡。这是真正的收益递减。因为在你的编码时间显著增加时,质量增长并不是那么显著。因此,对于大多数不需要直播运维的视频点播编码来讲,不管预设是中等,较慢还是非常缓慢(通常不会用极慢预设,因为无论怎样都不能拿到最好的质量),你投入了 3 倍的编码时间,只能获得微不足道的质量优势。而对直播制作来说,问题在于我们一直在谈论的吞吐量。
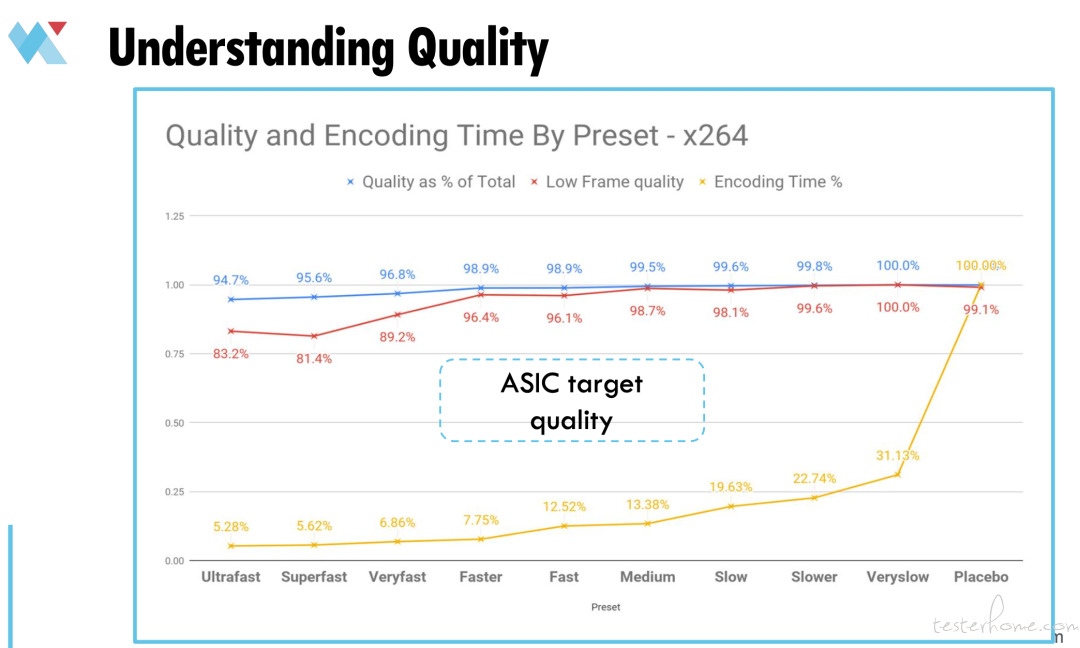
通常是 HEVC 使用超高速预设,H.264 非常快,结果不会超过中等质量。就 Quadra 而言,这里是这些设备的总体质量目标。之后我们会展开说明这里的数字。

我想做个实验,看看相比我们刚才看到的软件预设和 NVIDIA T4, Quadra 的质量是多少。所以我对五个文件进行了编码:足球游戏、钢铁之泪、侠盗飞车、子午线和奇幻的晚宴,然后用不同的阶梯生成 85 至 95 的 VMAF。
我对侠盗飞车的文件进行了编码,剪辑成 6Mbps 的速度,拉低了所有平均数。所以虽然我的目标是 85 到 95,但因为我们生成了 6Mbps 的 GTAV,VMAF 的总体平均数会更低一些。稍后会在速率失真曲线上具体展现。
通常一些人会使用的最大值,1080p 。我使用的编码参数:是我用 NVIDIA 生成的。这是我在网上找到的两个文件中学来的,你可以从网上找到,并了解他们推荐的方法。然后我测量了整体的 VMAF 和低帧 VMAF,刚才我有提到过,它可以衡量瞬态质量的倾向。我们来看看这些速率失真曲线。红色代表 Quadra,绿色代表 NVIDIA,紫色代表 VeryFast 配置,蓝色代表中等配置。这是 H.264 总体的 VMAF 质量。
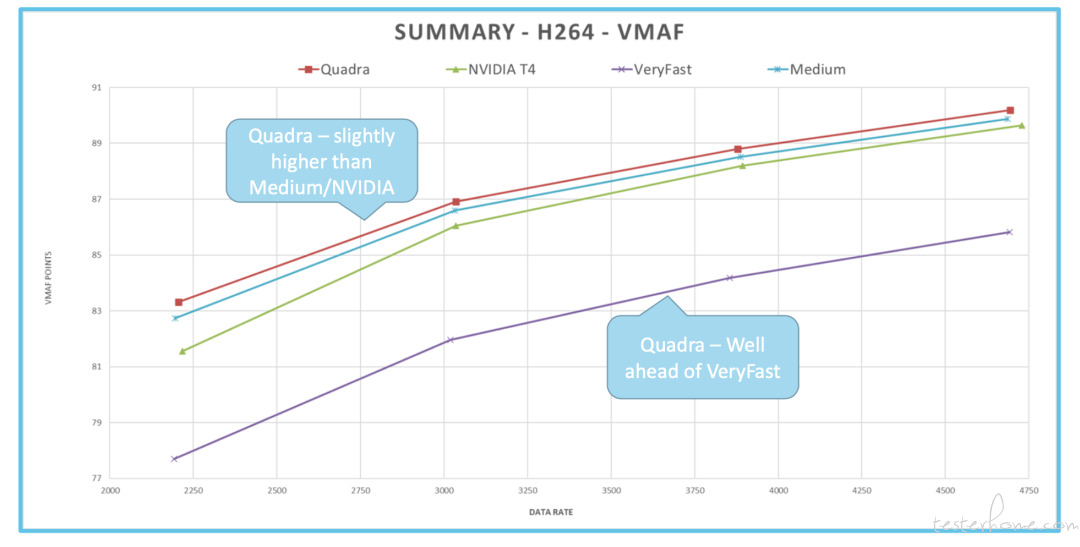
可以看到 Quadra、NVIDIA 和 Medium 预设之间的分数非常接近, Quadra 比 Medium 和 NVIDIA 稍微高一点。而 Quadra 遥遥领先于 VeryFast 预设。
我们一般使用 H.264 的最低质量预设就是 VeryFast,因为可以得到较好的吞吐量,质量也不错。可以看到,NVIDIA 和 NETIENT 的表现都比 VeryFast 好很多。
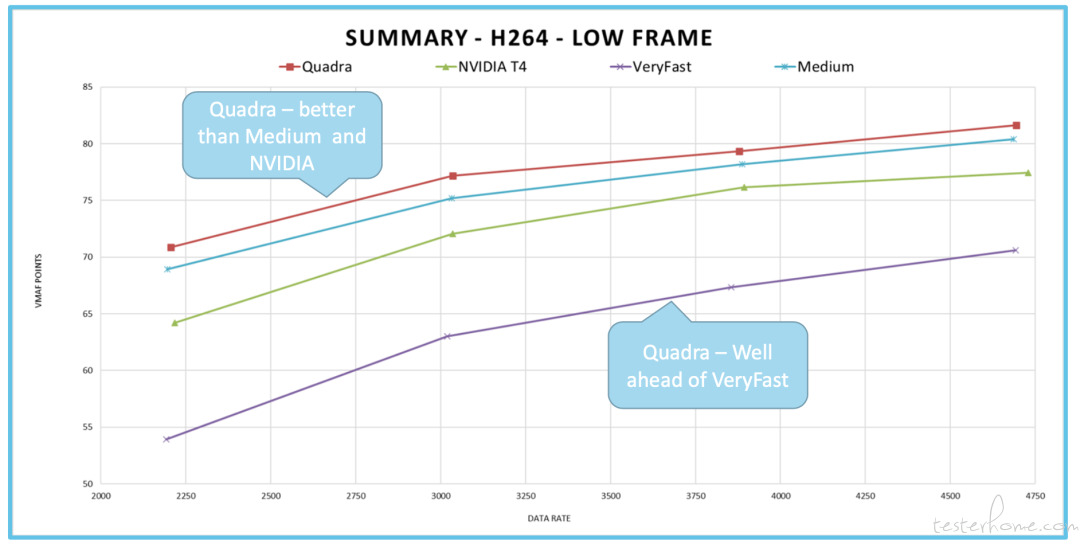
然后再来看看低帧分数,如上图,同样也有瞬态质量的倾向。可以看到 Quadra 的表现要好于 Medium 和 NVIDIA,而 Medium 处于两者之间,较好于 NVIDIA。Quadra 遥遥领先于 VeryFast,后者更容易存在低帧率问题。
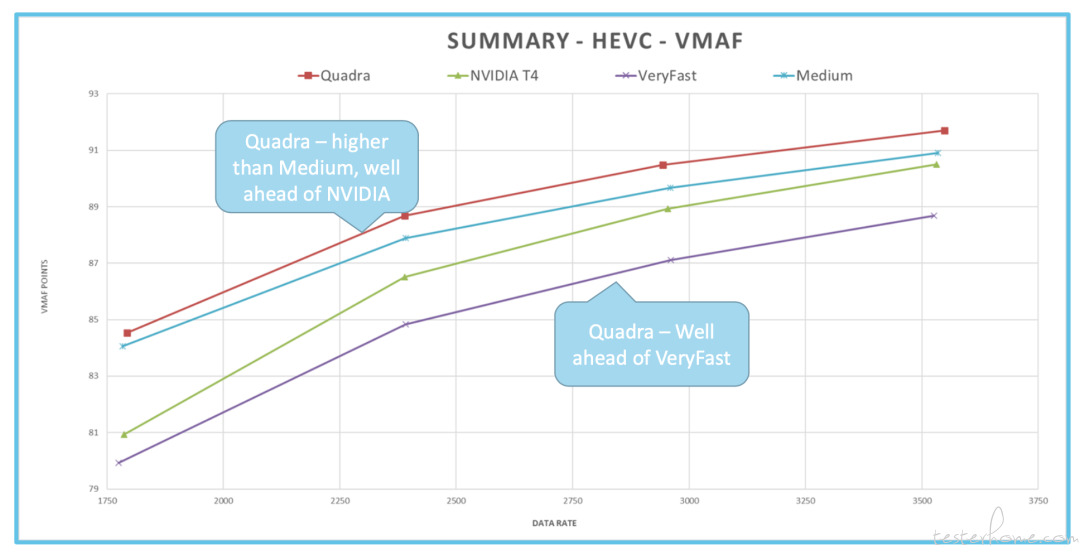
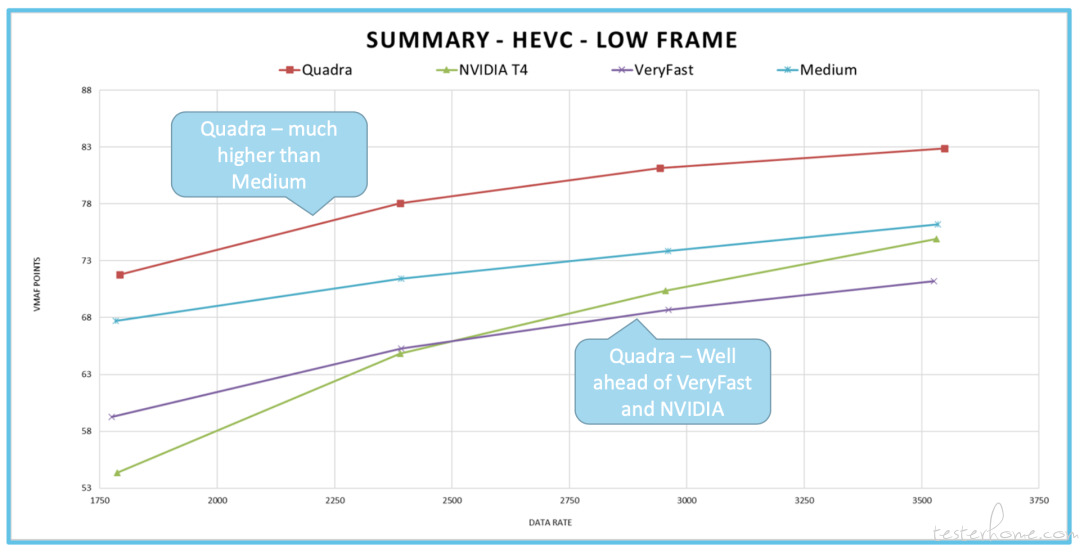
HEVC 也是一样。Quadra 的分数较高于 Medium,优于 NVIDIA,同时远超 VeryFast 预设。在低帧分数中,Quadra 比 Meduim 高的就比较多了,同时远超 NVIDIA 和 VeryFast。
总结一下,在选择你的 Operating point 时,要多加考虑。但最基本的事实是,Quadra 在 H.264 和 HEVC 中能提供中等以上的质量,吞吐量更高,能耗更小。
这给我们留下了一些提醒:我不是 NIVIDIA 编码专家,这是我第一次尝试用 T4 进行高容量转码。我尽力去把他们一一对应作比较。但是各位应该自己进行测试,如果有任何问题,应直接联系 NVIDIA,确保操作无误。
接下来我们就谈一谈之前提到多次的最优点。
最优点就是各位在制作中使用的编码参数,这些参数为应用提供了质量和吞吐量的最优结合。我们关注最优点时因为所有的供应商都会给出吞吐量数据和质量结果。但他们不会在质量和吞吐量中使用相同的配置。现在各位应该明白最优点的重要性了。
所以各位在比较硬件设施时,第一步就是确认影响质量和性能的配置选项。在 NETINT 中,影响质量和性能的关键配置是 Lookahead,即编码帧之前帧。这样编码器就知道接下来会发生什么,从而提升编码质量,尤其是当场景正在或即将改变时,可以提高比特率效率。这会降低性能,减少吞吐量,当然也会增加 Lookahead 的延迟。
下面我们来看一看 Lookahead 的定性影响。这是莫斯科州立大学视频质量测量工具的结果图。展示了逐帧比较两个文件的 VMAF 分数结果。红色部分有 40 帧的 Lookahead 编码区,而绿色部分则没有 Lookahead 编码区。可以看到没有 Lookahead 的区域有非常多的低帧。这些都是瞬态质量问题的潜在区域。
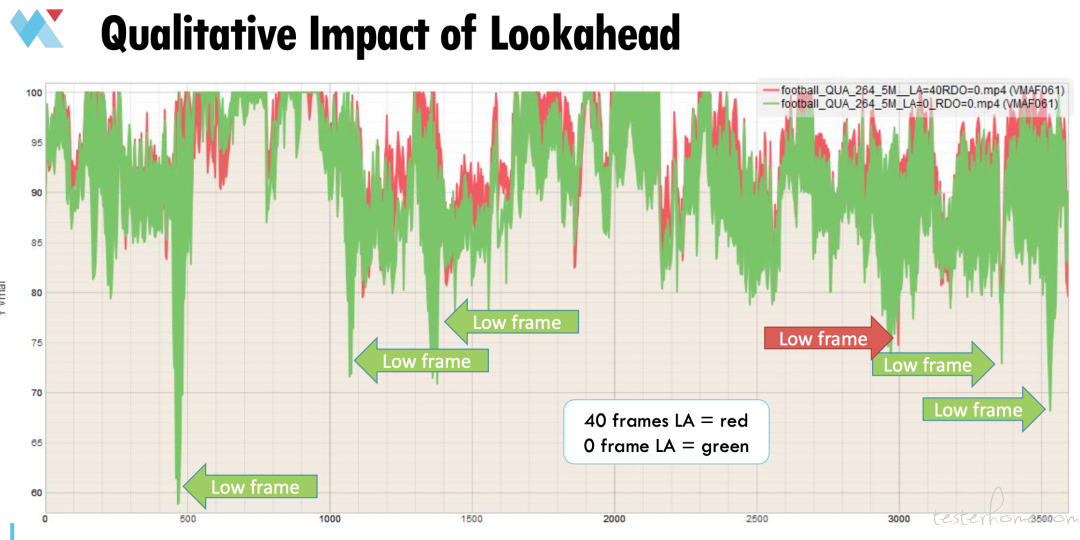
所以 Lookahead 确实会影响你的低帧分数。这些分数说明了什么呢?
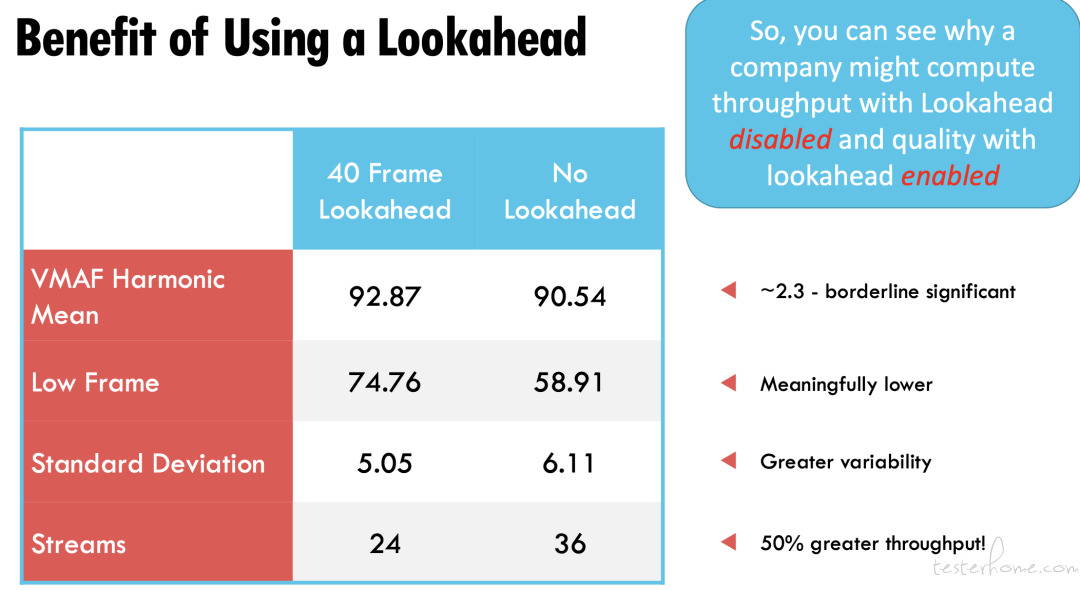
就使用调和平均值计算的总体 VMAF 分数而言,我们可以看到有 2.3 VMAF 分的差值,这有明显的差异。一些研究者认为观看者可以辨认出 VMAF 3 分的差别。在低帧分数中,差值非常显著,从 75 分降到了 59 分。观看者肯定可以注意到两个剪辑中的低帧区域。标准差可以衡量质量可变性,这里有 1 分的差值,也是比较显著的。但在吞吐量中,不使用 Lookahead 的部分与使用 40 帧 Lookahead 的高出了 50%。这样你就能明白,为什么公司可能在计算吞吐量时禁用 Lookahead,而在计算质量时启用 Lookahead。这也是我们在比较 NVIDIA 和 NETINT 时要研究的核心问题。
在 NETINT 中可以改变的另一个配置选项是率失真优化(RDO),预设基本上就是 RDO。RDO 可以提升质量,但会减少吞吐量。了解了最能影响质量和吞吐量的配置选项后,你可以创建各种测试来运行这些配置选项,从最复杂、质量最高的,到最简单、质量最低的。(在 Jan 的演讲中,详细分享了一些 NETINT 的测试数据,感兴趣的可以在文末扫码观看演讲回放。)

总结一下,当你比较硬解码器时,首先要明确最能影响质量和吞吐量的关键配置选项,测试多种配置来确定 OP。使用这些参数来测试多个文件的质量和吞吐量。使用技术来输出最佳的质量组合,包括平均帧和低帧、资本支出和运维支出,以及能耗。
(正文完)
点击此处即可查看完整视频回顾