前言
作为互联网行业的产研工作者,日常免不了经常和测试环境打交道。打过交道的人,都深有体会,测试环境真是又爱又恨。
- 爱它,必不可少,能在研发阶段帮自己尽早的发现代码缺陷;
- 恨它,
- 方便性不足。想用的时候不一定能立刻使用,它可能处于不健康状态,或者有其他人正在使用,需要排队;
- 稳定性不足。经常遇到测试 5 分钟,问题排查 2 小时,最后发现是环境故障原因导致,而非代码缺陷;
- 维护难。为了测试流程的便捷,测试环境的变更流程一般很宽松,这也同样导致随意修改服务部署配置的情况时有发生;
以上的总结,也不能完全代表同行的情况,因为根据业务和资源投入差异,痛点的表现也会各异。本文,我会从我个人近几年的实际工作经历出发,分享我遇到的测试环境管理的痛点,以及我是如何一步步优化解决的。
过去 3 年,我也一直在和这个又爱又恨的家伙纠缠。3 年里,我服务的产研团队正好有 3 次变更,因此有 3 次重新定义 “测试环境” 这款产品的机会。
对,我把 “测试环境” 称为一款产品。因为它有相对明确的用户和功能需求,因此设计者可以去定义对应的产品系统和使用规则。从整个软件交付链条上看,它是属于 DevOps 的一环。
我一直坚信:测试环境是研发效能的关键生产力。
第一次尝试
我第一次服务的团队是一个基础设施团队。团队产品的特点是:
- 老产品,服务多,服务部署配置复杂;
- 中间件使用广泛;
- 对物理磁盘有强依赖;
- 产品本身没有容器化,物理机部署模式;
测试环境原来的状况:
- 开发本地可以运行一套 mini 版的测试环境,方便日常开发测试;
- 物理机有两套公用测试环境 dev 和 beta,是生产环境的缩小版。beta 环境是 QA 独占日常测试使用,dev 除了给 QA 日常测试使用,还会提供给公司其他团队作为基础设施使用。所以定位上,beta 是不稳定的测试环境,dev 是相对稳定的预发布环境;
很显然,这样的配置也会有开篇所讲的诸多问题。资源上,不够用;维护上,很痛苦。
从很早开始,我们团队就坚信,云原生是解决测试环境脏乱差问题的最佳方案。理由有三:
- 方便性:随起随停;
- 稳定性:云原生基础设施提供保障;
- 可维护性:everything as code,一言不和摧毁重来;
当然,理想是美好的,要打磨产品到用户最佳使用姿势,是我今天想分享的核心。
最开始我们采用了偏极客路线的方案:纯本地管理方案。啥意思?我们深入分析一下我们要解决测试环境脏乱差的问题,具体是要解决哪些问题。对于使用者,有这么几个:
- 创建,包括从 0 到 1 创建一套环境,新增一个服务等;
- 更新,包括服务镜像,配置信息,部署结构等;
- 查询,包括服务的状态,配置信息,日志,使用的资源情况等;
- 删除,包括删除一套环境,删除一个服务或者配置等;
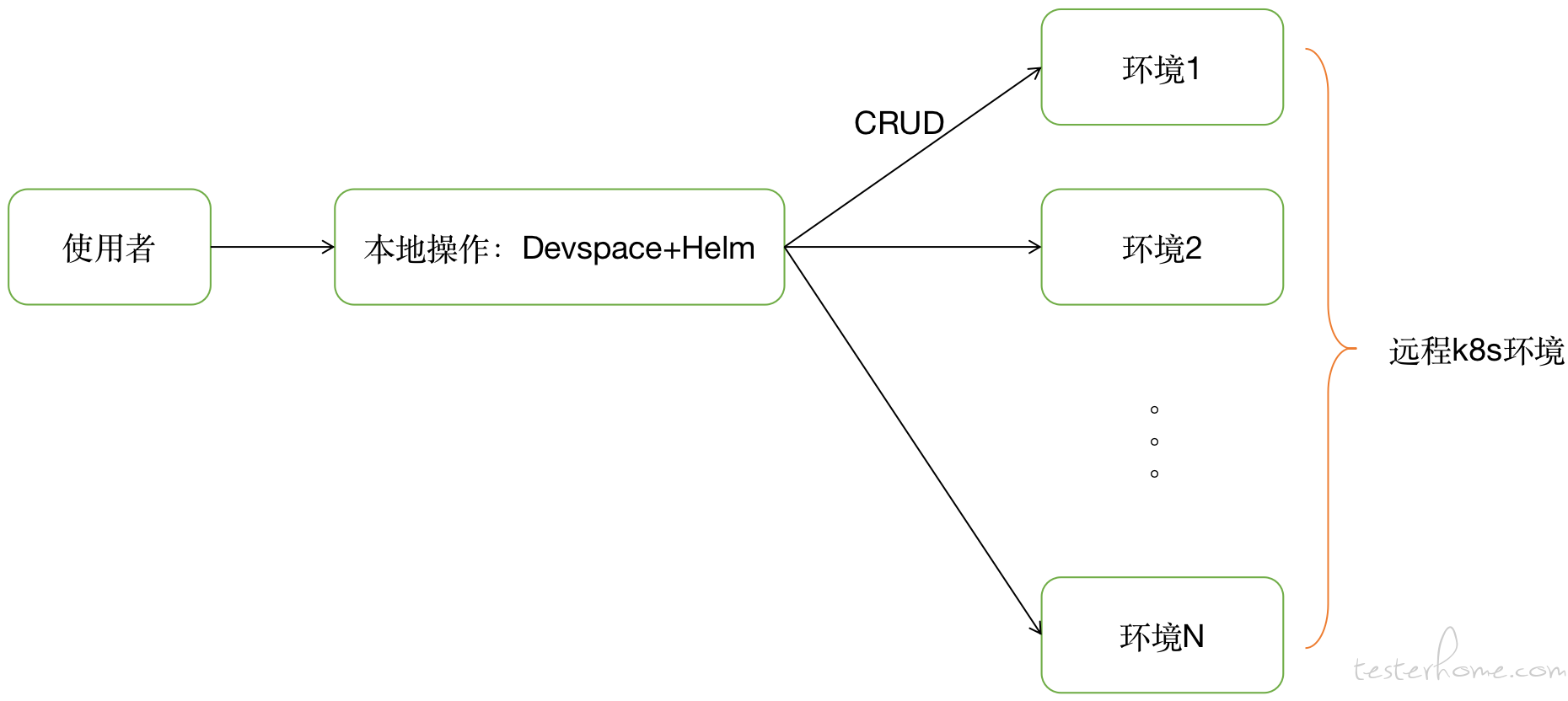
这不就是 CRUD 嘛。对,我认为使用者对测试环境的管理需求抽象下来就是我们熟悉的 4 大类。
而我们的 “纯本地管理方案” 就是 CRUD 都是让使用者在本地完成。组合使用一些开源方案来实现:devspace+helm。
- 使用devspace管理本地的 CICD 和环境管理;
- 使用helm管理环境部署;
理念是希望使用者本地一边编写代码一边可以很方便快速的更新远程环境来测试验证。我们觉得这不就是极客们希望的一种实时高效的最佳体验嘛?
最后执行下来,效果并不佳。使用者,确切的说是开发们不愿意使用。从细节分析,有这么几点:
- 产品上:
- 产品目标没想清楚,我们设定的目标是提供一套通用统一的测试环境使用方案,替换掉物理机公用的 dev 和 beta 以及开发者本地调试测试使用的 mini 环境,而我们的方案 PK 本地的 mini 环境优势其实并不明显,而且还有切换成本;
- 技术上:
- 云原生的使用有门槛,短时间熟练上手比较难,导致开发者主动学习意愿不强;
第一次的尝试虽然没有达到预期的效果,但是收获肯定还是有的。不管是技术积累上,还是产品的打磨上。
第二次优化
后来因为一次团队调整,我去到一个大数据产品小组参加质量建设工作。正如开篇所讲,不同性质的业务在 DevOps 链条上的使用姿势和痛点是有差异的。
先介绍一下团队原来的测试环境状况:
- 产品本身主要是做私有交付,基本都是物理机方式交付;
- 开发者使用本地启动 mini 测试环境不多,原因是大数据类的服务资源消耗高,且对测试数据量和分布式部署有需求,本地测试局限性比较高;
- 物理机提供公用的 3 套左右测试环境 +1 套预发布环境,需要使用的时候互相协调;
- 比较明显的问题是:
- 公用测试环境治理混乱。经常由于一些脏数据,测试环境不稳定等原因导致测试 5min,排查 2h,严重拖慢研发效率;
- 产品交付质量差。部分原因也是由于环境稳定性不足,自动化测试回归的成功率比较低,长期导致使用者对自动化回归的信任度降低,选择性忽略失败,恶性循环之后影响产品交付质量;
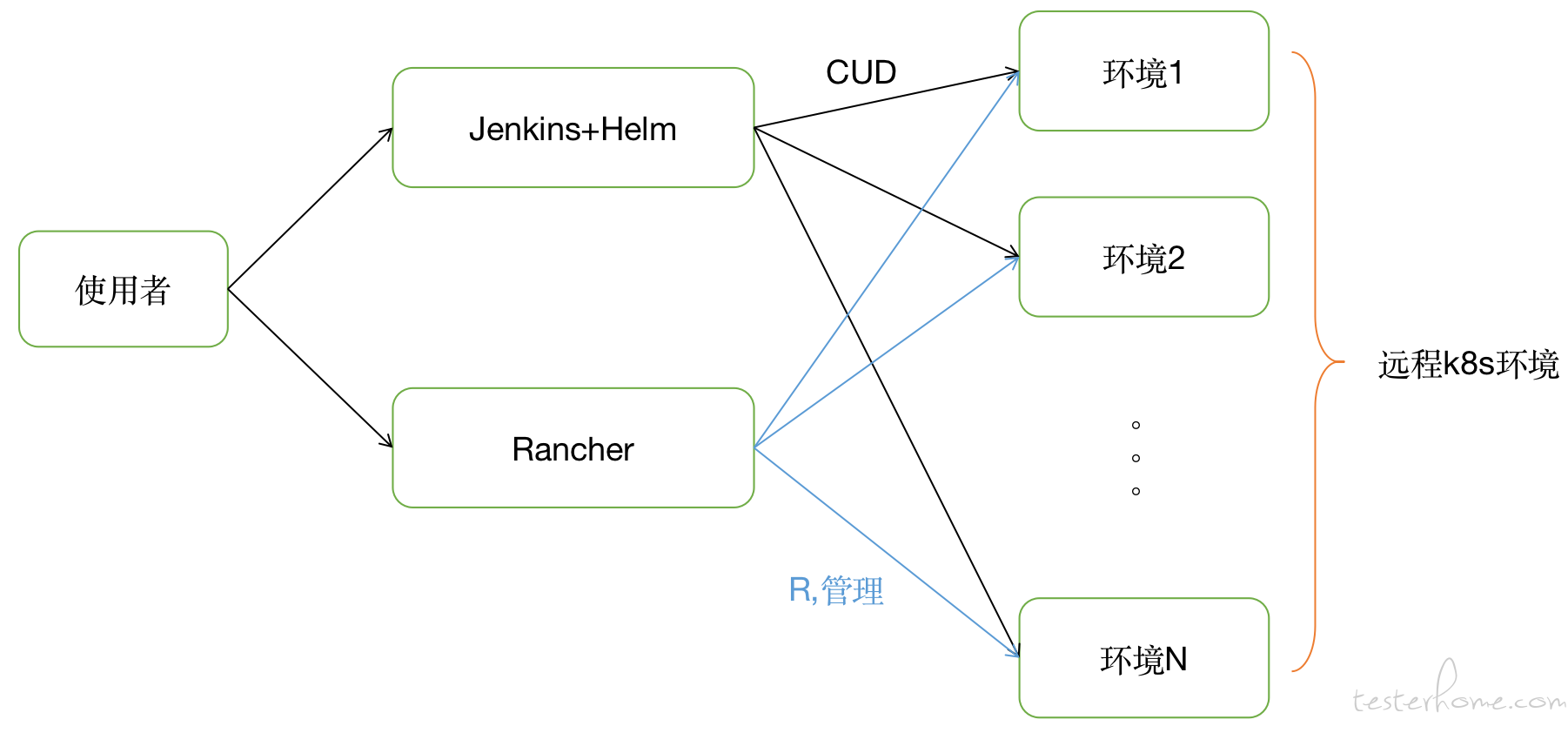
基于之前尝试的经验,这一次我们的方案做了一些调整,Jenkins+helm+Rancher:
- 首先,继续坚定使用云原生方案,这个宗旨不变;
- 环境的构建更新删除(CUD)使用开发者原本熟悉的 CICD 平台 jenkins 来实现。将 CUD 的门槛降到最低;
- 环境的管理(R)使用 rancher 平台来引导开发者使用。降低开发者学习使用 k8s 的成本;
- 环境的部署配置依旧采用 helm 来管理;
仔细想想,我们其实没有做什么创新,不过是在组合一些开源已有工具来打磨成我们产品的最佳方案。
这一次推广效果还是可以的。开发者几分钟内就可以创建一个独占环境,创建的过程不需要额外学习新技能。加上,业务本身有大量开发任务需要保持一段时间的前后端联调状态,这种环境模式特别适合前后端协作。也促使使用者主动选择使用。
不过,推行一段时间后,也暴露了一些不足之处,总结如下:
- 资源浪费问题开始显现。创建一个独占环境过于容易,加上没有一个集中管理这些环境的地方,导致历史使用过已经不再使用的环境还一直存在;
- 开发者对 k8s 的使用熟悉程度增加不多,我们的 support 工作过于繁重。CICD 流程和环境管理是在不同的平台,这在使用上会带来一些不便。所以,在推行很久之后,开发者在环境使用过程中遇到问题还是需要跟我们求助 support,对 k8s 的使用熟悉程度上进步不是特别大。另外,我个人认为 rancher 本身是面向相对专业的 k8s 运维管理人员使用的平台,对于新手使用稍显复杂;
- Jenkins 用作云原生的 CICD 平台其实不是特别合适,功能上只是能凑合用。方案上选它只是因为开发者对它比较熟悉,上手无学习成本;
第三次改进
再后来,我又经历了一次工作变动,来到了一个管理资源的微服务架构产品团队。这是一个全新的团队,所以测试环境需要从 0 到 1 全新构建。
这一次,总结之前的经验,方案上我又做了一些调整。
这一次,我选了一个开源方案组合:zadig+helm。
- Zadig 负责测试环境的 CRUD,以及生产环境交付的 pipeline;
- 环境的部署配置依旧采用 helm 来管理;
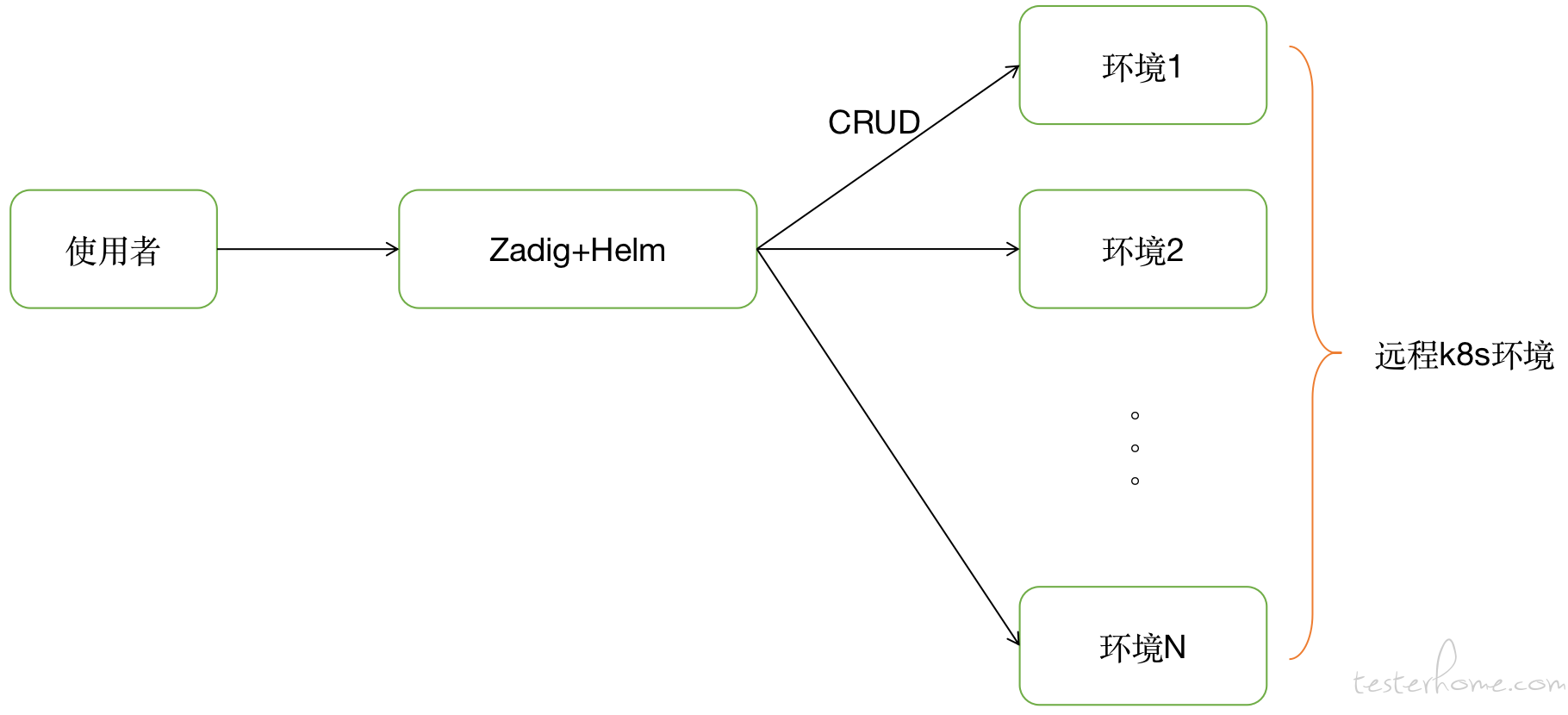
Zadig 是一款专注于云原生的交付平台的开源产品,来自于一家中国初创公司。
为什么选用了 Zadig?
从前两次的经验可以看到,对于使用者来说:
- 解决痛点;(功能)
- 使用心智负担小;(体验)
- 学习成本低;(门槛)
永远是王道。前两种方案,都是体验和门槛上不佳。
Zadig 在测试环境的管理上把心智负担和学习成本做得比较低:
- 学习成本:测试环境的 CRUD 只需要在前端页面上点点点就可以完成;
- 使用心智负担:对于不熟悉 k8s 的使用者,也可以立马上手使用;
对于推广方案的我们来说,会减轻很多支持负担,尽可能的做到赋能给业务团队自助完成。另外,Zadig 本身还是一个云原生 CICD 平台,所以生产交付的 pipeline 也可以一起管理。这点对使用者的体验以及内部平台管理者也比较加分。
当然,个人觉得,Zadig 也不是完美的,它比较适合业务属性比较重的微服务架构业务,需要快速部署服务,快速迭代。所以,第 3 次方案,我结合团队业务的特点选用了 Zadig,最终的实践效果是很不错的。
结语与展望
三段经历中,我们实际业务的现状都是采用物理机部署形式,所以都有一个共同的工作内容是将现有产品服务完成容器化部署的过程。这个工作会因为不同的业务架构有不同的技术挑战,比如数据管理需求,网络管理需求等。本文比较侧重测试环境管理方案的思考,在这一块没有展开讲。
粗看三种方案好像差不多,只是换了不同的开源工具?确实是这样。Devops 领域的工具链极其多,而如何选型并打磨成适合自身业务团队的实践方案是我认为比较关键的。
另外,从上述三种方案可以看到,我们构建的测试环境都是采取完全隔离的方案。但是,如果一个产品本身比较庞大,比如一套环境微服务几百个这样的量级,就还需要考虑资源利用率的问题。关于测试环境的复用,业界也有很多已经相对成熟的方案,比如 Service Mesh,多泳道等。后续如果有好的实践效果,再来分享给大家。
储培,上海,2022-11