研发效能 干货分享 | 支付宝生态可用性问题监控体系
蚂蚁和生态协同为用户提供服务,生态的形态包含:线下支付商家、三方小程序、H5、IOT 等。生态的可用性日益重要,要求我们第一时间发现生态的故障,尽早推进解决。本次分享涵盖生态监控的端到端链路,从告警生成、监控覆盖手段,到告警分析、等级定义,最后故障闭环、应急升级促进恢复。希望和大家一起探讨可用性监控的实践和未来发展。

宣敏敏 技术专家
主要负责支付宝生态可用性问题监控工作。擅长领域:小程序生态监控、支付稳定性监控、大促生态稳定性监控、生态告警分析、生态 X 故障体系等。2018 年加入蚂蚁,始终深耕在生态监控领域。
以下内容根据宣敏敏老师在 TesterHome 社区与支付宝质量技术主办的测试之美《支付宝生态质量保障》主题技术沙龙直播现场所讲内容进行精简整理,大约 3500 字左右。
背景
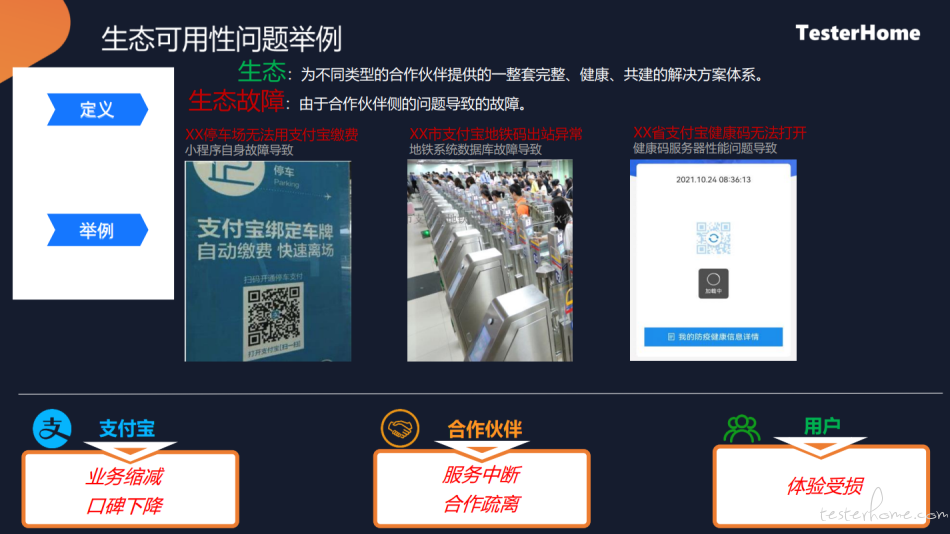
首先要定义一下什么是生态以及什么是生态故障。
生态是支付宝为合作伙伴提供一整套完整的、健康的共建的一些解决方案,当然建设方会有很多,比如支付宝、合作伙伴、然后合作伙伴可能会有较多的层级。
生态故障是由于合作伙伴侧的问题导致的故障,比如:
- 扫一扫付停车费,页面无法打开、车牌无法识别、小程序无法使用导致的缴费异常
- 使用支付宝坐地铁,扫码异常,导致无法出站
- 健康码一直处于加载状态,无法打开
当出现这些问题都会对相关方带来很多损失:
- 对于用户来讲,出行受阻,体验差
- 对于合作伙伴来讲,服务不可用,他所相关合作伙伴也会导致合作疏离
- 对支付宝来讲,也会出现业务下降、口碑下降
面临的挑战
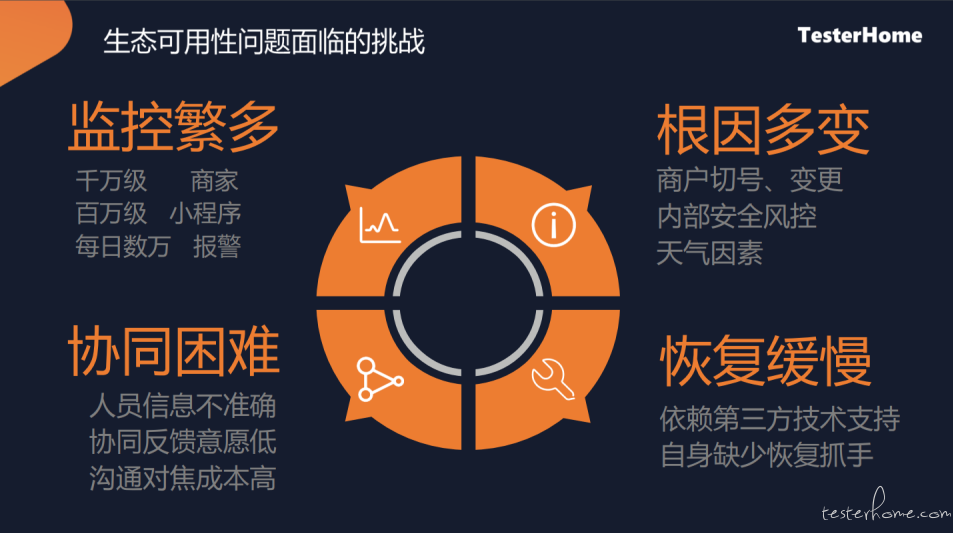
想要解决这些问题,同时也面临较大的挑战
监控繁多
支付宝、蚂蚁的合作伙伴有较多的千万级、百万级的量,在这么多的合作伙伴中如何确认是否存在问题,报警的监控预值应该怎么样去配置
根因多变
根因较多,存在各种各样的原因,比如:
- 商家切换了一个号码、商家变更中导致不可用
- 或安全风控方面的原因
- 天气因素导致的线路等问题,导致的用户无法使用
- 等等
协同困难
这么多商家出问题的时候,如何找到对应的人来解决,因为有些服务,可能是部署在商家自己的机房,或者自己的云服务上面,是没办法直接操作解决,只能找商家协同处理。
如何找到这些人,且其有意愿进行解决,还涉及了非常多的沟通对焦的成本
恢复缓慢
很多合作伙伴,非 7*24 小时,且人员较少,当出现问题时,如何快速协助解决,快速定位问题
如何有效的解决这些问题
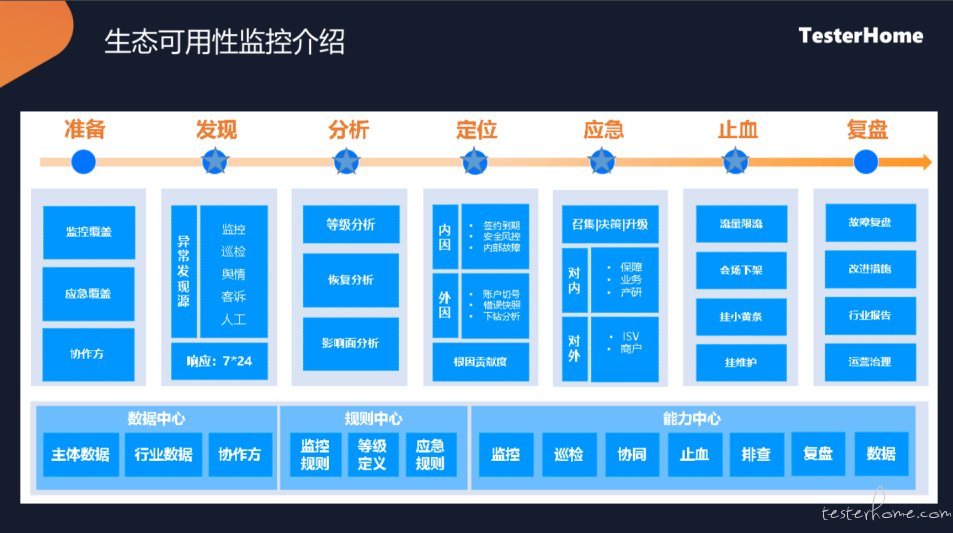
目前我们是基于可用性监控来协助解决这些问题的。主要分为以下几个步骤:
监控的准备
要看有哪些业务,商家,维度(比如说页面、小程序、门店等)是需要做监控的,在进行监控之前是需要提前梳理 清楚的监控的发现
要通过各种各样的手段去获取一些数据,通过数据上报、主动的去探测一下或者人工的操作去发现一些问题分析
分析问题的等级,当问题较多时,优先分析等级较高的问题,针对影响面比较低的,可能会放在后面进行处理。定位
可能产生的原因,能够自动识别出来,比如,安全的原因、账号切换的原因,将这些报错,受影响用户的一些贡献度信息定位出来,方便排查应急
当有相关的告警定位数据之后,就可以进行对内、对外的一些应急处理。对内主要是一些商务、值班的同学跟进;对外需要与商家、ISV 进行联系,找到对应的人处理问题止血
出问题的时候,需要想办法把影响降到最小,也有一些自动化的手段,比如在小程序挂个黄条提示用户、做限流、挂维护,将接三方的系统流量热度下降,影响面也可控一些复盘
对于每一个重大问题,都进行一个复盘。
这是整体的一个过程,接下来主要是从发现、分析定位和应急止血,这几个方面来给大家详细介绍
监控的方案

也可以通过一些手段,来有效的发现问题
日志监控:
比如说用户他打开某个健康码,报错、转圈或者白屏,是可以抓到这些相关数据的。用户在线下支付的每笔交易也是有相关日志的。
针对这些日制请求或者失败的量,我们会做一个实施监控看每分钟的报错量是怎么样的,或者交易笔数是怎么样的。(交易笔数下跌,对应的曲线也是明细下跌,很大概率是因为发生了一些问题)
证书监控:
https 证书,我们会实时进行监控,提前进行预警
离线监控:
少量用户报错或者随着用户的增长,服务器压力上涨导致报错数逐渐增加。
我们会基于天维度或者小时维度做一个长期的分析,对错误趋势不断上升或者交易笔数不断的下跌的场景进行识别。
巡检监控:
通过主动的方式,去检测问题。
在上线前、上线后,通过真机或模拟器的手段,自动化的定期的对页面进行巡检,检查页面是否白屏、弹窗或是一些其他的情况。当检测到这种异常情况后,也会进行预警。
不同的商户的笔数和错误数也是不一样的,通过这些监控的数据,如何准确将错误报警上报,我们这边是通过智能告警,主要看这个生态历史上的两种情况。
- 第一种是顺时波动,平时比较平稳,当出问题时,可能会分钟级的来回波动。
- 第二种是持续下跌,之前比较平稳,突然间下跌
- 还有一种错误数上升的情况,也是类似的只不是曲线是向上的。
智能告警
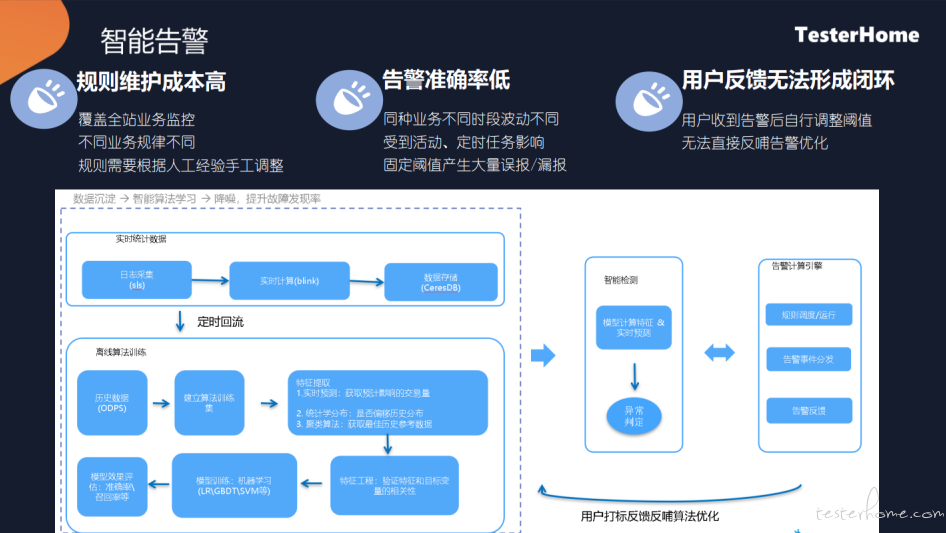
这是我们智能告警的一个实现方式,主要解决维护成本高的问题。因为大量的商户,不可能一个一个去手工调整他的预值,就算是手工设置的预值之后,准确率也会比较低,会有大量的漏报和误报,同时如果说手动设置之后,如果有人反馈告警不准,针对这个不准,怎样能够自行反馈和自行调整。
首先是一个实时的数据,我们会做一些实时的计算产生分钟级的一些指标,有这些指标之后,我们会在离线,事先算好他的他的一些特征,主要看他历史上的一些交易情况,在分钟级的这个点,有没有跌 0 或者怨的交易笔数的范围区间是怎么样的。范围确定之后,当前值不在这个范围内,或连续多少分都不在这个范围内,我们就会认为他是有问题的。
产生告警之后,会收到告警反馈,会有生态或者一些值班的同事去处理这些告警,如果这些不准的时候,会进行打标,打标后的数据会反哺算法,告知算法这个特征计算有问题,算法自动的做一个调节,从而使用准确率不断提升。
分析和定位
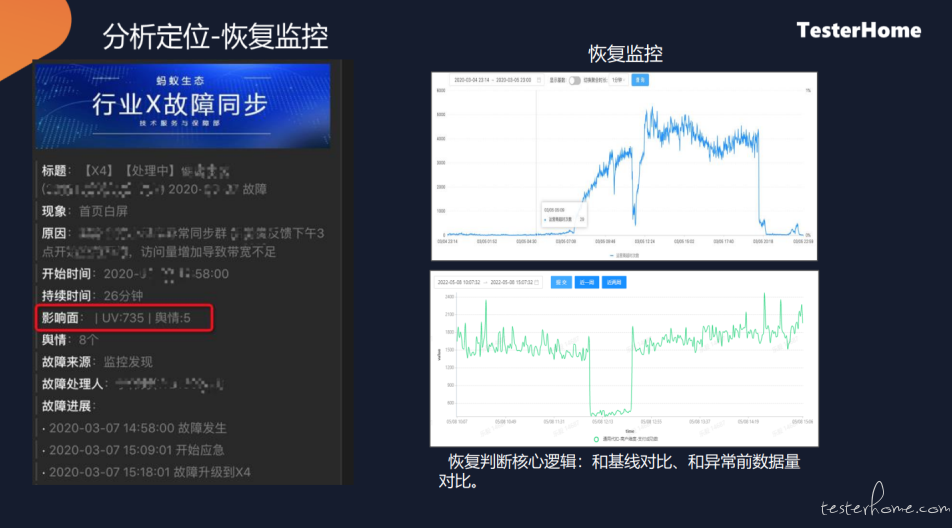
首先是恢复监控,当检测到一个下跌之后,要看是什么时候恢复的。
恢复的目的是通过报错的时长分析每一个应急以及可用率的计算,给出对应的提醒(比如: 目前已经恢复)。其实核心来讲,是跟历史的基线以及报错前的一个量去做的比对。
定义故障等级,不同的故障等级,跟进的时效以及升级的一些动作是不一样的。
大致等级计算案例:
首先定义每个业务出现不同问题的等级配置。
比如,公交的开卡或支付,有 5w 个用户出问题,是 X1 故障;1w 个用户出问题,就是 X2 故障。
当这些等级定义好之后,基于报警事件,能够自动计算他的影响量,进而得知对应的等级。平时错误数是比较低的,当出问题的时候,错误数明显上升,就会产生告警。根据分钟级面积进行计算,面积越大说明影响用户数越大。主要是根据这样的指标来进行计算等级的。
计算等级之后,告警的降噪
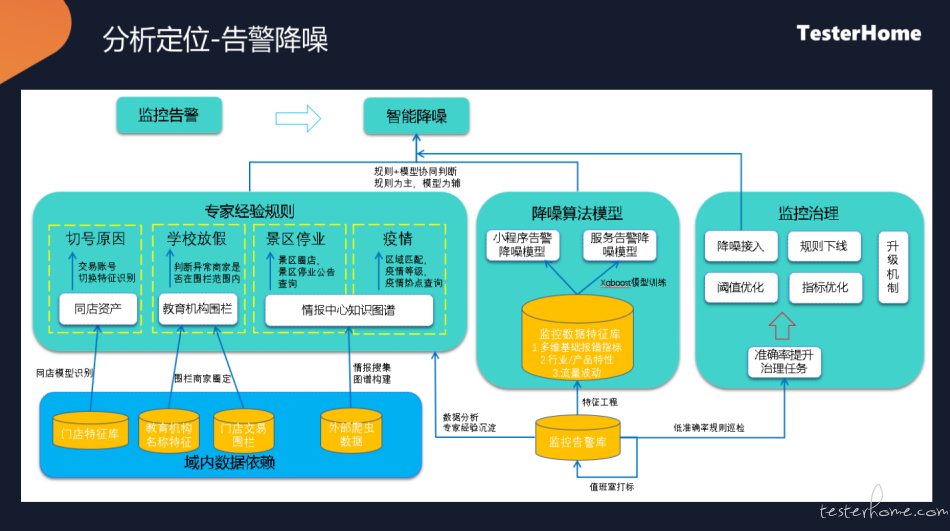
过滤哪些告警可能是一些不是可能性的、短暂的、抖动的性问题,需要将这些进行转异常或排除掉,进行告警降噪。
- 根据专家经验,根据一些信息或拿到外围的一些数据,分析合作伙伴可能是一个什么样的问题
- 降噪的算法,是从一个曲线上面来看的,报警数上升,但很快下降,针对这种情况,会进入观察
- 监控方面的治理,某些商户告警比较多,针对这个合作伙伴单独进行一个优化
根因的分析
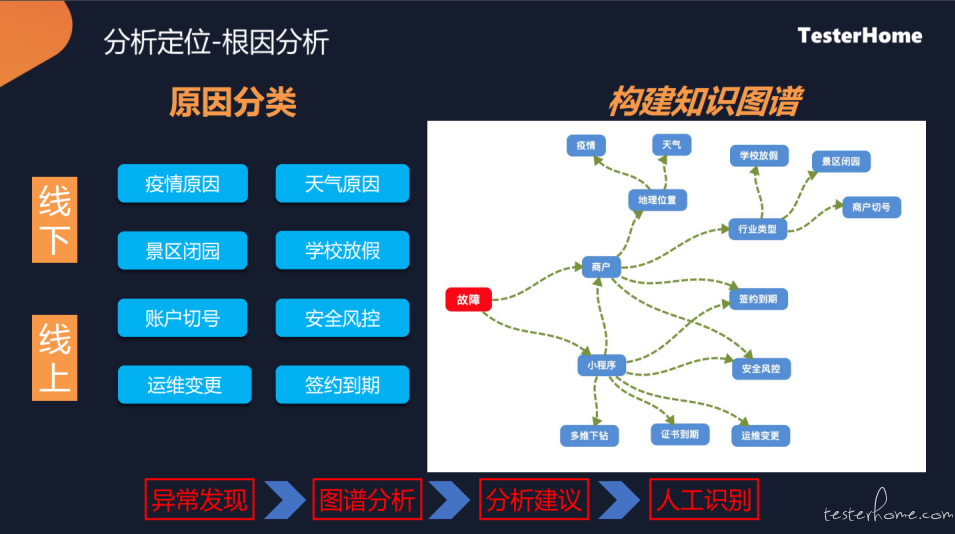
经过等级分析和降噪之后,还要识别出真实的原因。当然也不是每个原因都能够分析到,我们也在不断的探索这方面的场景。
主要分为线上和线上,不同情况也是不一样的,可能会识别到运维变更、切换分控,或线下放假,导致的一些交易波动。针对这种情况,可能是不需要进行应急处理。
识别上,我们会构建一个知识图谱,把每一个合作伙伴小程序,跟他的位置信息、证书、安全策略或其他的政策建立一个关系,当合作伙伴出问题后,会根据关系进行查询、分析。
应急止血
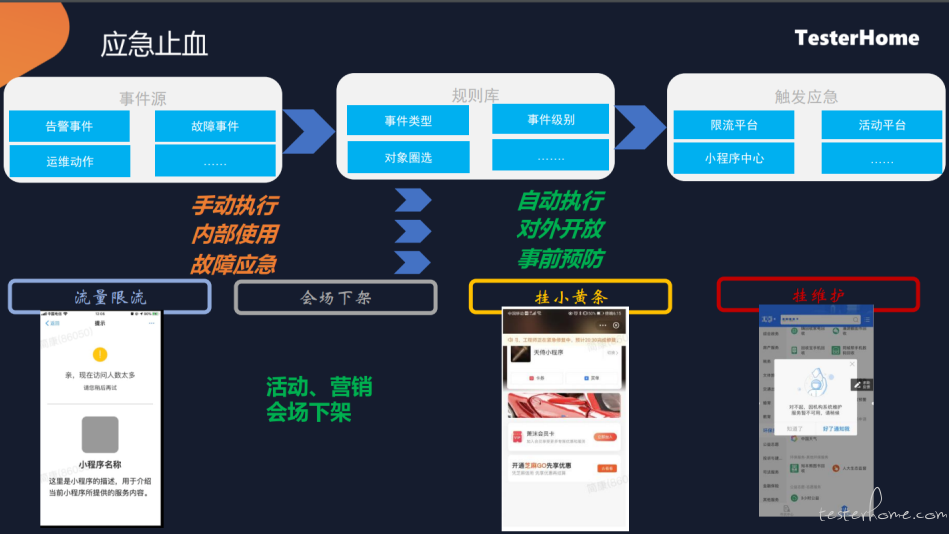
经过分析之后,最终是要恢复我们的故障,首先有一些自动化的应急恢复手段:
- 比如流量限制,我们识别到他的小程序当前报错比较多,那么我们会有一个限流措施,让用户看到一个统一的页面,来降低合作伙伴压力
- 第二种,就是会场下架,有些活动营销会场上面露出了一些服务,当出现问题后,服务无法访问就是报错,监控到后,我们会自动下架服务。
- 第三种,我们可能会挂个小黄条,会对用户有一个提醒,告知用户
- 还有一种,就是挂维护,用户点进去后,提示用户正在维护但可用,好了提通知我。
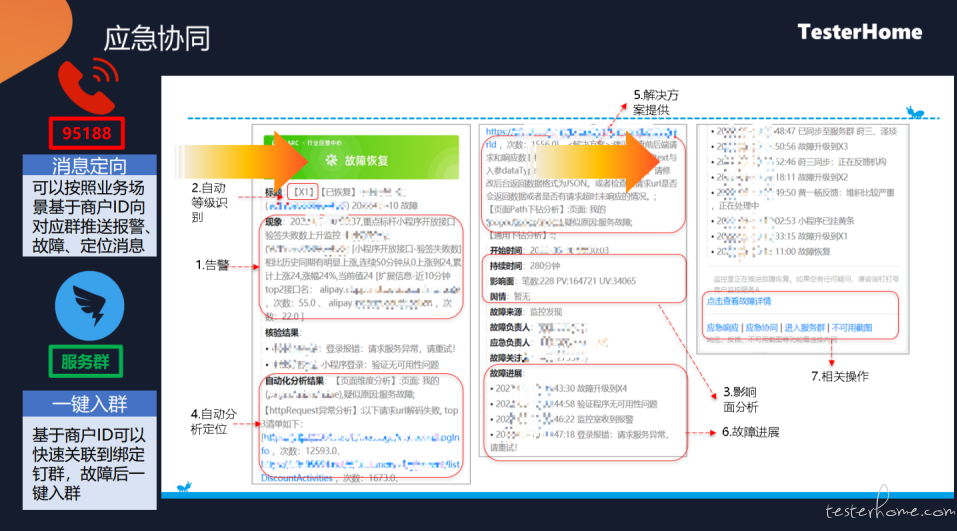
自动化应急以外,真正的恢复肯定要找相应的合作伙伴进行恢复。
在触答上,我们会基于合作伙伴 id,构建商户联系人的维护、钉钉服务群维护,当出现问题的话,会直接通过电话或在群里直接发送告警详细信息,找到对应的人。
成果和展位
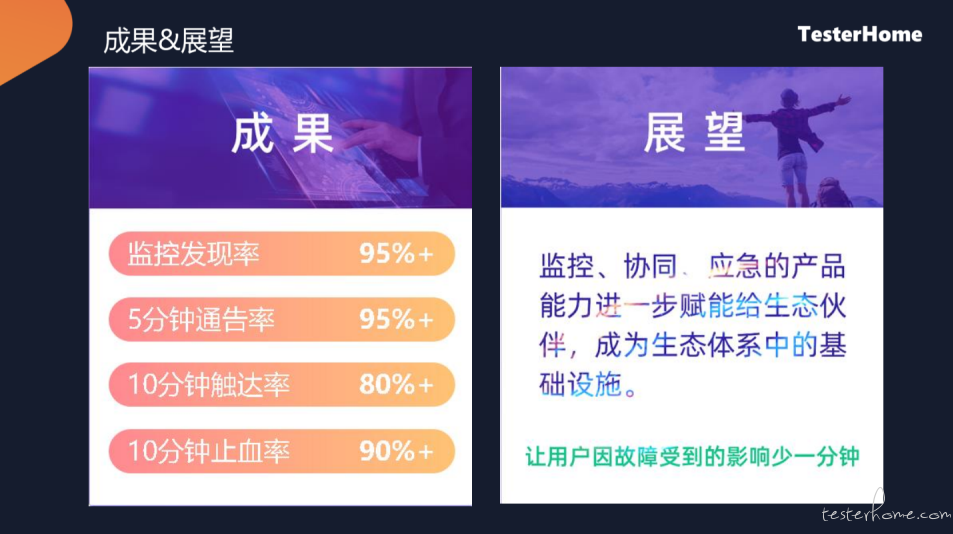
这个过程目前实际效果还是蛮好的,整体监控发现率是有 95%,5 分钟通告、10 分钟触 达、10 分钟止血,整体比例还是相对较高的。
最终我们想通过这些线上的这些监控、协同、应急的能力,赋能给我们的合作伙伴,最终让用户能够快速的、流畅的使用我们的服务。
问答时间
有些流量是因为商家上线活动导致的这个流量高峰,然后第二天这个流量就下去了,这种反复的活动波动还是很大的,这种监控误报是怎么来处理的?
因为搞活动会有很多用户,当出现大量用户无法进入的时候,大概率可能是报错了。
是需要能够识别出来这种情况的,并且能够找到对应的联系人进行处理,比如商家增加服务器、增加限流等等。
当监控识别出这种情况后:
在技术上,进行基线的识别,基线比较低,突然活动上来,进行一个基线的平移,比如说平时交易比较低,每分钟 10 笔、20 笔左右,来个了个活动,突然每分钟 100 笔,这个时候整个基线也会同步上移。
就能够在做恢复或等级判断的时候,不会出现太大的偏差。
刚有说到监控方案,有日式监控、证书监控还有这种离线和巡检,像证书还有巡检是如何做的?
巡检我们目前做的场景,主要是有几块:
第一块 http 的一个检测,商家他可能提供一个服务,H5 的页面或者说是某个接口,
- 正常情况下接口返回 200,如果返回了 404 或 500,我们就会认为这个接口可能是有问题的,我们会通过这样主动检测的方式巡检。
- 还有一种巡检就是打开这个页面,接口虽然返回的是 200,但页面就是报错的,我们会用真机或模拟器的方式,模拟用户打开这个页面,对一些关键页面或首页通过自动化的方式打开检测一下,通过一些 ocr 的识别,判断是否为白屏或弹窗,然后产生一个告警。
证书这块主要是针对 https 这个证书,是有手段可以拿到证书的倒计时时间的,只不过我们是用批量的方式看那些合作伙伴的网页访问量比较大的,定期进检测离到期时间还有多久,在到期之前我们会给他进行一个提醒
相关视频扩展,可直接在 TesterHome 视频号进行观看