
本文为「Dev for Dev 专栏」系列内容,作者为声网音频算法工程师 李嵩。
随着元宇宙概念的引入,空间音频这项技术慢慢映入大家的眼帘。关于空间音频的基础原理,我们做过一期科普视频 ——「空间音频背后的原理」,想要了解的朋友可以复制文末的链接查看。
本期文章,我们将主要讨论基于对象 (object-based) 的实时空间音频渲染,也就是如耳机等应用场景中,渲染对象为一个音源时的渲染思路与方案。

虚拟声是指利用空间音频技术合成的一路虚拟声源。
在现实生活中,人们可以利用双耳感知到真实声源的位置,所谓的虚拟声渲染,便是模仿真实声源到达我们耳朵的过程,使听者感受到虚拟声源在空间中的位置等信息。
渲染过程中,我们需要几个基础的信息来进行信号处理,比如:声源、房间的模型、声源和听者的位置、声源的朝向等等。在声源和听者之间没有阻碍物的情况下,声源发出的声音会直接到达听者的耳朵,我们把这个听到的声音叫做直达声。
在直达声到达后,声源从墙壁、地板、天花板或其他障碍物反射产生的反射声也会陆续到达听者的耳朵。这些反射一开始很稀疏,随着时间的推移会越来越密集,能量也会呈指数下降。通常,我们将一开始稀疏的反射称作早期反射,一般在 50ms 到 80ms 内;把该段时间后的密集反射叫做后期混响(具体的时间和房间大小等环境因素有关)。

前文描述的是声源在房间内通过空气传播到达人耳的过程,接下来我们讨论这一过程如何实现。考虑到声源经过空气到人耳的传递过程一般是线性的,如图一所示,因此对于渲染来说最简单的方法是卷积已知的单声道声源和一对双耳房间的脉冲响应 (Binaural room impulse response, BRIR)。

■图一:卷积 BRIR 获得双耳声
其中 BRIR 指的是在房间内从声源到人耳的双耳房间脉冲响应,包括了直达声和反射 (这里的反射包括了早期反射和后期混响)。我们可以将其理解成当声源是一个脉冲信号(比如拍手,发令枪发出的声音等)的时候,你听到的声音。正如我们前文所说,BRIR 与房间、声源和听者的位置有关。
图二所示是一对在某个房间内真实测量的 30° 水平角的 BRIR,其中蓝色和红色线分别代表左耳和右耳的 BRIR。我们可以清晰的看到在时域中的直达声、早期反射和后期混响部分。
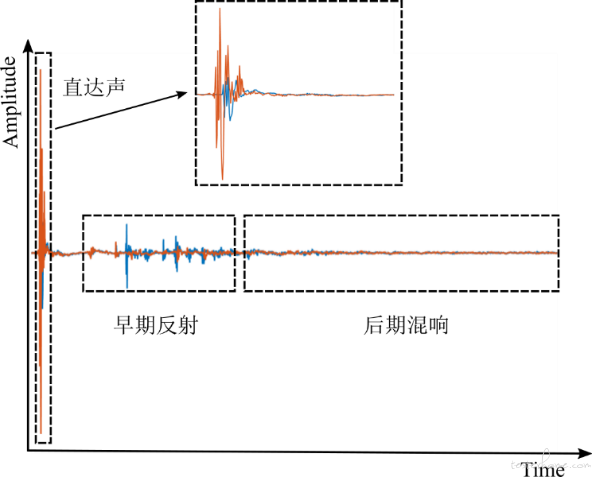
■图二:一对真实测量的双耳房间脉冲响应 (来源: University of Surrey, IoSR-Surrey 数据库)
那么 BRIR 如何获取呢?测量是一个真实并且准确的做法,尤其是对于现实增强 (AR) 的场景而言。但即使在不考虑个性化的情况下,在每个房间借助人工头来真实测量所有可能位置的 BRIR 都是不现实的。
另外 BRIR 的长度和房间的混响大小有很大关系,且实时卷积很长的 BRIR 需要耗费很大的算力。因此通常会使用合成的方法来模拟真实的 BRIR。
1)直达声的合成
BRIR 的第一部分是直达声的脉冲响应。直达声的合成可以通过卷积声源和头部相关脉冲响应 (Head-related impulse response, HRIR) 来获取。HRIR 是头部相关函数 HRTF 的时域表达。
关于 HRTF 相信大家已经有所了解,它表示的是声源到人耳的传递方程,但并不包含反射 (早期反射和后期混响) 部分。也就是说,如果只是用 HRTF 去渲染的一个声源,我们所在的虚拟听音场景是无反射的场景,类似消声室,雪山顶等特殊场地。

■图三:直达声部分渲染
图三为直达声部分的渲染链路,包括声源朝向的渲染、随距离改变的声压、空气衰减的模拟,和一对指定方向的 HRTF 滤波。这里的每一个模块在之前的文章中都有介绍过 (历史文章详见文末拓展阅读)。
在实时音频处理中,考虑到 HRIR 的长度,一般不会在时域上直接进行卷积,而是在频域上通过快速傅里叶变化 (FFT) 进行。当声源的位置发生改变时,就需要切换使用对应的 HRIR。为了防止切换 HRIR 时产生杂音,前一个和后一个的 HRIR 会进行类似淡入淡出操作。
如果 HRIR 对应的采样点不是很密集,则需要在渲染时进行实时插值来获取对应方位的 HRIR。当然也可以先进行离线插值直到足够密集为止 (小于 Just noticeable difference),在实时渲染的时候就可以直接选择离目标位置最近的 HRTF 来使用。
这样一来可以减少实时插值带来的算力,但需要存储的 HRIR 的包体积会变大。因此需要在 HRIR 存储体积和实时插值的算力间进行取舍。
2)反射的合成
BRIR 的第二部分是早期反射的脉冲响应。早期反射对音色,声源定位等有着很大的影响。由于早期反射比较稀疏,每个早期反射会被当作一个虚拟声源。这些虚拟声源的位置可以通过镜面法、光线追踪法或者数值求解等方法得到。
镜面法是一种比较省算力且相对直观的方法,但一般只适用于墙面光滑的情况,其无法模拟由于墙面不光滑引起的散射场景。光线追踪法可以模拟反射和散射场景,但声线方向以及数量的选择需要做更为仔细的考虑。在模拟低阶早期反射时,算力会比镜面反射要大。数值计算的精确度是最高的,但是其计算复杂度很高,适用于做线下模拟和仿真。
在实时计算早期反射的时候,考虑到算力问题,一般我们会精确计算 1-2 阶早期反射。这里的阶数是指和墙面经过几次碰撞,比如一阶反射是指声源和墙面经过一次碰撞到达人的耳朵。当这些早期反射的位置计算出来后,需要对每一个反射做和直达声一样的处理,包括反射声源的朝向,和距离有关的声压和空气衰减模拟,以及对应的 HRTF 滤波。
需要注意的是,由于每个反射到达人耳的时间不同,需要计算反射到达人耳相对于直达声的延迟时间。如果按照严格的物理意义,直达声也需要包括一段由声源到达人耳的延迟。
假如在一个虚拟场景,声源离听者 100 米,那么需要额外引入大概 291 毫秒的延迟。这样处理的话,虽然符合了物理含义,但是额外增加了延迟,并且这段直达声的延迟对空间感没有任何帮助。因此反射的延迟只会考虑相对于直达声到达人耳的延迟。
另外,由于反射声源是经过墙壁的反射/散射造成的,需要模拟墙壁反射/散射造成的能量衰减。要真实的模拟这一个音效,就要知道墙面材料等房间信息。

■图四:早期反射的渲染
生成早期反射的大致流程由图四所示。图示是将每一个早期反射都进行了单独处理,最后生成双耳声的时候,每一个反射都经过对应的 HRTF 滤波。另外一种方式是先合成早期反射的脉冲响应,当然长度会随着房间增大而增大,但最后声源只需要进行一次和早期反射脉冲响应的卷积。
3)后期混响的合成
**
**
BRIR 的最后一部分是后期混响。需要注意的是所有的混响部分都可以像计算早期反射一样进行计算,但是计算高阶早期反射需要很大的算力,并且我们人耳对高阶反射所在的位置不敏感,因此我们不需要精确的计算高阶反射,也就是多级经过墙面反射/散射的声波的具体位置。
通常情况下,我们可以用人工混响器来渲染生成后期混响。比较常见的人工混响器有:全通滤波器、反馈梳状滤波器、全通滤波器和梳状滤波器的组合滤波器等。在混响器中,反馈延迟网络是一种比较常见也是性价比很高的实现方法。
4)实时空间音频渲染流程
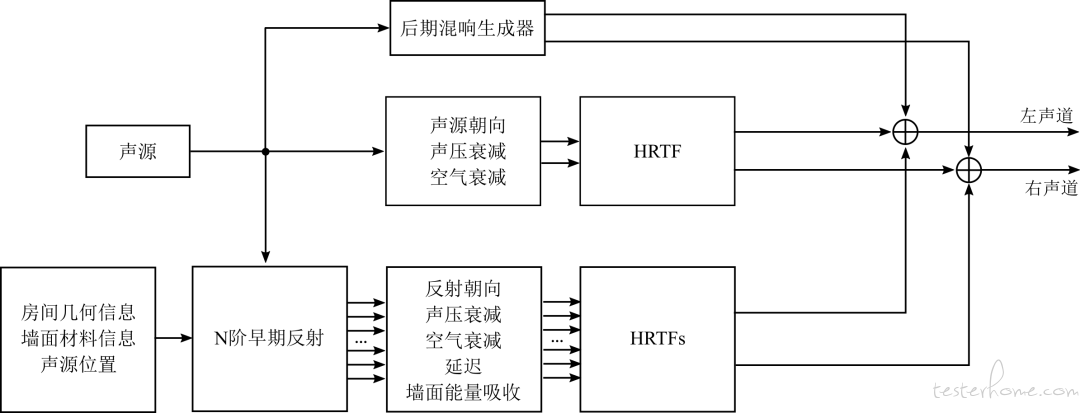
■图五:双耳声渲染过程
整体的实时空间音频渲染流程图如图五所示。要注意的是,其中每一个模块都可以设计的很复杂,也可以很简单。举例来说,每一个房间都是形状各异,但有时候为了简化计算复杂度,会用一个简单的长方体的房间模型来代替。空气衰减的模拟可以用 FIR 滤波器来实现,但是在实际应用中,会用低阶的 IIR 滤波器来逼近结果从而节省算力。
这当中的核心模块如 HRTF 也是一直很热门的研究话题。HRTF 是高度个性化的,如果使用了非个性化 HRTF,可能会出现定位不准确,前后混淆的现象。虽然真实测量的个性化 HRTF 准确度最高,但是在实际应用中,测量 HRTF 是不现实的。在实际应用中,基于耳朵照片的个性化 HRTF 预测或者个性化 HRTF 选择会是一种更为合适的方式。
除了 HRTF 的个性化问题外,HRTF 在远场 (一般来说声源和听者的距离大于 1 米) 时候,频谱和距离无关。也就是说在同一个方向下,2 米的 HRTF 的频谱和 3 米的 HRTF 频谱是一样的,只是幅度不一样了。
然而 HRTF 在近场 (一般来说声源和听者的距离小于 1 米) 的时候,频谱会随着距离发生巨大变化。为了更加真实的渲染近场声源的效果,需要用远场 HRTF 通过外插的方法来合成近场 HRTF。

当音源不是一个对象,而是一个声场或者是有大量的对象需要同时被渲染时候,上述的方法就不太适用了,可以用 Ambisonic 的方法进行实时渲染。
另外抛出一个问题, 假设我们正确地渲染了基于某个房间的空间音频,我们就会有很好地沉浸式体验了吗?我们会在之后的文章聊一聊如何使用 Ambisonic 的方法进行空间音频的实时渲染以及关于空间音频的主观听感,请大家持续关注 Dev for Dev 专栏。